15. HPL 書き直しその5 (2009/9/16 書きかけ)
ここでは、並列化について考えます。HPL と同様なサイクリック分割をして、
分割の単位としてはとりあえず NB=2048 を想定します。但し、通信を考えた時
にこれがベストなサイズかどうか、つまり、縦パネルのサイズと通信の単位は
同じがよいのかどうかは検討の余地があります。
基本的な手順としては、
一つのキーになるのは、前のパネルの update から次のパネルの update までに
どれだけ空き時間がはいってしまうか、ということです。次のパネルについて
の処理は
問題は左パネルです。これは最大で 2k x 32k =500MB、平均でその半分のサイ
ズがあります。転送は 16 x P(Q?) 回で、計算時間に対する通信時間の比は
P や Q によりません。なので、 5GB 受け取って 20秒計算、という感じの割
合になり、かなり大きなオーバーヘッドになります。1GB/s でたとしても、
平均で 0.3秒です。
この部分をつめるには、PUPDATE をしながら、転送できるところは転送を始め
ればよいことはすぐにわかると思います。パネル分解自体には平均1秒程度の
時間がかかるはずなので、オーバーラップできれば隠蔽できます。但し、
例えば左半分の処理が終わったあとでも、計算の最後でこの部分にもう一度行
交換をかける必要がありますから、仮にこの部分を先に送ったとすると、ピボッ
ト配列も送って行交換とスケーリングもする必要があります。また、この場合
には対角パネルも送り先で処理することが必須になります。従って、手順とし
ては、
a)対角パネルをもつ時。
HPL では、「行交換とU放送を混ぜる」という複雑な方式を採用しています。
これのメリットは通信時間を短縮できることのはずです。例えば、 Long メソッ
ドでは、まず交換前の U を放送し、それからそれぞれの行でどう交換された
かという情報をリングでぐるっと回して全部のところでつじつまがあうように
します。
ぐるっと回る情報の量は結局 U 全部と同じで、これは
基本的に、ネットワークがトーラスで隣としかつながっていない、といった場
合にどうやって改善するか、というアルゴリズムなので、必ずしも通信量が減
るわけではないように思います。なので、今回はこの方法にこだわらず、単純
な実装を使います。
1ノード用のコードでは、再帰的パネル分解の途中で row major と column
major を入れ替えることでそれなりの性能向上を実現できましたが、
並列版ではどうするべきか、ということを考えてみます。まず、単純に考える
と、行交換の速度は所詮通信速度にリミットされるのであまり意味がないよう
にも思えます。しかし、実際の計算を考えると、
行交換の問題はもっと基本的なところにあります。基本的なアルゴリズムでは
1行づつ交換していて、これはもちろん、原理的にはここに依存関係がある
からです。つまり、例えば 2 行目と10行目を交換したあとに、3行目と10行目
を交換したら、元々の2行目が最終的には3行目に戻ってくるわけです。この時
に、10行目には3行目が入ります。つまり、 2, 3, 10 が 10, 2, 3 となるわ
けです。
もうちょっと違うケースとして、 2 行目と3行目を交換した後に 3 行目と
10行目を交換したら、 2, 3, 10 行目にはそれぞれ 3, 10, 2 行目が入ること
になります。
もちろん、これは、まず移動元を全部バッファに移し、それからそのバッファ
から移動先に一括して移動するようにすれば済む話です。もっとも、
これを本当にやると、少なくとも1ノードの場合、メモリアクセスが 4/3 倍に
増えてしまうことになって面白くありません。
といっても自分でも良くわからないので、以下にアルゴリズムを書いてみます。
ピボット配列 pv はブロックサイズを K として、 0:K-1 の各行をどれと交換
するべきか、がはいっています。これを使って、まず行き先の配列を作ること
を考えます。これは、0:N-1 までが順番にはいった配列 id を作っておいて、
それにピボット配列によって与えられた交換を適用すれば作成できます。(ここ
では N は現在のブロックを含めた残りの行列のサイズで、元々の行列のサイズ
ではないとします)ここで、 i 行目に j と書いてあれば、そこにデータをもっ
てくればよいわけです。
まず、 k 行目以降については、行き先は必ず k-1 より前になります。これは、
一度交換されたらもうそれ以降はピボット探索に入らないからです。なので、
転送はピボットをもつプロセッサに送るだけでよいことがわかります。
ピボットをもつプロセッサが持つ 0:k-1 行については、自分の中ですむとこ
ろもあるしそうでないところもありますが、まあ、行き先に送る、というだけ
です。つまり、ピボットのところについては、どうせ殆どの行が入れ替わるの
で、
まだ今一つイメージがわかないので、なにが並列に起こるか、という観点から、
最初のステップから順番に書いてみます。
次の対角パネルについて考えると、これは L を受け取ったあと、上から1パネ
ル受け取れば次の対角パネルのアップデートができるので、これがすめば縦
消去が始められます。但し、この時には残りのアップデートもあります。
計算のクリティカルパスがどこにあるか、ということを考えると、1ノードの場
合のように縦パネル消去とアップデートを並行処理するのがよいのか、それと
も縦パネル消去だけを可能な限り早く終わらせるのがよいのか、という問題が
あります。縦パネル処理が終わっていれば、次の次の縦パネル処理を原理的に
は始められるからです。もちろん、縦パネル処理を極限まで速くしても隣では
まだ前のアップデートがおわっていないはずです。前のアップデートが
終わる前に次のパネル消去を始める、というのは、GRAPE-DR 上のデータを
再利用できないケースが発生するので望ましいことではありません。なので、
縦パネル処理は極限まで速く終わる必要は実はなく、そこそこでよいわけです。
並行処理しないとどうなるかというと、対角パネルを含む列のアップデートは
次の列よりもかなり遅れて終わることになります。
この場合に、パネル消去と通信を並列にする必要は多分ありますが、これはあ
とからでも実装可能と思います。
さて、update です。GRAPE-DR の仕様や、今回の通信方式から、
L は前のステップのうちに送られてきていることを想定します。
データ量として、最大 500MB、平均 250MB 程度であり、これが update をし
ている間、ないしは、前の列で縦パネル分解がおわってから、自分の update
が終わるまでの間に転送できればよいので、これが秒程度の時間であることを
考えると通信速度がそれほど速い必要はありません。
U については話ははるかに面倒です。というのは、ここでは
行交換と放送を混ぜるなら、やることは MPI_SCATTERV と MPI_ALLGATHERV で
できるわけで、 HPL に実装されている面倒な通信アルゴリズムを使うまでも
ない可能性が高いです。これは、これらを実質非同期通信として使って大丈夫
かどうかに依存しますが。この場合には、全プロセッサで
通信量ですが、ピボットの行からは SCATTERV で U が全部でていきます。
ALLGATHERV では全部はいってくるので、結局クリティカルパスになるのは
ピボット行のプロセッサのはずで、これは並行動作しないで全部送り、全部受
け取るわけです。データ量は最大 1 GB、平均 500MB です。計算時間は最大5
秒で、計算時間は残りサイズの2乗に比例するのに対して通信は1乗という問題
はありますが、最大の時に間に合っていれば効率低下は 33%、半分の時に間に
合っていれば10%程度になるので、半分の時に間に合う、というのが目安です。
これは500MB/s 程度の実効通信速度、ということになります。
パネル分解については、対角パネルとその下で同じように再帰をすることにな
り、再帰の最後のステップ以外は、基本的に普通の処理と同じなので特別なこ
とはありません。左側の行交換についてはもう放送や DTRSM がいらないので、単純
な処理をするべき、というのが違うところです。
最後のステップでは2列の処理の形にします。まず、ピボット探索で最大値を探
索します。これは MPI_MAXLOC を使えばMPI_ALLREDUCE で一発で計算できます。
それからこれをピボット行と交換し、スケールし、放送、という手順ですが、
通信のステップ数を減らすためにはもうちょっと考えておかないといけません。
では、各プロセッサのプログラムの構造をもう一度整理します。
基本的には、以下のようなものであればよいはずです。
さて、あとは、サイクリック・ブロッキングをどうプログラムで表現するかで
す。すぐにわかることは、ピボット処理以外では、「自分の左側にもデータを
送る必要がある」ということ以外に特にサイクリックだからといって考える必
要はない、ということです。
単純に、 4x4 にブロックした行列を 2x2 のプロセッサグリッドで処理するこ
とを考えてみます。もとの行列が
また、その後の swap, update についても、別に意識するところはありません。
問題は、 Ax1 列の処理にはいるところです。行列は
プロセッサの数が
行列サイズを
この辺から 10/9 です。で、ぼちぼち並列版を書いています。
まず、ブロック化しないものを書いて、それからブロック化し、それから最終
的に縦パネル再帰をやります。
アルゴリズムとして意外に面倒な感じがするのは後退代入のところになります。
ベクトル b (途中までは a の最終列として処理される)は下から順番に処理さ
