How GRAPE-6 chip will look like? Here, we briefly discuss the difference between GRAPE-4 processor chip (the HARP chip) and GRAPE-6 chip. The changes are introduced to make full use of the advance of the VLSI technology.
The advance in technology has two outcomes. The first is the
increase in the available number of transistors on a single chip.
The HARP chip was fabricated using the 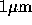 technology,
while the
technology,
while the 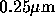 technology will be used for
GRAPE-6. Roughly speaking, we can use 16 times more
transistors. Secondly, switching delay of the transistor is
improved roughly in proportional to its physical size, which we
hope to give us around a factor of four increase in the clock
cycle. Thus, we expect that GRAPE-6 chip will have 64 times more
processing power than GRAPE-4 chip, by means of larger number of
pipelines and higher clock speed.
technology will be used for
GRAPE-6. Roughly speaking, we can use 16 times more
transistors. Secondly, switching delay of the transistor is
improved roughly in proportional to its physical size, which we
hope to give us around a factor of four increase in the clock
cycle. Thus, we expect that GRAPE-6 chip will have 64 times more
processing power than GRAPE-4 chip, by means of larger number of
pipelines and higher clock speed.

Table 1: Comparison of pipeline chips for GRAPE-4 and GRAPE-6
The power consumption is still relatively low, because of the shrink in the physical size of the transistors and the reduction in the supply voltage.
The increase in the number of pipelines and clock period of the
pipeline chip, however, forced us to reconsider the architecture
of the chip. The pipeline chip of GRAPE-4 (HARP chip) implemented
only the force calculation pipeline. GRAPE-4 has a separate
pipeline to evaluate the predictor polynomials for the position
of particles, so that it can be used with individual timestep
algorithms (for details, see [MTES97]). This
pipeline was implemented in another chip (PROMETHEUS chip). A
PROMETHEUS chip supplied the data of particles to 48 force
calculation pipeline chips. The data transfer bandwidth between
PROMETHEUS and HARP was 256 MB/s. The number of HARP chips
connected to a PROMETHEUS chip was chosen so that we can achieve
a reasonable efficiency for individual timestep algorithm.
The number of particles for which the gravitational
force are calculated in parallel, 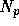 , must be relatively
small, since the number of particles that can be integrated in
parallel is small (otherwise the individual timestep algorithm
would be useless). For
, must be relatively
small, since the number of particles that can be integrated in
parallel is small (otherwise the individual timestep algorithm
would be useless). For 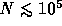 ,
, 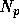 must be less than
100.
must be less than
100.
If we use a similar architecture for GRAPE-6, a rather serious
problem arises: we need a very high total memory bandwidth. With
GRAPE-6, we can increase 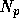 to around 500. Even so, the
required memory bandwidth is about 40 times higher than that of
GRAPE-4, since the peak speed of GRAPE-6 will be 200 times as
that of GRAPE-4.
to around 500. Even so, the
required memory bandwidth is about 40 times higher than that of
GRAPE-4, since the peak speed of GRAPE-6 will be 200 times as
that of GRAPE-4.
There are a number of different approaches to achieve this high memory bandwidth. We analyzed several of them and reached the conclusion that a tightly-coupled memory-processor chip pair is, at present, most cost-effective solution. If we can integrate the memory and pipelines into a single chip, it would be an even better solution. However, as of late 1997, the logic-memory integration still has too large impact on the density and performance. In a few years, advance in the process technology might make the logic-memory integration a practical option.
If we place memory chips and a pipeline chip physically close, it is
not very difficult to achieve a high bandwidth. We can use high clock
frequency without much problem. Of course, we have to use advanced
packaging technologies such as MCM (multi-chip module), which was used
in GRAPE-4. Figure 2 shows an example
design. Here, a multi-chip module contains two GRAPE-6 chips, each
connected to two SSRAM (Synchronous Static Random Access Memory)
chips. For the connection between memory and pipeline chips, we use a
high speed (125 MHz) clock, to achieve the data transfer speed of
around 1.2 GB/s. Two GRAPE-6 chips share a common I/O port, through
which they are connected to the communication path to the host. For
the I/O port, we plan to use one port with 64-bit width and 25 MHz
data rate (200MB/s). The physical wire length for the I/O port will be
considerably longer than that of the port to the memory. Therefore it
is important to keep both the clock frequency and number of wires
(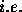 , the I/O bandwidth) as low as possible.
, the I/O bandwidth) as low as possible.
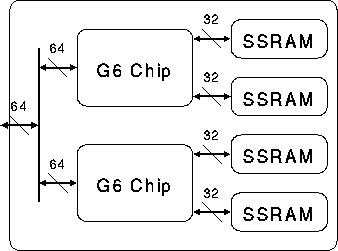
Figure 2: The GRAPE-6 processor module