There are two different ways to use multiple host GRAPE-6 system. In the first way, each GRAPE-6 unit is connected to its host, and communicates only with its host. The host computers (or multiple program threads if we use an SMP host with multiple GRAPE-6 units) communicate with each other through some method, such as message-passing library API (MPI, PVM etc) or through shared memory. In this case, no additional functions are needed to use multiple GRAPE-6 systems. Each host takes care its GRAPE-6, through standard GRAPE-6 API.
This method is simple, but has potential performance problem. Consider
the simplest case where we use two hosts and two GRAPE-6 systems. We
divide ![]() particles into two subsets each with
particles into two subsets each with ![]() particles, and
let host 0 take care of subset 0 and host 1 subset1. For simplicity,
we consider the shared-timestep, direct-summation method. (Note that
for the case of the tree method on distributed-memory processors this
configuration is well suited.)
particles, and
let host 0 take care of subset 0 and host 1 subset1. For simplicity,
we consider the shared-timestep, direct-summation method. (Note that
for the case of the tree method on distributed-memory processors this
configuration is well suited.)
At each timestep, we need to calculate the forces on all particles. We can do this by sending all particles to GRAPE-6 through g6_set_j_particle. However, since each host knows about only its subset, it can only send half of the particles. In order to send the other half, two host computer need to exchange their data.
This exchange, can of course be done through, for example, MPI call
such as MPI_send_recv. However, it should be noted that this
is time-consuming, in particular we have more than two hosts. if we
have ![]() hosts, one host need to receive data from all
hosts, one host need to receive data from all ![]() hosts. Therefore, for
hosts. Therefore, for ![]() particles, the data communicated is
particles, the data communicated is
![]() . In other words, the data to be sent to one host increases, albeit slowly, as we increase the number of
processors. By increasing the number of processors, we expect to
speedup the overall calculation. Both the work of time integration
and that of the force calculation are indeed distributed to
. In other words, the data to be sent to one host increases, albeit slowly, as we increase the number of
processors. By increasing the number of processors, we expect to
speedup the overall calculation. Both the work of time integration
and that of the force calculation are indeed distributed to ![]() processors and can be done in
processors and can be done in ![]() time, compared to the case of 1
processor. However, the communication time remains essentially
constant.
time, compared to the case of 1
processor. However, the communication time remains essentially
constant.
This situation is the same in the case of the individual timestep.
For GRAPE-6, we implemented a way to avoid this communication bottleneck, which we describe in the next section.
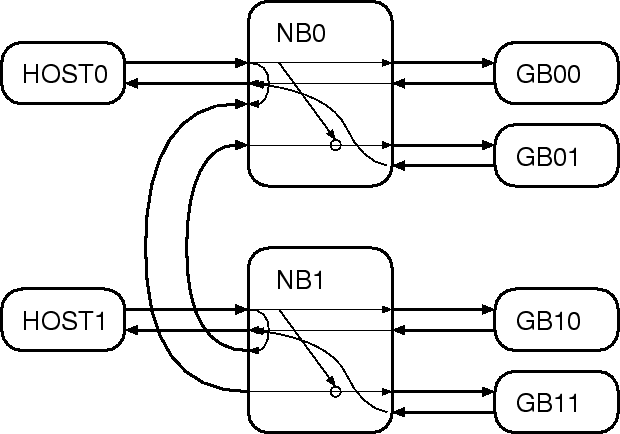
Figure 1 show the conceptual hardware setup for two-host, 4-GRAPE system. 4 GRAPE boards are connected to two hosts through two network boards (NB). Two network boards are connected to each other.
The NB, in this case, operates in two different
mode. In the first mode, which we call the normal mode, or N-mode, it
broadcast the data received from its host to all GRAPE boards. This
mode is used to send ![]() particles to GRAPE boards. Host 0 broadcasts
the data to GRAPE 00 and 01, and host 1 to GRAPE 10 and 11
particles to GRAPE boards. Host 0 broadcasts
the data to GRAPE 00 and 01, and host 1 to GRAPE 10 and 11
In the second, ``multicast'' mode (M-mode), an NB sends the data received from its host to GRAPE board x0, and the data received from the other NB to GRAPE board x1. Each NB simply send the data received from its host to the other NB. Thus, effectively, in this mode host 0 broadcasts the data to GRAPE 00 and 10, and host 1 GRAPE 01 and 11. In other words, the direction of the broadcast is diagonal to that in N-mode.
We use N-mode to send ![]() -particles and M-mode to send
-particles and M-mode to send ![]() -particles.
-particles.
In this way, we can eliminate the communication between the hosts. GRAPEs x0 have subset 0 and x1 subset 1. Thus, GRAPE xy calculates the forces from subset y to subset x.
By adding more NBs, we can scale up this configuration to larger one, such as 4-host, 16-GRAPE system or 8-host, 64-GRAPE system. For practical reasons, what we have currently in Hongo site is multiple 4-host, 16-GRAPE systems.
A 4-host, 16-GRAPE system can be used in 3 modes. In the first mode,
we use 4 hosts independently, each with 4 GRAPE boards. In this case
NB always works in N-mode. Both ![]() and
and ![]() particles are broadcasted
to all boards. However, different chips take care of different
particles are broadcasted
to all boards. However, different chips take care of different ![]() particles.
particles.
In the second mode, we use the whole system as one unit. In this
case, we switch to M-mode when sending ![]() -particles, and switch back
to N mode to send
-particles, and switch back
to N mode to send ![]() -particles. In M-mode, 4 GRAPE boards
connected to one NB receive data from different hosts. Which board receive data from which host is
rather complex, but the point is that different boards receives data
from different data, and therefore 4 GRAPE boards combined receive
data from ALL hosts.
-particles. In M-mode, 4 GRAPE boards
connected to one NB receive data from different hosts. Which board receive data from which host is
rather complex, but the point is that different boards receives data
from different data, and therefore 4 GRAPE boards combined receive
data from ALL hosts.
In the third mode, we can use two hosts combined, to have 2-host, 8-GRAPE system. In this case, M-mode is a bit modified so that two GRAPE boards are grouped together to receive data from one host.
In the next section, I describe the library functions to switch between two mode, and give simple example.