The idea of building special-purpose computers for specific numerical problems is not new. In fact, the very first digital electronic computers (ABC and ENIAC) were designed to solve specific problems. However, the designers of early computers found that their machines could be used for a much wider range of problems, and thus the evolution of the programmable general-purpose computer started.
At the time when even the largest supercomputer did not have a fully parallel multiplier, it did not make sense to design a special-purpose computer. Any computer, either special- or general-purpose, consists of arithmetic units (mainly multipliers), control logic and memory. A special-purpose computer might have simpler control logic or smaller memory than general-purpose computer. However, if the cost of the arithmetic unit itself is a fair fraction of the total cost of the machine, we cannot gain much by trying to reduce the cost of the rest of the system. Of course, if one could simplify the arithmetic unit itself, as in the case of machines for Ising models [3,9], a large gain was achieved.
This situation, however, has changed completely, as we've seen in the previous section. To give a concrete example, let us discuss the astrophysical N-body problem and our GRAPE (GRAvity PipE) hardware specialized for that problem. The master equation for the gravitational N-body problem is given by:
where 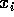 and
and  are the position and mass of the particle with
index i and G is the gravitational constant. The summation is
taken over all particles (typically stars) in the system under study.
are the position and mass of the particle with
index i and G is the gravitational constant. The summation is
taken over all particles (typically stars) in the system under study.
The number of particles N varies widely depending on what kind of systems are studied. A small star cluster like Hyades might consist of several thousand stars. Globular clusters typically contain one million stars, and galaxies hundreds of billions of stars. In the case of galaxies, it is impossible to model them in a star-by-star basis, and we model the distribution of stars in the six-dimensional phase space with much smaller number of particles.
If N is larger than several tens, the calculation cost of the right hand side of equation (1) dominates the total calculation cost. If N is very large, we could use sophisticated algorithms such as the Barnes-Hut treecode[1], FMM[4], or the particle-mesh method. However, with treecode or FMM, the direct evaluation of gravitational interaction between near-neighbor particles still dominates the total cost. Even in the case of the particle mesh method, if we want high accuracy, near-neighbor interaction must be calculated directly.
Let us assume that we have at hand a modest number of processors, or more simply arithmetic units, to solve this problem. The general-purpose approach can be described as follows. First we build a complete programmable computer around each of the arithmetic unit and then connect them with some communication network. Then we develop the program for this parallel computer.
Since we know that almost all computing time is spent on the calculation of the interaction, we can take an alternative approach. In this approach, we use one arithmetic unit (or small fraction of the arithmetic units available) to build programmable computer(s), and use the rest only for the force calculation. In principle, those arithmetic units used for the force calculation could be programmable computers. However, since we decided to use them only for the force calculation, it's much easier and cheaper to organize them into pipeline processor to calculate the force between particles. If we have more processors than needed to build one pipeline, we can use them to build multiple pipelines. If the number of the pipelines is small, they can just be connected to the general-purpose processor (we call it ``host computer'' here and hereafter) independently. Since the host computer is a rather simple scalar computer, it's relatively easy to write softwares for it. This is the basic idea of our GRAPE systems, shown in figure 3. Figure 4 shows the force calculation pipeline.
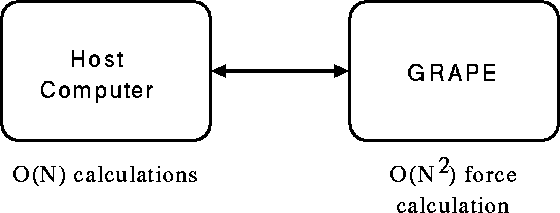
Figure 3: The basic architecture of GRAPE
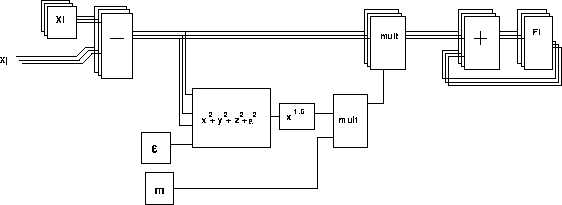
Figure 4: The force calculation pipeline
The theoretical gain of this kind of architecture is huge, in
particular when the special-purpose pipeline unit is implemented in a
custom LSI (either gate array, standard cell or full-custom
design). The reason is that we can actually use almost all of the
available transistors on a chip to implement floating point arithmetic
units. To give an idea, the GRAPE-6 processor chip which we completed
in 1999 contains more than 300 arithmetic units. The physical size
of the chip is about 11 mm by 11 mm, with 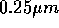 technology. Compare this number with just two arithmetic units of the
latest Intel processors implemented using
technology. Compare this number with just two arithmetic units of the
latest Intel processors implemented using 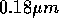 technology.