れて、その処理は下の要素全部からなるベクトルと a の1行の積になります。
まず、ブロック化しない場合を考えてみます。内積型の処理であれば、 a は分
散してもたれているとしても、 b は小さいので放送するとします。そうする
と、b の要素が1つ求まる度にそれを放送して、次の要素の行をもつプロセッ
サで内積を計算、合計もして、引き算もすればいい、ということになるでしょ
う。
SAXPY 型の処理にすると、 求まった b を縦に放送した後で、対応する a の
列と掛けて引き算、となります。これを a をもっているプロセッサ列でやれ
ば、1行の処理毎には横方向の通信が発生しない、というのはメリットである
はずです。ブロックが切り替わる時には b を全部放送するのが簡単でしょう。
なお、b を縦に放送するのも、もっとも単純なアルゴリズムでは1要素毎にす
るわけですが、1ブロックの要素が全部求まってから放送でもあまり問題はな
いはずです。遅延は発生しますが、通信回数を劇的に減らすことができます。
計算時間として問題かどうかをあらかじめ見つもっておきます。非同期とか難
しいことを考えないと、メモリアクセスは行列全体ですが、これは縦方向のプ
ロセッサしか使いません。例えば、 256ノードの Core i7 クラスタで16x16 の
プロセッサグリッドの時に、メモリ総量は大体 3TB になるわけですが、16ノー
ドでの並列処理だと思うとメモリバンド幅は 300GB/s 程度しかなく、ベストで
も10秒程度かかってしまいます。これに対して LU分解自体は 500-1000秒なの
であまり無視できません。従って、もうちょっと並列度を横方向に増やす必要
があります。
全ノードを使うようにするのは別に難しいことではなくて、 1 ブロック単位
ではなくて、横方向のプロセッサ数だけのブロックをまとめて処理すればよい
わけです。まとめるために、最初はやはり少数のプロセッサしか働かない処理
がはいりますが、その分の計算量は小さいので常時1列しか動かない場合より
は大きく改善されます。
この方法では、基本的にはまだ処理がおわっていない行列のうち、下の
16(プロセスグリッドの横の数) x 16 の領域をまず処理します。
これには、一番右下の処理をして、それからこれで求まった b を全ノードに放
送し、同じ列のプロセッサでこの b の寄与を計算し、 b を左の列に移します。
そうすると、あとは最右下のプロセッサの斜め上が自分の中の処理をして、下
に放送して、という繰り返しになり、対角位置のプロセッサに対応する行の b
が求まることになります。
通信は、主要項は b の横向きの通信(放送)と、内積のやはり横方向の総和の
はずです。これは、1プロセッサの1行が 32k ワード = 256kb くらいで、
これを16回とかの通信ですから数 MB となりあまり問題になるような量では
ありません。レイテンシも、通信回数が非常に少ないため、大きな問題にはな
らないはずです。
この処理のブロックサイズは本当は GRAPE-DR の要請から決まるものよりもずっ
と小さいものであるべきですが、コーディングが煩雑になりそうなのでそこを
変更するのはできれば避けたいかもしれません。
というわけで、ブロック化しない場合でも SAXPY 型の処理で書いてみるのが
よさそうです。
とりあえず、メモリ配置はブロック化しているけどアルゴリズムは単純な
BLAS1 レベルのものを書いてみた。
以下、デバッグ中のメモ
have_currnt_col の結果が間違っている。
Procid=1, i, nb, bid, npcol, procid = 0 2 0 1 0
1: hav_current_col = 0
p=2 なので processors in row = 2
have_currnt_col = 0 になるのはあっていて、行列の寸法とかのほうがおかし
い。
というか、そもそも p, q の使いかたがおかしかった。修正する。
P=2、 Q=1 のときに、プロセッサグリッドは
rank_in_row がおかしい。
ものすごく沢山のバグを直した。
答は、、、とりあえず、 nan ではないものがでるようになった
元行列
検算をどうするか、ということも考える必要があります。ブロック化されてい
いて、また縦と横はブロックの周期が全然違うかもしれないので、 b を縦方
向に放送して全部もたせるのが簡単なような気がします。それから、
bの必要なところを切り出して、 a と乗算し、その結果を横方向に積算すれば
よいはずです。
q=3, n=3 も OK (n=6,12,18)
次は横方向
動いているような気がする
縦横: 2x2 なら動く
もうちょっと検証が必要な気もするが、ブロック化のほうを始めてみよう。
ブロック化。
まず、再帰にはしないのをする。基本的アルゴリズムは
ブロックについて、 l1 のブロック番号、 l2-1 のブロック番号を判定して、
その範囲内に自分のインデックスがひっかかるかどうか。ひっかかるならどこ
からどこまでか。
あるレンジの整数の中に p でわって q あまる数があるか?
まあ、実際には一般の場合が必要なわけではないので、、、あ、でも、
update の時には起こるのか。
bl1 = bl2 なら判定しておしまい
bl1 != bl2 の時: bl1 がかかっていればかかっている
ブロック化の基本はできた。但し、コードはまだ行列積が見えてないので、見
える形に変更必要。
現在のコード: 単純に 1 行更新のループを回しているだけ。
これをまず、 nb だけ更新と下も更新に分離。これをやって行列積をだすのは
できた。
パネル分解のシーケンスを考えると、、、、
問題は、 L の転送にどれくらい時間がかかるかかな?行列サイズが 20K の時
に、update の時間は、演算数が 20Kx20Kx2Kx2 = 1.6T なので、1 Tflops で
ると 1.6sec で終わる。データ量は 40MW = 320MB なので、DDR x 2 で
1.2GB/s くらいもしも出るなら 0.25秒。
1024 x 1024 + 512x512*2 + ... = 1K*2K*20K*2 =80G
通信量は GRAPE-DR 側とで 160MB*3、主記憶とはその数倍。
まあ、半分以下では終わる。普通に DmU を計算するなら
LDm を使うけど後に計算するなら、
まあ、まずは DTRSM を分離して、それからそれを変形して、それからですかね。
とりあえず、
転置、最初のステップは動いている。次のステップで正しくできてない?
間違い
Printmat_MP: Proc 0, loc = 0 0
Printmat_MP: Proc 0, loc = 0 0
では合う。
mpirun -np 2 lらいかな。
16プロセスでテストしたい。
現在の計算手順
同期して、
GDR のメモリ分割使用が間に合わないと仮定するなら、上の手順はパネル分解
まで考えると最適に近いはず。
これを今のコードから壊さないように作りたい。
今のコードは、見かけ上
lookahead にするには、 Dm, L の分離が必要。これは実装した。
an03 を使って 16 プロセッサまでのテストをした
答のチェックをするルーチンをつける必要あり。
b>= 16 で止まるバグあり、、、
mpirun -np 2 lu2_mpi -n 32 -p 2 -q 1 -b 16 止まる
mpirun -np 2 lu2_mpi -n 32 -p 1 -q 2 -b 16 止まらない
これは同期の問題? printmat_MP を外したら動作した。
最後のブロックの時に放送処理がおかしい気が。
というか、これ結構全然変ではある。
lookahead しなければ全然問題なく動くので、やはり問題は lookahead
計算は終わってるけど、通信に何か解決していないものが残っているらしい。
というか、lookahead なしで動いているのは何故か?のほうが問題かな。
というか、やっぱり調整のしかたが全然おかしい。lookahead をするのは次の
current column をもつやつだけにするほうが自然。
あ、問題の一つは scale ルーチンが通信必要としていること。 scale の配列
も作る必要あり。
作った。これにしたら動くようになった。
あとテストするべきこと:
これは実装した。
スレッド化して本当に動くのか、という問題がある。つまり、
Bcast 等の通信が、スレッド化しても動くのか、という、、、
実際にやってみたところ動いている気がしない。
OpenMPI の configure で指定必要
6 22:01 ../configure --with-threads=posix --enable-mpi-threads
Proc:1 lbl:0 Error = 3.975320e-12
Proc:1 lbl:1 Left bcast etc time=1.94356e+09 ops/cycle=0.00404636
Proc:1 lbl:1 update time=5.95055e+09 ops/cycle=3.4961
Proc:1 lbl:1 update matmul time=5.29666e+09 ops/cycle=2.04938
Proc:1 lbl:1 update swap+bcast time=8.51015e+07 ops/cycle=0.393517
現在のコードでこういうシーケンスになっているか?
結局、横方向の Bcast をいつどこでするか、という問題。
MP_calculate_ld が異常に遅い。放送のタイミングがおかしい?ここで同期待
ちになっている?
