The GRAPE-6 system will consist of a host computer and 12 clusters. Each cluster has two I/O ports, one for local communication and the other for multicast through clusters. The multicast network is necessary to implement the individual timestep algorithm efficiently, but in this paper we do not discuss the details, and concentrate on a single cluster. Figure 5 shows the overall structure of the GRAPE-6 system.

Figure 5: Overall structure of GRAPE-6 system. Eight clusters are shown.
One cluster has one host-interface board (HIB), five network boards (NB), and 16 processor boards (PB). Each NB has one uplink and four downlinks. Thus, 16 PBs are connected to the host through two-level tree network of NBs (see figure 6). HIB and NB handles the communication between PBs and the host.

Figure 6: A GRAPE-6 cluster. First four PBs are shown. Other 12 PBs and
interface to the multicast network are omitted.
The PBs perform the force calculation. Each PB houses 16 GRAPE-6 processor chips, which are custom LSI chips to calculate the gravitational force and its first time derivative. Figure 7 shows the photograph of a PB. Two processor chips and four memory chips are mounted on a daughter card, and eight daughter cards are mounted on a processor board. Three large chips on board are the FPGA chips for the reduction network.

Figure 7: The GRAPE-6 processor board.
A single GRAPE-6 processor chip integrates six pipeline processors for the force calculation, one pipeline processor to handle the prediction, network interface and memory interface (see figure 8). One force pipeline can evaluate one particle-particle interaction per cycle. With the present pipeline clock frequency of 88MHz, the peak speed of a chip is 30.1 Gflops. Here, we follow the convention of assigning 38 operations for the calculation of pairwise gravitational force, which is adopted in resent Gordon-Bell prize applications. GRAPE-6 calculates the time derivative, which adds another 19 operations. Thus, the total number of floating point operations for one interaction is 57.

Figure 8: The GRAPE-6 processor chip.
Each pipeline processor of GRAPE-6 calculates the force on eight particles simultaneously, using the virtual multiple pipeline (VMP) architecture introduced with GRAPE-4. In addition, six pipelines in one chip calculate the forces on six different sets of eight particles. Thus, one chip calculates the force on 48 particles. This architecture reduces the required memory bandwidth per chip drastically. The data stored for one particle is 64 bytes. Therefore, if six pipelines require different data, one chip requires 384 bytes per cycle, or 33.8GB/sec of the memory bandwidth. In our architecture, the bandwidth requirement is reduced by a factor of 48 to 0.7 GB/s, since the same data is reused 48 times to calculate force on 48 particles.
All processor chips in a cluster calculate the force on the same set of 48 particles, from different sets of particles. Thus, we need a fast network to first broadcast the 48 particles to all processor chips, and then summing up the result calculated on 256 chips in a cluster. The broadcast in hardware is pretty simple to implement in hardware. The summation network is implemented using FPGA chips as node points. Each FPGA chip implements a sequencer and 4-input adder. This FPGA and other circuits on board operate at 1/4 of the clock speed of the chip. The data width for the network on board is 32 bits. So the communication speed of any link in the network is 88MB/s.
For the link between boards, we have adopted a fast semi-serial link with LVDS signal level, which can achieve the above data rate with four pairs of twisted-pair cables (the same as the standard cable for 100Mbit Ethernet). We adopted DS90CF364AMTD and DS90C363AMTD from National Semiconductor as the LVDS devices.
The structure of a NB is essentially the same as that of the processor board, but it carries links to the next level of the tree (either NB or PB) instead of the processor chips. Figure 9 shows the network board.

