ここでは、本来分類されるべきものは手法ではなく、問題の分類があってそれ に対応して手法があるのかもしれないが、まあ、実際には、問題の定義自体が、 「こういう方法で解ける」というのをかっこよくいっただけというところもあ る。とりあえず、ここで考える分類は以下のようなものということにしておく。
決定論的方法とは、文字通り問題とやり方を決めればあとは機械的に計算が進 んで、いつでも同じ答がでるものである。これに対して、確率的方法とは、良 さそうな答を捜す時に乱数等を使ってある意味「適当」にやるものである。
適当にやるよりも、真面目にやったほうがいいに決まってるのではないかと思 うかも知れないが、必ずしもそういう問題ばかりではない。例えば、ある種の 問題では、まともにやって正しい答を求めるのに必要な手間が、問題の大きさ の多項式よりも速く増大する。
この一例が巡回セールスマン問題というものである。これは、名前の由来は、 「あるセールスマンが一日に沢山のお客を回る時に、どの順番で回るのがもっと も効率的か?」ということであるが、例えば電話線やネットワークの線をどう 引くのか効率的かといった問題にも応用される、実用上はいろんなところで出 てくる問題である。
素朴な解法は、全部の順序を調べてもっとも短いのを捜すというものだが、こ
れは手間が回る場所の数 nの階乗で増えるので n が 10を超える当たりか
ら実際的ではなくなる。が、例えば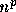 といった、n の冪乗の手間で正し
い解が見つかるような方法は知られていない。
といった、n の冪乗の手間で正し
い解が見つかるような方法は知られていない。
ところが、このような問題に対して「シミュレーテッドアニーリング」や「遺
伝的アルゴリズム」といった、確率的な方法を使うと、それが本当にもっとも
良い解であるという保証はないが、まあまあそんなには悪くない解が 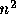 程度の手間で求まる。
程度の手間で求まる。
まあ、この辺の詳しい話は来週にして、決定論的方法のほうの分類だが、連続 関数というのは定義域が N次元ユークリッド空間の連続な部分集合で、最適 化したい目的関数も連続な実数値関数であるようなものである。そうでないも のというのは要するにそれ以外の全部である。上の巡回セールスマン問題は後 者の一例である。
この講義では、離散的な場合の決定論的方法はやらない。これは、問題によっ てあまりに沢山いろんな方法があるので、何をやるべきか良くわからないから である。