P0, enter process_lmat, time=0.015178
P1, enter process_lmat, time=0.0162599
P1, enter dls_phase_2, time=0.018703
P0, enter dls_phase_2, time=0.0189419
P0, end dls_phase_2, time=0.0205019
P0, enter dls_phase_1, time=0.02051
P1, end dls_phase_2, time=0.0208201
P1, enter dls_phase_1, time=0.0208299
P1, end dls_phase_1, time=0.0233159
P1, enter dls_phase_2, time=0.023334
P0, end dls_phase_1, time=0.023561
P0, enter dls_phase_2, time=0.0235779
P0, end dls_phase_2, time=0.0250549
P0, enter dls_phase_1, time=0.0250628
P1, end dls_phase_2, time=0.0253561
P1, enter dls_phase_1, time=0.0253661
P0, end dls_phase_1, time=0.0271628
P0, enter dls_phase_2, time=0.0271749
P1, end dls_phase_1, time=0.026942
P1, enter dls_phase_2, time=0.026952
P0, end dls_phase_2, time=0.0288889
P2, enter process_lmat, time=0.0286191
P1, end dls_phase_2, time=0.0292521
P3, enter process_lmat, time=0.0295582
P2, end process_lmat, time=0.0301819
P0, end process_lmat, time=0.0304739
P1, end process_lmat, time=0.0321391
P3, end process_lmat, time=0.0321221
P0, enter process_lmat, time=0.015178
P0, enter dls_phase_2, time=0.0189419
P0, end dls_phase_2, time=0.0205019
P0, enter dls_phase_1, time=0.02051
P0, end dls_phase_1, time=0.023561
P0, enter dls_phase_2, time=0.0235779
P0, end dls_phase_2, time=0.0250549
P0, enter dls_phase_1, time=0.0250628
P0, end dls_phase_1, time=0.0271628
P0, enter dls_phase_2, time=0.0271749
P0, end dls_phase_2, time=0.0288889
P0, end process_lmat, time=0.0304739
dls phase 1 と dls phase 2 が並列になっていない。何故?
phase 1 の2個めが終わるのが異常に遅くなっている。
CONCURRENT_LCOMM をいれると落ちる、、、、
で、排他制御するともちろんデッドロックになると。うーん。
LCOMM ができるタイミングは列によって違う。
細かいパネルに分けて、非同期通信のリングにしてみる?
lu_mpi look i=2048 end
lu_mpi look i=4096 end
P0, enter process_lmat, time=106.34
P0, end process_lmat, time=125.485
P0, enter dls_phase_2, time=126.728
P0, enter dls_phase_1, time=126.728
P0, end dls_phase_1, time=127.084
P0, end dls_phase_2, time=130.858
P0, enter dls_phase_2, time=130.858
P0, end dls_phase_2, time=134.999
P1, enter process_lmat, time=108.529
P1, end process_lmat, time=126.431
P1, enter dls_phase_2, time=126.728
P1, enter dls_phase_1, time=126.731
P1, end dls_phase_1, time=127.084
P1, end dls_phase_2, time=133.04
P1, enter dls_phase_2, time=133.04
P1, end dls_phase_2, time=139.388
P2, enter process_lmat, time=125.226
P2, end process_lmat, time=125.485
P2, enter dls_phase_2, time=126.767
P2, enter dls_phase_1, time=126.767
P2, end dls_phase_1, time=127.089
P2, end dls_phase_2, time=130.986
P2, enter dls_phase_2, time=130.986
P2, end dls_phase_2, time=135.219
P3, enter process_lmat, time=126.099
P3, end process_lmat, time=126.431
P3, enter dls_phase_2, time=126.767
P3, enter dls_phase_1, time=126.767
P3, end dls_phase_1, time=127.089
P3, end dls_phase_2, time=132.972
P3, enter dls_phase_2, time=132.972
P3, end dls_phase_2, time=139.17
まあ、それはともかく、この実行プロファイルでは
UCOMM overlap も止めると
P0, enter process_lmat, time=111.205
P0, end process_lmat, time=130.411
P0, enter dls_phase_2, time=131.714
P0, end dls_phase_2, time=135.921
P0, enter dls_phase_1, time=135.921
P0, end dls_phase_1, time=138.235
P0, enter dls_phase_2, time=138.235
P0, end dls_phase_2, time=142.467
元々時間かかっていないので、あまり変わらない。
LCOMM と並行動作させるとエラーになるのをどうするべきか?
転送するもの
P0, enter process_lmat, time=65.715
P0, enter dls_phase_2, time=71.2662
P0, enter dls_phase_1, time=71.2742
P0, end dls_phase_1, time=73.2175
P0, end dls_phase_2, time=76.4328
P0, enter dls_phase_2, time=76.6744
P0, end dls_phase_2, time=80.8975
P0, end process_lmat, time=81.2736
P1, enter process_lmat, time=66.7893
P1, enter dls_phase_2, time=71.2159
P1, enter dls_phase_1, time=71.2409
P1, end dls_phase_1, time=73.2175
P1, end dls_phase_2, time=78.45
P1, enter dls_phase_2, time=78.6682
P1, end process_lmat, time=80.0502
P1, end dls_phase_2, time=82.7323
P2, enter process_lmat, time=78.9553
P2, enter dls_phase_2, time=80.6957
P2, enter dls_phase_1, time=80.8317
P2, end process_lmat, time=81.2736
P2, end dls_phase_1, time=83.0168
P2, end dls_phase_2, time=84.3344
P2, enter dls_phase_2, time=84.5809
P2, end dls_phase_2, time=86.9622
P3, enter process_lmat, time=79.5863
P3, end process_lmat, time=80.0501
P3, enter dls_phase_2, time=80.6247
P3, enter dls_phase_1, time=81.0377
P3, end dls_phase_1, time=83.0167
P3, end dls_phase_2, time=84.7351
P3, enter dls_phase_2, time=84.7588
cpsec = 237.376 wsec=142.137 20.6282 Gflops
LCOMM OMP 並列にしないと
P0, enter process_lmat, time=64.3393
P0, end process_lmat, time=77.2257
P0, enter dls_phase_2, time=78.2386
P0, enter dls_phase_1, time=80.1199
P0, end dls_phase_2, time=80.5685
P0, end dls_phase_1, time=80.8422
P0, enter dls_phase_2, time=81.0689
P0, end dls_phase_2, time=83.4249
確かに並列にはなるが、速くはならない。何故?
lu_mpi look i=2048 end
P0, enter rfact, time=64.4474
P0, end rfact, time=64.4474
P0, enter process_lmat, time=64.4474
P1, enter rfact, time=65.517
P1, end rfact, time=65.5171
P1, enter process_lmat, time=65.5171
P0, enter dls_phase_2, time=66.9711
P0, enter dls_phase_1, time=67.2811
P1, enter dls_phase_2, time=67.527
P1, enter dls_phase_1, time=67.59
P2, enter rfact, time=67.6308
P3, enter rfact, time=68.7042
P0, end dls_phase_1, time=70.0524
P1, end dls_phase_1, time=70.0525
P0, end dls_phase_2, time=71.9281
P0, enter dls_phase_2, time=71.9533
P1, end dls_phase_2, time=75.059
P1, enter dls_phase_2, time=75.3143
P2, end rfact, time=75.6056
P2, enter process_lmat, time=75.6057
P3, end rfact, time=76.2439
P3, enter process_lmat, time=76.244
P0, end dls_phase_2, time=76.3771
P2, end process_lmat, time=76.7807
P0, end process_lmat, time=76.7807
P2, enter dls_phase_2, time=77.0775
P2, enter dls_phase_1, time=77.0885
P3, enter dls_phase_2, time=77.4254
P3, enter dls_phase_1, time=79.9335
P1, end process_lmat, time=79.969
P3, end process_lmat, time=79.969
P1, end dls_phase_2, time=80.8155
P2, end dls_phase_2, time=81.49
P3, end dls_phase_1, time=81.5227
P2, end dls_phase_1, time=81.5227
P3, end dls_phase_2, time=81.6226
P2, enter dls_phase_2, time=81.6806
P3, enter dls_phase_2, time=81.7736
P2, end dls_phase_2, time=84.0616
lu_mpi look i=4096 end
P0, enter rfact, time=64.4474
P0, end rfact, time=64.4474
P0, enter process_lmat, time=64.4474
P0, enter dls_phase_2, time=66.9711
P0, enter dls_phase_1, time=67.2811
P0, end dls_phase_1, time=70.0524
P0, end dls_phase_2, time=71.9281
P0, enter dls_phase_2, time=71.9533
P0, end dls_phase_2, time=76.3771
P0, end process_lmat, time=76.7807
lu_mpi look i=2048 end
P0, enter rfact, time=64.4762
P0, end rfact, time=64.4762
P0, enter process_lmat, time=64.4762
P1, end ld_phase2, time=65.5654
P1, enter rfact, time=65.5654
P1, end rfact, time=65.5654
P1, enter process_lmat, time=65.5654
P2, end ld_phase2, time=66.8101
P2, enter rfact, time=66.8101
P0, enter dls_phase_2, time=67.3126
P0, enter dls_phase_1, time=67.4176
P3, end ld_phase2, time=67.8633
P3, enter rfact, time=67.8634
P1, enter dls_phase_2, time=67.8674
P1, enter dls_phase_1, time=67.9844
P0, end dls_phase_1, time=68.8627
P1, end dls_phase_1, time=68.8626
P0, end dls_phase_2, time=72.5319
P0, enter dls_phase_2, time=72.7728
P1, end dls_phase_2, time=74.67
