The total system will consist of 4096 chips, which will be organized into 16 clusters each with 8 processor boards. Each board will carry 32 processor chips. Total power consumption will be around 40-50 kW. Thus, both the power consumption and the physical size of GRAPE-6 would be several time larger than those of GRAPE-4 (4 clusters, 10 kW). The difference in size is essentially to deal with the increased heat dissipation.
Let us now consider the communication network. The design goal of
GRAPE-6 is to achieve a reasonable performance for the simulation of
globular clusters with 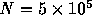 at the full-size
configuration. This implies that the data transfer speed between
GRAPE and host must be at least 2 GB/s, and that
at the full-size
configuration. This implies that the data transfer speed between
GRAPE and host must be at least 2 GB/s, and that 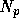 must be less
than 1000 at the maximum.
must be less
than 1000 at the maximum.
At the level of the cluster, different clusters calculate the forces on different particles, but from the same set of particles. Therefore, all clusters must have a same image of j particles (particles stored in the off-chip memory). This implies we need different requirements for the data transfer for j particles and that for i particles. For j particles, data must be broadcasted and the transfer speed to each box must be around 1.6 GB/s. For i particles, different clusters require different data, and necessary bandwidth is around 100 MB/s for a cluster.
Within one cluster, different chips calculate the forces on the same set of particles, but from different particles. Thus, the partial forces calculated on pipeline chips must be summed up through a reduction network. Also, data for i particles must be broadcasted. For j particle, each cluster should have around 1.6 GB/s. Therefore, each board must accept around 200 MB/s of data stream.
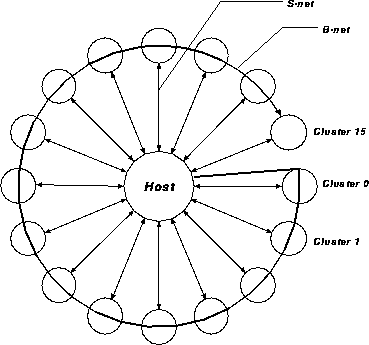
Figure 3: The overall structure of GRAPE-6 system
Figure 3 shows one possible design. In this figure, 16 clusters are connected to the host computer through two separate networks. One is the broadcast link (B-net), which connects host and other 16 clusters in a one-dimensional, one-directional communication path. The other is a star-type network which directly connects each cluster to the host computer (S-net). B-net is used to broadcast the data to be written to the particle memory, while S-net is used to read/write the registers in the pipeline chip.
For the link between clusters and/or boards, we plan to use physical layer chipset of FibreChannel or SCI, which can operate at the speed of 100 MB/s.