technology.
Another important advantage is that it is easy to utilize large number of pipelines. There are two ways to parallelize the force calculation. One is just let different pipelines calculate forces on different particles. In this case, these different pipelines can share the memory unit which provides the data of particles which exert the force. The other possibility is let different pipelines calculate the force on one same particle, but from different subset of particles in the system. By combining these two ways, we can construct a system with thousands or even tens of thousands of pipelines, and still enjoy pretty high actual performance.
Obviously, these advantages comes from the nature of the problem
itself. In astrophysical N-body problem, each particle interacts with
all other particles in the system (or, in the case of treecode or FMM,
large number of neighbor particles). Thus, the calculation cost is
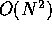 , while data transfer between the memory and processors can be
reduced to
, while data transfer between the memory and processors can be
reduced to  .
.
Our GRAPE project is not the only project to develop special-purpose computers for scientific simulations. As mentioned above, there were machines for Ising model simulations. In addition, Lattice QCD calculation has long and impressive history of highly successful specially-designed computers (see [10]). Also, there were various machines developed for molecular dynamics (MD) simulation, which is rather similar to astrophysical N-body simulation (for an overview see Makino and Taiji[6]).
These special-purpose computers can be classified into two categories. One is programmable parallel computers with various optimizations for specific problems. For example, if we do not need much memory, we can replace the DRAM main memory with a few fast SRAM chips, thus reducing the total cost by a fair factor and at the same time improving the performance. If we do not need fast communication, we can use rather simple network architecture. If we do not need double-precision arithmetic, we can reduce the number of bits. All machines for Lattice QCD and many for MD adopted this approach.
The other approach is to develop ``algorithm oriented'' processors similar to that of GRAPE. All machines for Ising model and some machines for MD took this approach. The Delft Molecular Dynamics Processor (DMDP) is one of the earliest. It had a force calculation pipeline very similar to those of GRAPE hardwares (see figure 4). However, there is one rather important difference. In our GRAPE project, we developed the force calculation pipeline only, and then connect it to a workstation. On the other hand, with DMDP the designers built everything themselves. Things like the time integration and analysis of the simulation result were done on hardware pipelines designed for them.
The obvious advantage of the DMDP approach was that its performance is not limited by that of the general-purpose host computer. Thus, impressively high performance was achieved (more than 100 Mflops in early 1980s). However, there are several disadvantages. The most important one is the loss of the flexibility to use the system for wide range of problems. With GRAPE, all data is on the host at any time during simulation. Thus, we can do whatever analysis on the data we like. We also can change time integration method. We can even add particle-particle interactions different from the gravity, as far as they are not too expensive. This kind of flexibility allowed us to study wide variety of astronomical objects.
A second disadvantage of the DMDP approach is that hardware becomes more complex simply because hardwares for operations other than the force calculation must be developed. However, at the time of the design of the DMDP, their choice was probably inevitable, since there were no workstations or PCs yet. The cheapest computers with reasonable performance for floating-point operations were minicomputers, whose price was much higher than the budget of the entire DMDP project.
As we stated above, there were many projects to develop special-purpose computers. Those documented in the literature are mostly successful projects. At the least they have produced working machines. However, there have been many more not-well-documented projects. Large fraction of them faded out without producing a working machine. In the following, we list what we think are the typical cause of the failure of a project to develop special-purpose computers. This list is by no means comprehensive, but may be of some help to those who interested in building their own machine.
In the next section, we describe GRAPE-6, which is currently under development, as one example of what can be done with the special-purpose approach.