P2, end rfact, time=74.79
P2, enter process_lmat, time=74.7901
P1, enter dls_phase_2, time=74.8996
P3, end rfact, time=75.422
P3, enter process_lmat, time=75.4221
P1, end process_lmat, time=76.2936
P3, end process_lmat, time=76.2936
P2, end process_lmat, time=76.2994
P0, end process_lmat, time=76.2994
P2, enter dls_phase_2, time=76.4183
P3, enter dls_phase_2, time=76.531
P2, enter dls_phase_1, time=76.5993
P0, end dls_phase_2, time=76.7197
P3, enter dls_phase_1, time=77.2411
P2, end dls_phase_1, time=77.9863
P3, end dls_phase_1, time=77.9861
P1, end dls_phase_2, time=78.9986
P0, end mult_diag, time=79.183
P1, end mult_diag, time=79.1888
P0, end ld_phase1, time=79.2256
P1, end ld_phase1, time=79.2255
P2, end dls_phase_2, time=79.6116
P2, enter dls_phase_2, time=79.8444
P3, end dls_phase_2, time=80.254
P3, enter dls_phase_2, time=80.2842
P2, end dls_phase_2, time=82.2234
P0, end ld_phase2, time=82.6454
lu_mpi look i=4096 end
P0, enter rfact, time=64.4762
P0, end rfact, time=64.4762
P0, enter process_lmat, time=64.4762
P0, enter dls_phase_2, time=67.3126
P0, enter dls_phase_1, time=67.4176
P0, end dls_phase_1, time=68.8627
P0, end dls_phase_2, time=72.5319
P0, enter dls_phase_2, time=72.7728
P0, end process_lmat, time=76.2994
P0, end dls_phase_2, time=76.7197
P0, end mult_diag, time=79.183
P0, end ld_phase1, time=79.2256
P0, end ld_phase2, time=82.6454
Core i7 でmpirun -np 2 lu2_mpi -b 1024 -n 8192 -p 2
P0, enter rfact, time=1.71106
P0, end rfact, time=1.71112
P0, enter process_lmat, time=1.71121
P1, enter rfact, time=1.72011
P0, enter dls_phase_2, time=1.84366
P0, enter dls_phase_1, time=1.85969
P0, end dls_phase_1, time=1.92032
P1, end rfact, time=3.26344
P1, enter process_lmat, time=3.26358
P0, end dls_phase_2, time=3.30935
P1, end process_lmat, time=3.34927
P0, end process_lmat, time=3.34927
P0, enter dls_phase_2, time=3.3493
P1, enter dls_phase_2, time=3.34938
P0, enter dls_phase_1, time=3.3676
P1, enter dls_phase_1, time=3.36753
P0, end dls_phase_1, time=3.41504
P1, end dls_phase_1, time=3.41705
P0, end dls_phase_2, time=4.12134
P0, enter dls_phase_2, time=4.12148
P1, end dls_phase_2, time=4.1233
P1, enter dls_phase_2, time=4.12341
P1, enter dls_phase_1, time=4.12343
P1, end dls_phase_1, time=4.17027
P0, end dls_phase_2, time=4.87482
P1, end dls_phase_2, time=4.89525
P1, enter dls_phase_2, time=4.89539
P0, end mult_diag, time=5.20612
P0, end ld_phase1, time=5.20617
P1, end dls_phase_2, time=5.64788
P0, end ld_phase2, time=5.98567
lu_mpi look i=0 end
P0, enter rfact, time=5.98574
P1, end mult_diag, time=6.09012
P1, end ld_phase1, time=6.09018
P1, end ld_phase2, time=6.86781
P1, enter rfact, time=6.86786
P1, end rfact, time=6.86788
P1, enter process_lmat, time=6.8679
P1, enter dls_phase_2, time=7.03145
P1, enter dls_phase_1, time=7.04741
P1, end dls_phase_1, time=7.10526
P0, end rfact, time=7.32455
P0, enter process_lmat, time=7.32461
P1, end process_lmat, time=7.36378
P0, end process_lmat, time=7.36378
P0, enter dls_phase_2, time=7.39305
P0, enter dls_phase_1, time=7.43151
P0, end dls_phase_1, time=7.47814
P1, end dls_phase_2, time=7.8253
P1, enter dls_phase_2, time=7.82543
P1, enter dls_phase_1, time=7.82545
P1, end dls_phase_1, time=7.87404
P0, end dls_phase_2, time=8.05885
P0, enter dls_phase_2, time=8.05899
P1, end dls_phase_2, time=8.49089
P1, enter dls_phase_2, time=8.49102
P0, end dls_phase_2, time=8.70453
P0, end mult_diag, time=9.03709
P0, end ld_phase1, time=9.03715
P1, end dls_phase_2, time=9.13711
P1, end mult_diag, time=9.46952
P1, end ld_phase1, time=9.46958
P0, end ld_phase2, time=9.81542
lu_mpi look i=1024 end
P0, enter rfact, time=9.81548
P0, end rfact, time=9.8155
P0, enter process_lmat, time=9.81552
P0, enter dls_phase_2, time=9.97943
P0, enter dls_phase_1, time=9.99539
P0, end dls_phase_1, time=10.0542
P1, end ld_phase2, time=10.2455
P1, enter rfact, time=10.2456
0: U0 3.3 sec
1: U0 3.9 sec
7k * 3k * 1k * 2 = 42 G
ちょっと遅い。
P0, enter rfact, time=1.71106
P0, end rfact, time=1.71112
P0, enter process_lmat, time=1.71121
P0, enter dls_phase_2, time=1.84366
P0, enter dls_phase_1, time=1.85969
P0, end dls_phase_1, time=1.92032
P0, end dls_phase_2, time=3.30935
P0, end process_lmat, time=3.34927
P0, enter dls_phase_2, time=3.3493
P0, enter dls_phase_1, time=3.3676
P0, end dls_phase_1, time=3.41504
P0, end dls_phase_2, time=4.12134
P0, enter dls_phase_2, time=4.12148
P0, end dls_phase_2, time=4.87482
P0, end mult_diag, time=5.20612
P0, end ld_phase1, time=5.20617
P0, end ld_phase2, time=5.98567
縦の通信パートはすぐにおわっている。
DGEMM 自体が遅い?
P0, enter rfact, time=3.17814
P0, end rfact, time=3.17821
P0, enter process_lmat, time=3.1783
P0, enter dls_phase_2, time=3.27343
P0, enter dls_phase_1, time=3.28942
P0, end dls_phase_1, time=3.31881
P0, end dls_phase_2, time=6.37445 3sec
P0, end process_lmat, time=6.42638
P0, enter dls_phase_2, time=6.42644
P0, enter dls_phase_1, time=6.44134
P0, end dls_phase_1, time=6.47432
P0, end dls_phase_2, time=8.02559 1.6
P0, enter dls_phase_2, time=8.02572
P0, enter dls_phase_1, time=8.02575
P0, end dls_phase_1, time=8.07419
P0, end dls_phase_2, time=9.62465 1.6
P0, enter dls_phase_2, time=9.62478
P0, enter dls_phase_1, time=9.6248
P0, end dls_phase_1, time=9.65821
P0, end dls_phase_2, time=11.2239 1.6
P0, enter dls_phase_2, time=11.224
P0, enter dls_phase_1, time=11.2241
P0, end dls_phase_1, time=11.2581
P1, end dls_phase_2, time=12.6899
P1, enter dls_phase_2, time=12.69 1.5
P1, enter dls_phase_1, time=12.69
P1, end dls_phase_1, time=12.726
P0, end dls_phase_2, time=12.823
P0, enter dls_phase_2, time=12.8231
P0, enter dls_phase_1, time=12.8232
P0, end dls_phase_1, time=12.8527
P0, end dls_phase_2, time=14.4165 1.6
P0, enter dls_phase_2, time=14.4167
P0, end dls_phase_2, time=16.0225
P0, end mult_diag, time=16.7937
P0, end ld_phase1, time=16.7938
P0, end ld_phase2, time=18.4555
lu_mpi look i=0 end
P0, enter rfact, time=18.4556
P1, end ld_phase2, time=20.0277
P1, enter rfact, time=20.0227
P1, end rfact, time=20.0227
P1, enter process_lmat, time=20.0227
P1, enter dls_phase_2, time=20.1854
P1, enter dls_phase_1, time=20.2174
P1, end dls_phase_1, time=20.2348
P0, end rfact, time=21.1994
rfact が 1.5 秒
update が 15秒
25 Gflops
16k x 1k x 1k x 2 = 32G演算が 1.6 秒なので、 DGEMM はフルに 20Gflops
でている。
それでもトータルの性能が 25Gflops なのは、
・演算が増えている。 DTRSM で 1/8, DU 乗算で 1/4
・ブロックサイズが大きいことによる load imbalance 10% 程度はあるはず。
但し、これは
mpirun -np 2 lu2_mpi -b 256 -n 32768 -p 2 -g だと
cpsec = 1316.71 wsec=661.307 35.4695 Gflops
OMP_NUM_THREAD=1
mpirun -np 2 lu2_mpi -b 256 -n 16384 -p 2 -g
cpsec = 180.259 wsec=93.3039 31.4245 Gflops
mpirun -np 2 lu2_mpi -b 1024 -n 16384 -p 2 -g
cpsec = 224.782 wsec=122.441 23.9465 Gflops
OMP_NUM_THREAD=2
cpsec = 224.718 wsec=114.018 25.7156 Gflops
OMP_NUM_THREAD=3
cpsec = 224.474 wsec=113.548 25.8219 Gflops
OMP_NUM_THREAD=3
mpirun -np 2 lu2_mpi -b 256 -n 16384 -p 2 -g
cpsec = 180.263 wsec=90.9183 32.2491 Gflops
backward_sub_mpi の現在の方式
後ろから
1) bの1データ を放送
2) 対応する a (U) の各行と乗算、b から引く
をループ。このままでは DU を使えない。
DU 使うには
1) 自分のブロックで D と処理
2) b を1ブロックまとめて放送
3) D*(Ub) を計算して b から引く
の順序。計算量は倍になる。ただ、ここは計算量は問題ではないので、大丈夫
なはず。
D は必要なものをもっているか?