Figure 9: The GRAPE-6 network board.
From the viewpoint of a user, the primary difference between GRAPE-4 and GRAPE-6 is the speed. The peak speed of GRAPE-6 (when completed) will be 100 times faster than that of GRAPE-4. In order to achieve a reasonable sustained performance, the peak communication bandwidth to the host computer is improved by a factor of 20. On the other hand, what is calculated is essentially the same for GRAPE-4 and 6. Both calculate the gravitational force and its time derivative, using predicted positions and velocities of particles stored in local memory on the side of the GRAPE hardware.
The 100-fold increase in the peak speed mainly comes from the performance improvement of the processor chip. The GRAPE-4 force calculation pipeline chip has single pipeline unit running at 32 MHz clock, which needs three clock cycles to evaluate one interaction. The GRAPE-6 chip has six pipelines running at 90 MHz, which can evaluate one interaction per clock cycle. Thus, GRAPE-6 chip is 50 times faster than GRAPE-4 chip.
The 18-times increase in the number of pipelines (from one third to
six) was made possible by the miniaturization of the device (from 1
 to
to 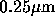 ). The improvement in the clock
frequency also comes primarily from the same miniaturization of the
device.
). The improvement in the clock
frequency also comes primarily from the same miniaturization of the
device.
However, it should be noted that this improvement of a factor of 50 is achieved only through a drastic change in the overall architecture of the hardware. In GRAPE-4, a force calculation chip contains just one pipeline with no control logic. The particle data is fed from the predictor pipeline (PROMETHEUS chip), which also has a rather simple pipeline architecture. The interface and control logic were implemented using FPGA chips on the processor board, and there is only one memory unit on a board.
In GRAPE-6, however, a processor chip integrates multiple force calculation pipelines, a predictor pipeline, a memory interface unit, control logics and communication interface. In other words, GRAPE-6 chip integrates one GRAPE-4 processor board. In fact, the architecture of the GRAPE-6 chip shown in figure 8 is identical to that of the GRAPE-4 processor board, except for details such as the number of pipelines and the width of the memory data bus.
This integration has various side effects, but the most important one from the viewpoint of the designer is that now one force on a particle is obtained as partial sums on a number of chips (in a full GRAPE-6 clusters, 256 chips on 16 processor boards), instead of just 9 chips in the case of GRAPE-4. In GRAPE-4, 9 processor boards are connected to a shared bus with the data width of 96 bits, and a control board sequentially reads the registers of chips on processor boards and accumulates the results using a floating-point adder chip.
With GRAPE-6, it is clear that we cannot take the same approach, since to accumulate 256 forces would take too long time. The only alternative is to construct an adder tree. The problem with the adder tree is that we need a rather large number of adders. an adder tree for 256 input would need 127 adders if constructed with 2-input adders. If we use a floating-point adder chip for the adder tree, the cost of the adder tree would be comparable or higher than the cost of the processor chips. Moreover, most of floating-point adder chips has become out of production. On the other hand, implementing 64-bit floating-point adders to FPGAs is not impossible, but would require rather large and expensive chips and throughput would be low.
To solve this difficulty, we chose to use fixed point number format for the accumulation of the force (and it time derivative as well). Since we have to handle a very wide range in distance and therefore in force, a naive use of the fixed point format would result in a very long data format to avoid overflow and underflow. To keep the length of the accumulator reasonably short, we decided to let each particle to have scaling coefficient of the force on it, which effectively works as the exponent for the calculated force. As a result, we can use fixed point adders both for the adder tree and the final accumulator of the force calculation pipeline. The host computer has to provide an appropriate scaling factor for each particle, but it can be easily calculated from the force on it at the previous timestep. Thus, the change in the application program is very small.
As of the time of writing, we have a 6-PB system, where three processor boards are connected to one network board. Two network boards are directly connected to the host computer without using the next level of network board. Figure 10 shows the structure of this system. This system has a theoretical peak speed of 2.889 Tflops. The host computer is a UP-2000 based Alpha (EV6, 667 MHz) box with two processors and 2 GB of memory, running Compaq Tru64 UNIX.

Figure 10: The present testbed GRAPE-6 configuration used for the simulation.
Figure 11 shows the photograph of the current six-board system. One can clearly see that it is a small system still in development phase. However, this small system has the theoretical peak speed close to three Teraflops. The only ``general-purpose'' machines that are faster than this small box are huge and expensive ASCI machines.

Figure 11: The six-board GRAPE-6 configuration used in this study. Eight
processor boards are visible but only six were actually used in the
calculation reported in this paper. The black box in front is the host
computer (a two-processor Alpha box)