配列に関しては C++ は Fortran に比べて必ずしも良くなっているとはいい難 い、というか正直いって退化しているが、プログラムの構造という観点からは いくつか Fortran にはない有用な特色を持つ。その一つがここで述べる再帰 である。なお、最近の多くの Fortran コンパイラでは、言語仕様では再帰を サポートしていなくても実際には仕様が拡張されていて再帰が使える。
再帰とは、手続きが「自分自身を呼び出す」ことである。これは、プログラミ ングの理論的な扱いという観点からも、また、実用上からも非常に重要な考え 方である。簡単な例から考えてみよう。
// factrial
#include <iostream>
double factrial(int n)
{
if (n <1){
return 1.0;
}else{
return n*factrial(n-1);
}
}
int main()
{
int n;
cout << "Enter n:";
cin >> n;
cout <<"N = " << n << " N! = " << factrial(n) <<endl;
return 0;
}
上の例 は、階乗を計算するプログラムである。階乗は、下のように定義される:
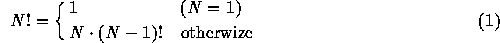
本当は N が整数でないと定義されないし結果も整数だが、整数だとすぐにオーバーフロー してあまり大きな数の階乗は求められないのでプログラムでは double を使っている。
CやPascalのような「近代的」プログラミング言語では、この定義に従って素直にプログ ラムを書くことができる。上の例では、まさに、 n が 1 なら 1 を返 し、それ以外では n*factrial(n-1)を返すというのが、 factrial(n)の中身になっている。
例えば factrial(5) を計算させるとすると、実際の計算は、以下のよ うな手順で進む。
factrial(5) →5*factrial(4) →5*(4*factrial(3)) →5*(4*(3*factrial(2))) →5*(4*(3*(2*factrial(1)))) →5*(4*(3*(2*1))) →5*(4*(3*2)) →5*(4*6) →5*24 →120
計算機の構造を考えると、こういうことができるというのは一見不思議ではあ る。つまり、関数 factrial の引数 n は同じものなのに、なぜ それが呼ばれるたびに違う値をとることが可能になるのであろうか?
再帰処理を許さない言語の場合、関数の引数や関数中で宣言された変数には 「固定したアドレス」が与えられる。このために、関数が自分自身を呼ぶと、 引数の値や変数の値が書き変わってしまいなんだかわからない動作をすること になる。
これに対し、 C/C++ などの再帰処理を許す言語では、関数の引数や関数中で 宣言された変数は固定されたアドレスを持っているわけではなく、関数が呼ば れる度に新しいメモリ領域が割り当てられる。これは別に難しいことではなく て、ある連続したアドレス領域(通常スタック、、、書類を積み上げた山、、、 と呼ばれる)をあらかじめ確保しておいて、サブルーチンが呼ばれればそこに 新しく場所をとり、サブルーチンから抜ける時に使っていた場所を返すだけで ある。
ただこれだけのことで、「関数が自分自身を呼ぶ」というなんだか怪しげなこ とが実現できるわけである。
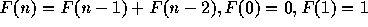 を再
帰、再帰でないものの両方を使って書け。
を再
帰、再帰でないものの両方を使って書け。