自分が current row だった時のを保存しておけばよい。
間違える時
Proc:1 lbl:9 a[0] = 0.732 1.09
Proc:1 lbl:9 a[1] = 0.903 1.17
Proc:1 lbl:9 d[0] = 1 0
Proc:1 lbl:9 d[1] = -0.722 1
D*A
Proc:1 lbl:9 a[0] = 0.732 1.09
Proc:1 lbl:9 a[1] = 0.375 0.379
Proc:1 lbl:9 d[0] = 1 0
Proc:1 lbl:9 d[1] = -0.722 1
なので、 D*A が積になるのは正しい。
対角部分は、正しいもの
Proc:1 lbl:9 ad[2] = -0.6209 0.05138
Proc:1 lbl:9 ad[3] = 1.42 0.1018
Proc:0 lbl:9 ad[0] = 0.7854 0.4632
Proc:0 lbl:9 ad[1] = 0.722 0.6994
DUPOSTMULT
Proc:0 lbl:9 ad[0] = 0.7854 0.4632
Proc:0 lbl:9 ad[1] = 0.722 0.6994
Proc:1 lbl:9 ad[2] = -0.6209 0.05138
Proc:1 lbl:9 ad[3] = 1.42 0.1018
なので、これも問題ない。従って、掛け算のプログラムが間違っているはず。
正しい時の bwork
Proc:1 lbl:9 a[0] = 0.7316 1.093
Proc:1 lbl:9 a[1] = 0.3749 0.3787
Proc:1 lbl:9 bwork[0] = 6.498
Proc:1 lbl:9 bwork[1] = -0.2113
Proc:1 lbl:9 bwork2[0] = 6.949
Proc:1 lbl:9 bwork2[1] = 2.381
間違っているほう
Proc:1 lbl:9 a[0] = 0.7316 1.093
Proc:1 lbl:9 a[1] = 0.9031 1.168
Proc:1 lbl:9 d[0] = 1 0
Proc:1 lbl:9 d[1] = -0.722 1
Proc:1 lbl:9 bwork[0] = 6.672
Proc:1 lbl:9 bwork[1] = -0.2203
Proc:1 lbl:9 bwork2[0] = 7.133
Proc:1 lbl:9 bwork2[1] = 7.594
Proc:1 lbl:9 bwork3[0] = 7.594
Proc:1 lbl:9 bwork3[1] = 1.651
あれ、 bwork が違う?
あ、そうか、この変形はしておかないといけない。
この変形はいれた。
Proc:1 lbl:9 a[0] = 0.7316 1.093
Proc:1 lbl:9 a[1] = 0.9031 1.168
Proc:1 lbl:9 d[0] = 1 0
Proc:1 lbl:9 d[1] = -0.722 1
Proc:1 lbl:9 bwork[0] = 6.498
Proc:1 lbl:9 bwork[1] = -0.2113
Proc:1 lbl:9 bwork2[0] = 6.949
Proc:1 lbl:9 bwork2[1] = 7.399
Proc:1 lbl:9 bwork3[0] = 7.399
Proc:1 lbl:9 bwork3[1] = 1.608
dinv が逆?何故こうなるんだっけ?
とりあえず、逆にしたら直った。
DU off
P1, end lmat/dls, time=13.6003
P1, end mult_diag, time=13.6006
P1, enter backward_sub, time=13.6006
P0, end backward_sub, time=13.6951
P1, end backward_sub, time=13.6951
cpsec = 26.3256 wsec=13.6951 26.7616 Gflops
on
P0, end lmat/dls, time=17.6706
P0, end mult_diag, time=17.6742
P0, enter backward_sub, time=17.6743
P1, end lmat/dls, time=17.6776
P1, end mult_diag, time=17.681
P1, enter backward_sub, time=17.6811
P0, end backward_sub, time=17.7988
P1, end backward_sub, time=17.7988
cpsec = 34.2981 wsec=17.7988 20.5915 Gflops
1ノードで見ると、性能低下の要因は基本的に rfact が遅いこと。ちょっと
チューニング必要。
これは、 MPI_Bcast や Send/Recv を n=1 でも呼んでるのを止めたら直った。
mgv での IB 使った実行、また LCOMM on だと止まる。うーん、、、
LCOMM off での実行プロファイルは
mympirun.csh 4 lu2_mpi -p 2 -q 2 -n 16384 -b 1024
cpsec = 133.2 wsec=37.3204 78.5638 Gflops
ピークの半分くらいしかでていない。
P0, enter rfact, time=1.08472
P0, end rfact, time=1.08474
P0, enter process_lmat, time=1.08474
Proc:2 lbl:9 end MP_calculate ld
Proc:2 lbl:9 lu2_mpi i=0
P2, enter rfact, time=1.08562
Proc:3 lbl:9 end MP_calculate ld
Proc:3 lbl:9 lu2_mpi i=0
P3, enter rfact, time=1.14135
Proc:1 lbl:9 end MP_calculate ld
Proc:1 lbl:9 lu2_mpi i=0
P1, enter rfact, time=1.1538
P1, end rfact, time=1.15382
P1, enter process_lmat, time=1.15383
P2, end rfact, time=2.09319
P2, enter process_lmat, time=2.09325
P3, end rfact, time=2.14445
P3, enter process_lmat, time=2.14451
P0, end process_lmat, time=2.17647
P2, end process_lmat, time=2.17647
P1, end process_lmat, time=2.23979
P3, end process_lmat, time=2.23977
P3, enter dls_phase_2, time=2.44219
P2, enter dls_phase_2, time=2.44217
P0, enter dls_phase_2, time=2.44743
P1, enter dls_phase_2, time=2.44747
P1, enter dls_phase_1, time=2.50974
P0, enter dls_phase_1, time=2.53638
P3, enter dls_phase_1, time=2.53975
P2, enter dls_phase_1, time=2.53975
P0, end dls_phase_1, time=3.13361
P1, end dls_phase_1, time=3.13366
P0, end dls_phase_2, time=4.1648
P0, enter dls_phase_2, time=4.16489
P1, end dls_phase_2, time=4.44376
P1, enter dls_phase_2, time=4.44384
P2, end dls_phase_2, time=5.18785
P3, end dls_phase_1, time=5.19677
P2, end dls_phase_1, time=5.19673
P2, enter dls_phase_2, time=5.19678
P0, end dls_phase_2, time=5.22698
P0, end lmat/dls, time=5.22706
P0, end mult_diag, time=5.23219
P3, end dls_phase_2, time=5.38927
P3, enter dls_phase_2, time=5.38935
P1, end dls_phase_2, time=5.71125
P1, end lmat/dls, time=5.71132
P1, end mult_diag, time=5.71133
P0, end ld_phase1, time=5.72071
P1, end ld_phase1, time=5.72074
P0, end ld_phase2, time=6.10486
lu_mpi look i=0 end
Proc:0 lbl:9 lu2_mpi i=1024
P0, enter rfact, time=6.10497
P1, end ld_phase2, time=6.17196
Proc:1 lbl:9 lu2_mpi i=1024
P1, enter rfact, time=6.17205
P2, end dls_phase_2, time=6.25827
P2, end lmat/dls, time=6.25834
P2, end mult_diag, time=6.26351
P3, end dls_phase_2, time=6.60163
P3, end lmat/dls, time=6.60171
P3, end mult_diag, time=6.60172
P3, end ld_phase1, time=6.61209
P2, end ld_phase1, time=6.61208
P2, end ld_phase2, time=6.99592
Proc:2 lbl:9 lu2_mpi i=1024
P2, enter rfact, time=6.99601
P2, end rfact, time=6.99603
P2, enter process_lmat, time=6.99604
P3, end ld_phase2, time=7.05003
Proc:3 lbl:9 lu2_mpi i=1024
P0, enter rfact, time=1.08472
P0, end rfact, time=1.08474
P0, enter process_lmat, time=1.08474
P0, end process_lmat, time=2.17647
P0, enter dls_phase_2, time=2.44743
P0, enter dls_phase_1, time=2.53638
P0, end dls_phase_1, time=3.13361
P0, end dls_phase_2, time=4.1648
P0, enter dls_phase_2, time=4.16489
P0, end dls_phase_2, time=5.22698
P0, end lmat/dls, time=5.22706
P0, end mult_diag, time=5.23219
P0, end ld_phase1, time=5.72071
P0, end ld_phase2, time=6.10486
P0, enter rfact, time=6.10497
全体では 7k x 7k の処理のはず。
5秒、ということは、20Gflops
まず、ld_phase1, ld_phase2 が遅い。
phase2 は 7K x 1k
P1, enter rfact, time=1.1538
P1, end rfact, time=1.15382
P1, enter process_lmat, time=1.15383
P1, end process_lmat, time=2.23979
P1, enter dls_phase_2, time=2.44747
P1, enter dls_phase_1, time=2.50974
P1, end dls_phase_1, time=3.13366
P1, end dls_phase_2, time=4.44376
P1, enter dls_phase_2, time=4.44384
P1, end dls_phase_2, time=5.71125
P1, end lmat/dls, time=5.71132
P1, end mult_diag, time=5.71133
P1, end ld_phase1, time=5.72074
P1, end ld_phase2, time=6.17196
P1, enter rfact, time=6.17205
ld_phase1 が遅いのは同期待ち。ちょっとしょうがない。
P1 で lmat/dls までの update が3.47 秒
演算は 7k*8k*1k*2 なので112、32Gflops で
Proc:0 lbl:1 Left bcast etc time=1.87688e+10 ops/cycle=0.00670416
Proc:0 lbl:1 update time=0 ops/cycle=nan
Proc:0 lbl:1 update matmul time=3.6811e+10 ops/cycle=6.00882
Proc:0 lbl:1 update swap+bcast time=5.22288e+09 ops/cycle=0.0140536
Proc:0 lbl:1 total time=9.63524e+10 ops/cycle=13.8184
Proc:0 lbl:1 rfact time=1.25559e+10 ops/cycle=0.0100215
Proc:0 lbl:1 dmul time=1.64496e+10 ops/cycle=14.6215
Proc:0 lbl:1 colum dec with trans time=2.26538e+09 ops/cycle=0.00186594
Proc:0 lbl:1 colum dec right time=4.55159e+09 ops/cycle=0.782644
Proc:0 lbl:1 colum dec left time=3.73074e+08 ops/cycle=0.0111547
Proc:0 lbl:1 rowtocol time=3.0961e+08 ops/cycle=0.108482
Proc:0 lbl:1 column dec in trans time=1.59991e+09 ops/cycle=0.167945
Proc:0 lbl:1 coltorow time=3.54852e+08 ops/cycle=0.0946514
Proc:0 lbl:1 dgemm8 time=2.65287e+08 ops/cycle=1.01187
Proc:0 lbl:1 dgemm16 time=7.53222e+07 ops/cycle=7.12766
Proc:0 lbl:1 dgemm32 time=9.76993e+07 ops/cycle=10.9903
Proc:0 lbl:1 dgemm64 time=1.6905e+08 ops/cycle=12.7033
Proc:0 lbl:1 dgemm128 time=2.95611e+08 ops/cycle=14.5291
Proc:0 lbl:1 main dgemm time=4.06385e+10 ops/cycle=14.8424
これだと、 DGEMM は性能ちゃんとでている。
P2, enter rfact, time=1.08562
P2, end rfact, time=2.09319
P2, enter process_lmat, time=2.09325
P2, end process_lmat, time=2.17647
現在は lookahead が全く効いていないので、この1秒は余計にかかる。これが
全部で10秒強。実際、nb=512 にすると 32秒まで減る。
-q 4 でやると
P0, enter rfact, time=0.577841
P1, enter rfact, time=0.636162
P2, enter rfact, time=0.640719
P3, enter rfact, time=0.640329
P0, end rfact, time=1.23126
P1, end rfact, time=1.28314
P2, end rfact, time=1.23137
P3, end rfact, time=1.2314
P0, enter process_lmat, time=1.23132
P1, enter process_lmat, time=1.2832
P2, enter process_lmat, time=1.23143
P3, enter process_lmat, time=1.23146
P0, end process_lmat, time=1.23732
P2, end process_lmat, time=1.2407
P3, end process_lmat, time=1.24076
P1, end process_lmat, time=1.28921
P0, enter dls_phase_2, time=1.50932
P1, enter dls_phase_2, time=1.50951
P2, enter dls_phase_2, time=1.5097
P3, enter dls_phase_2, time=1.50971
.....
P0, enter dls_phase_1, time=2.13702
P1, enter dls_phase_1, time=2.34734
P2, enter dls_phase_1, time=2.3566
P3, enter dls_phase_1, time=2.35692
P0, end dls_phase_1, time=2.57533
P1, end dls_phase_1, time=2.5755
P2, end dls_phase_1, time=2.5757
P3, end dls_phase_1, time=2.5757
P0, end dls_phase_1, time=4.60747
P1, end dls_phase_1, time=4.6076
P2, end dls_phase_1, time=4.60782
P3, end dls_phase_1, time=4.6078
P0, enter dls_phase_2, time=4.60753
P1, enter dls_phase_2, time=4.60766
P2, enter dls_phase_2, time=4.60788
P3, enter dls_phase_2, time=4.60787
P0, end dls_phase_2, time=4.92826
P1, end dls_phase_2, time=5.03466
P2, end dls_phase_2, time=5.03908
P3, end dls_phase_2, time=5.03856
P0, end lmat/dls, time=4.92833
P1, end lmat/dls, time=5.03472
P2, end lmat/dls, time=5.03915
P3, end lmat/dls, time=5.03863
P0, end mult_diag, time=4.93323
P1, end mult_diag, time=5.03474
P2, end mult_diag, time=5.03917
P3, end mult_diag, time=5.03865
P1, end ld_phase1, time=5.05114
P2, end ld_phase1, time=5.05143
P0, end ld_phase1, time=5.05163
P3, end ld_phase1, time=5.05155
P0, end ld_phase2, time=5.22186
P1, end ld_phase2, time=5.27762
P2, end ld_phase2, time=5.28182
P3, end ld_phase2, time=5.2847
P0, enter rfact, time=5.2341
この場合 total cpusec = 134.882 wsec=34.2573 85.5886 Gflops
1 ブロックの縦通信に 0.25 sec
1kx4k の交換と放送なので、データ 32MB,交換・放送全部で 100MB。ちょっと
遅いなあ、、、どっちが遅いか調べる必要あり。
これは、性能低下はほぼ縦通信のせい。
UCOMM concurrent にすると、、、
P0, enter rfact, time=0.576815
P1, enter rfact, time=0.634517
P2, enter rfact, time=0.638862
P3, enter rfact, time=0.63883
P0, end rfact, time=1.22598
P1, end rfact, time=1.27719
P2, end rfact, time=1.22609
P3, end rfact, time=1.22601
P0, enter process_lmat, time=1.22604
P1, enter process_lmat, time=1.27726
P2, enter process_lmat, time=1.22615
P3, enter process_lmat, time=1.22606
P0, end process_lmat, time=1.23207
P1, end process_lmat, time=1.28339
P2, end process_lmat, time=1.23549
P3, end process_lmat, time=1.23537
P0, enter dls_phase_2, time=1.49899
P1, enter dls_phase_2, time=1.49907
P2, enter dls_phase_2, time=1.49938
P3, enter dls_phase_2, time=1.49928
P0, enter dls_phase_1, time=1.57711
P1, enter dls_phase_1, time=1.57441
P2, enter dls_phase_1, time=1.52669
P3, enter dls_phase_1, time=1.51681
P0, end dls_phase_1, time=2.78974
P1, end dls_phase_1, time=2.78982
P2, end dls_phase_1, time=2.79013
P3, end dls_phase_1, time=2.79002
P0, end dls_phase_2, time=2.68907
P1, end dls_phase_2, time=2.96052
P2, end dls_phase_2, time=2.97092
P3, end dls_phase_2, time=2.98491
P0, enter dls_phase_2, time=2.78982
P0, enter dls_phase_1, time=2.80498
P1, enter dls_phase_2, time=2.96059
P2, enter dls_phase_2, time=2.971
P1, enter dls_phase_1, time=2.96061
P3, enter dls_phase_2, time=2.98499
P2, enter dls_phase_1, time=2.97102
P3, enter dls_phase_1, time=2.98501
P0, end dls_phase_2, time=4.07074
P0, end dls_phase_1, time=4.62141
P0, enter dls_phase_2, time=4.62149
P0, enter dls_phase_1, time=4.62152
P1, end dls_phase_1, time=4.62145
P3, end dls_phase_1, time=4.62163
P2, end dls_phase_1, time=4.62177
P1, end dls_phase_2, time=4.63459
P2, end dls_phase_2, time=4.64328
P1, enter dls_phase_2, time=4.63463
P3, end dls_phase_2, time=4.65067
P2, enter dls_phase_2, time=4.64335
P3, enter dls_phase_2, time=4.65075
P1, enter dls_phase_1, time=4.69193
P2, enter dls_phase_1, time=4.7082
P3, enter dls_phase_1, time=4.72529
P0, end dls_phase_2, time=5.87306
P0, end dls_phase_1, time=6.02621
P0, enter dls_phase_2, time=6.02628
P1, end dls_phase_1, time=6.08235
P3, end dls_phase_1, time=6.08256
P2, end dls_phase_1, time=6.08271
P3, end dls_phase_2, time=6.17353
P3, enter dls_phase_2, time=6.17362
P1, end dls_phase_2, time=6.17663
P1, enter dls_phase_2, time=6.17671
P2, end dls_phase_2, time=6.1799
P2, enter dls_phase_2, time=6.17998
P0, end dls_phase_2, time=6.34746
P0, end lmat/dls, time=6.34753
P0, end mult_diag, time=6.35239
P1, end dls_phase_2, time=6.60361
P1, end lmat/dls, time=6.60368
P1, end mult_diag, time=6.6037
P3, end dls_phase_2, time=6.60424
P3, end lmat/dls, time=6.60432
P3, end mult_diag, time=6.60433
P2, end dls_phase_2, time=6.61095
P2, end lmat/dls, time=6.61102
P2, end mult_diag, time=6.61104
P1, end ld_phase1, time=6.62298
P2, end ld_phase1, time=6.62339
P0, end ld_phase1, time=6.6236
P3, end ld_phase1, time=6.6234
P0, end ld_phase2, time=6.79389
lu_mpi look i=0 end
Proc:0 lbl:9 lu2_mpi i=1024
P0, enter rfact, time=6.79401
P1, end ld_phase2, time=6.84951
Proc:1 lbl:9 lu2_mpi i=1024
P1, enter rfact, time=6.8496
P3, end ld_phase2, time=6.85383
P2, end ld_phase2, time=6.85398
この時は、 main dgemm が 11 演算まで低下。
GOTOBLAS を 3 コア利用にすると
main dgemm が 8 演算まで低下
P0, enter rfact, time=1.94721
P1, enter rfact, time=2.34884
P2, enter rfact, time=2.4506
P3, enter rfact, time=2.45725
P0, end rfact, time=4.57804
P1, end rfact, time=4.74574
P2, end rfact, time=4.59528
P3, end rfact, time=4.59526
P0, enter process_lmat, time=4.5781
P1, enter process_lmat, time=4.77096
P2, enter process_lmat, time=4.59534
P3, enter process_lmat, time=4.59533
P0, end process_lmat, time=4.58409
P1, end process_lmat, time=4.77698
P2, end process_lmat, time=4.60473
P3, end process_lmat, time=4.60689
P0, enter dls_phase_2, time=5.19868
P1, enter dls_phase_2, time=5.21595
P2, enter dls_phase_2, time=5.21619
P3, enter dls_phase_2, time=5.21617
P0, enter dls_phase_1, time=5.30158
P1, enter dls_phase_1, time=5.51896
P2, enter dls_phase_1, time=5.57938
P3, enter dls_phase_1, time=5.45817
P0, end dls_phase_1, time=6.45967
P1, end dls_phase_1, time=6.47691
P2, end dls_phase_1, time=6.47717
P3, end dls_phase_1, time=6.47713
P0, end dls_phase_2, time=6.801
P1, end dls_phase_2, time=7.28947
P2, end dls_phase_2, time=8.23385
P3, end dls_phase_2, time=8.76145
P0, enter dls_phase_2, time=6.80106
P0, enter dls_phase_1, time=6.87134
P1, enter dls_phase_2, time=7.28954
P1, enter dls_phase_1, time=7.36571
P2, enter dls_phase_2, time=8.23394
P2, enter dls_phase_1, time=8.34096
P0, end dls_phase_2, time=8.52308
P3, enter dls_phase_2, time=8.76155
P3, enter dls_phase_1, time=8.87066
P1, end dls_phase_2, time=9.5336
P0, end dls_phase_1, time=9.66476
P3, end dls_phase_1, time=9.68214
P2, end dls_phase_1, time=9.68223
P1, end dls_phase_1, time=9.68196
P0, enter dls_phase_2, time=9.6649
P1, enter dls_phase_2, time=9.68203
P0, enter dls_phase_1, time=9.7369
P1, enter dls_phase_1, time=9.7643
P2, end dls_phase_2, time=11.1224
P2, enter dls_phase_2, time=11.1224
P2, enter dls_phase_1, time=11.2305
P0, end dls_phase_2, time=11.3787
8192, 512 で 4 core, no U, no L
問題は、これが問題かどうかか、、、、
u swap and bcast (dls phase 1) を見ると、 u conc では
交換と放送が同じくらいの時間
u no conc では
P0, enter dls_phase_1, time=0.376726
P1, enter dls_phase_1, time=0.403349
P2, enter dls_phase_1, time=0.404496
P3, enter dls_phase_1, time=0.404644
P0, end swap and scale, time=0.424477
P1, end swap and scale, time=0.42442
P2, end swap and scale, time=0.424464
P3, end swap and scale, time=0.424315
P0, end dls_phase_1, time=0.452557
P1, end dls_phase_1, time=0.452761
P2, end dls_phase_1, time=0.452937
P3, end dls_phase_1, time=0.452946
やはり同じくらい。
16384, 1024 に増やすと
P0, enter dls_phase_1, time=2.13792
P1, enter dls_phase_1, time=2.35066
P2, enter dls_phase_1, time=2.35625
P3, enter dls_phase_1, time=2.35607
P3, end swap and scale, time=2.41499
P0, end swap and scale, time=2.41538
P1, end swap and scale, time=2.41532
P2, end swap and scale, time=2.41529
P0, end dls_phase_1, time=2.57628
P1, end dls_phase_1, time=2.57644
P2, end dls_phase_1, time=2.57666
P3, end dls_phase_1, time=2.57665
放送がずっと増える。0.15 秒。
データサイズは 1Kx4K=32MB.
Bcast では駄目ということか?
mpiperftest の結果は
Process 0 of 4 on mgv01-01.jmlab3
Myid, R, L= 0 1 3
Process 1 of 4 on mgv01-02.jmlab3
Process 3 of 4 on mgv01-04.jmlab3
Process 2 of 4 on mgv01-03.jmlab3
Myid, R, L= 1 2 0
Myid, R, L= 3 0 2
Myid, R, L= 2 3 1
Barrier count = 2000 wall clock time = 0.022476 11.237979 us/synch
Allreduce count = 2000 wall clock time = 0.019526 9.763002 us/call
size, count = 1 2000 wall clock time = 0.025770 1.241756 MB/s
size, count = 1 2000 wall clock time = 0.016091 1.988676 MB/s
size, count = 4 2000 wall clock time = 0.013057 9.803176 MB/s
size, count = 4 2000 wall clock time = 0.001030 124.275674 MB/s
size, count = 16 2000 wall clock time = 0.014361 35.651758 MB/s
size, count = 16 2000 wall clock time = 0.001128 453.917491 MB/s
size, count = 64 2000 wall clock time = 0.013690 149.598304 MB/s
size, count = 64 2000 wall clock time = 0.001292 1585.151244 MB/s
size, count = 256 2000 wall clock time = 0.019727 415.268590 MB/s
size, count = 256 2000 wall clock time = 0.009870 829.985467 MB/s
size, count = 1024 2000 wall clock time = 0.035994 910.372614 MB/s
size, count = 1024 2000 wall clock time = 0.053348 614.230345 MB/s
size, count = 4096 1464 wall clock time = 0.087359 1098.281313 MB/s
size, count = 4096 1464 wall clock time = 0.169143 567.240299 MB/s
size, count = 16384 366 wall clock time = 0.069288 1384.722935 MB/s
size, count = 16384 366 wall clock time = 0.131129 731.681662 MB/s
size, count = 65536 91 wall clock time = 0.057393 1662.584101 MB/s
size, count = 65536 91 wall clock time = 0.073355 1300.803881 MB/s
size, count = 262144 22 wall clock time = 0.055728 1655.805994 MB/s
size, count = 262144 22 wall clock time = 0.067364 1369.792752 MB/s
size, count = 1048576 5 wall clock time = 0.048647 1724.386007 MB/s
size, count = 1048576 5 wall clock time = 0.059087 1419.703590 MB/s
size, count = 4194304 1 wall clock time = 0.036707 1828.234455 MB/s
size, count = 4194304 1 wall clock time = 0.046398 1446.376424 MB/s
下が放送。これは速いんだけどね、、、communicator が悪い?
Bcast をリングに修正
16384, 1024 no U, no L
P0, enter dls_phase_1, time=2.16033
P1, enter dls_phase_1, time=2.37283
P2, enter dls_phase_1, time=2.38085
P3, enter dls_phase_1, time=2.38197
P0, end swap and scale, time=2.44341
P1, end swap and scale, time=2.44336
P2, end swap and scale, time=2.44332
P3, end swap and scale, time=2.44301
P0, end dls_phase_1, time=2.61899
P1, end dls_phase_1, time=2.62099
P2, end dls_phase_1, time=2.62308
P3, end dls_phase_1, time=2.62307
OpenMPI 1.2.8 だと一応動く。
mympirun.csh 4 lu2_mpi -n 16384 -b 256 -p 2 -q 2
L U
X O cpusec = 101.041 wsec=27.6251 106.137 Gflops
O O cpusec = 104.121 wsec=28.5082 102.849 Gflops
X X cpusec = 97.4782 wsec=26.1979 111.919 Gflops
O X cpusec = 101.071 wsec=27.0379 108.442 Gflops
OX, 16384, 1024 の時(終わりまでいかないけど)
P0, enter dls_phase_1, time=3.48087
P0, end swap and scale, time=3.76133
P0, enter dls_phase_2, time=3.79983
P0, end dls_phase_2, time=4.91154
P0, end dls_phase_1, time=3.79977
P0, end lmat/dls, time=4.91161
P0, end mult_diag, time=4.91651
P0, end ld_phase1, time=5.07462
P1, end dls_phase_2, time=3.72695
P1, enter dls_phase_1, time=3.72701
P1, end swap and scale, time=3.76135
P1, end dls_phase_1, time=3.79981
P1, enter dls_phase_2, time=3.79987
P1, end dls_phase_2, time=5.06532
P2, end dls_phase_2, time=3.96963
P2, enter dls_phase_1, time=3.96969
P2, end swap and scale, time=4.21345
P2, end dls_phase_1, time=4.25173
P2, enter dls_phase_2, time=4.25179
P3, enter rfact, time=1.14245
P3, end swap and scale, time=1.15376
P3, end rfact, time=2.13269
P3, enter process_lmat, time=2.13277
P3, end process_lmat, time=2.44748
P3, end swap and scale, time=2.44969
P3, enter dls_phase_2, time=2.49871
P3, enter dls_phase_1, time=4.1792
P3, end dls_phase_2, time=4.17914
P3, end swap and scale, time=4.21345
P3, end dls_phase_1, time=4.25175
P3, enter dls_phase_2, time=4.2518
止まるのはどこでか?
-q 4 なら止まらない
-p 4 も止まらない
mympirun.csh 4 lu2_mpi -n 32768 -b 2048 -p 2 -q 2
だと
P0, end dls_phase_2, time=65.9501
P0, end lmat/dls, time=65.9502
P0, end mult_diag, time=65.9502
P0, end ld_phase1, time=65.987
P0, end ld_phase2, time=69.0456
P0, enter rfact, time=69.0457
P0, end rfact, time=69.0458
P0, enter process_lmat, time=69.0458
P0, end swap and scale, time=69.8742
P0, enter dls_phase_2, time=70.3877
P0, enter dls_phase_1, time=70.4037
Proc:0 lbl:9 call bcast acp2
P0, end process_lmat, time=79.7284
P0, end dls_phase_2, time=83.4916
というわけで、 process_lmat から戻っていない。
Proc:0 lbl:9 call bcast scalp2
Proc:0 lbl:9 call bcast acp2
P0, end dls_phase_2, time=133.557
ということで、もちろん acp2 で止まっている。
なので、 acp2 bcast を分割すれば動作するかも。
やはり、結局 MPI_THREADS_MULTIPLE が×なので修正しよう。
Proc:1 lbl:9 pvp[0]= 11
Proc:1 lbl:9 pvp[1]= 8
Proc:1 lbl:9 pvp[2]= 11
Proc:1 lbl:9 pvp[3]= 9
Proc:1 lbl:9 scalep2[0]= 1.672
Proc:1 lbl:9 scalep2[1]= -1.286
Proc:1 lbl:9 scalep2[2]= 1.105
Proc:1 lbl:9 scalep2[3]= -1.038
これは、通信の終了判定条件が全然間違っていただけ。
縦通信も同一スレッドでするのはどうか?
単純な実装:
pv はあるので、入れ替えについては各ノードは
HPL では "spread and roll"
24K くらいの時: 600Gflops として計算4秒
通信: 384MB しかない。U がちゃんと動けば1秒、Lはもっと少ない。
なので、非同期にするまでもなくオーバーラップできれば全く問題ない。
その割には HPL が遅いのは? laswp が 300秒で、本当は 100秒程度であって
欲しい。
mpirun --mca btl tcp,self -np 2 lu2_mpi -p 2 -b 1024 -n 16384 -g
P0, enter rfact, time=3.08102
P0, end rfact, time=3.08105
P0, enter process_row_comm_init, time=3.08109
P0, end process_row_comm_init, time=3.08124
P0, end swap and scale, time=3.1008
P0, enter dls_phase_2, time=3.11081
P0, end dls_phase_2, time=9.39419
P0, enter dls_phase_1, time=9.39425
P0, end swap and scale, time=9.40783
P0, end dls_phase_1, time=9.41532
P0, enter dls_phase_2, time=9.41565
P0, end dls_phase_2, time=14.1633
P1, enter rfact, time=3.08065
P1, end swap and scale, time=3.0858
P1, end rfact, time=5.9393
P1, enter process_row_comm_init, time=5.93938
P1, end process_row_comm_init, time=5.97405
P1, end swap and scale, time=5.99211
P1, enter dls_phase_2, time=6.00183
P1, end dls_phase_2, time=12.2958
P1, enter dls_phase_1, time=12.2958
P1, end swap and scale, time=12.3094
P1, end dls_phase_1, time=12.317
P1, enter dls_phase_2, time=12.3176
小池君版 DGEMM の動作を解析。
void set_j_matrix(int m, int k, int LDB, int NOTB, double b[][LDB], int location_id)
は
void send_j_matrix_mt_mloc(int DIMN, int DIMK, int LDB, int NOTB, double *b, int locid)
を呼ぶだけ。さらに mtwork が呼ばれて、結局
えーと、しないといけないことが2つあるのか。
testdgemm の使い方
testdgemm M N K 1 : 普通のテストらしい。
GotoBLAS2 にすると小池ライブラリのマルチスレッドのところが全て動かなく
なるだけでなく、OpenMP で書いたところまでおかしくなる。
実験: 小池ライブラリのスレッド部分を使わないようにしてみる。
結局、 GotoBLAS2 の Makefile.rule で USE_OPENMP かなにかを設定するとOK
みたい。
で、なんだか微妙に遅い。
lu2 からの例
NA:1 NB:1 (4097, 2048, 2048) a=1.000000e+00 b=0.000000e+00 LDA=8192 LDB=2048 LDC=8208
mrem=1, mblk=4096
nrem=0, nblk=2048
overlapped dgemm
M=4096 N=2048 K=2048 ip=1.088508e-02 jp=2.011572e-02 fo=7.626076e-02 all=1.072616e-01 320.34 GFlops
gdr_dgemm elapsed : 1.195158e-01 [sec]
gdrflag=1
dgemm M=2048 N=4097 K=2048 time= 0.1194 287.84 Gflops
そうでもない。
-l 4:
M=4096 N=2048 K=2048 ip=1.391726e-02 jp=3.531383e-02 fo=7.785494e-02 all=1.270860e-01 270.37 GFlops
M=4096 N=2048 K=2048 ip=1.087428e-02 jp=2.008971e-02 fo=7.766123e-02 all=1.086252e-01 316.31 GFlops
M=4096 N=2048 K=2048 ip=1.113970e-02 jp=2.009294e-02 fo=7.775368e-02 all=1.089863e-01 315.27 GFlops
M=4096 N=2048 K=2048 ip=1.095724e-02 jp=2.010076e-02 fo=7.764485e-02 all=1.087028e-01 316.09 GFlops
2k x 2k jp 0.035 sec 900MB/s
2k x 4k jp 0.020 sec 1600MB/s
4k x 4k jp 0.040 sec 1600MB/s
6k x 6k jp 0.060 sec 1600MB/s
N=16384
USE_OPENMP=1
NO_AFFINITY=1
Emax= 2.374e-07
Nswap=0 cpsec = 48.0747 wsec=19.6257 149.398 Gflops
swaprows time=6.66789e+08 ops/cycle=0.20129
scalerow time=5.91182e+07 ops/cycle=2.27033
trans rtoc time=5.06574e+08 ops/cycle=0.264952
trans ctor time=4.18469e+08 ops/cycle=0.320735
trans mmul time=1.71136e+09 ops/cycle=1.17641
trans nonrec cdec time=2.99646e+08 ops/cycle=0.447921
trans vvmul time=1.0796e+08 ops/cycle=1.24322
trans findp time=1.9111e+08 ops/cycle=0.702306
solve tri u time=6.60475e+09 ops/cycle=2.48064e-06
solve tri time=7.20799e+09 ops/cycle=76.2704
matmul nk8 time=0 ops/cycle=inf
matmul snk time=217988 ops/cycle=9851.38
trans mmul8 time=9.15297e+08 ops/cycle=1.17311
trans mmul4 time=4.58596e+08 ops/cycle=1.17068
trans mmul2 time=3.36537e+08 ops/cycle=0.797641
DGEMM2K time=1.68347e+10 ops/cycle=190.494
DGEMM1K time=1.41048e+10 ops/cycle=9.74411
DGEMM512 time=7.3349e+09 ops/cycle=9.36884
DGEMMrest time=8.90348e+09 ops/cycle=7.71827
USE_OPENMP=0
NO_AFFINITY=0
Emax= 2.374e-07
Nswap=0 cpsec = 48.1877 wsec=17.5334 167.225 Gflops
swaprows time=6.65453e+08 ops/cycle=0.201694
scalerow time=5.89594e+07 ops/cycle=2.27644
trans rtoc time=5.10242e+08 ops/cycle=0.263047
trans ctor time=4.19393e+08 ops/cycle=0.320028
trans mmul time=1.71097e+09 ops/cycle=1.17668
trans nonrec cdec time=2.99579e+08 ops/cycle=0.448021
trans vvmul time=1.07871e+08 ops/cycle=1.24425
trans findp time=1.91152e+08 ops/cycle=0.702152
solve tri u time=4.99858e+09 ops/cycle=3.27773e-06
solve tri time=6.67427e+09 ops/cycle=82.3695
matmul nk8 time=0 ops/cycle=inf
matmul snk time=219356 ops/cycle=9789.95
trans mmul8 time=9.15089e+08 ops/cycle=1.17337
trans mmul4 time=4.58442e+08 ops/cycle=1.17108
trans mmul2 time=3.36517e+08 ops/cycle=0.797687
DGEMM2K time=1.68649e+10 ops/cycle=157.555
DGEMM1K time=1.26718e+10 ops/cycle=10.846
DGEMM512 time=5.83867e+09 ops/cycle=11.7697
DGEMMrest time=6.20703e+09 ops/cycle=11.0712
あれ?ちゃんと動くのは何故?
Pthread にしても問題ないような、、、
一旦 K=2048 でなめたあとだと K=512 でも動く。
N=34816 での数字
Emax= 1.024e-07
Nswap=0 cpsec = 128.054 wsec=76.7772 366.449 Gflops
swaprows time=2.78637e+09 ops/cycle=0.217515
scalerow time=1.22894e+08 ops/cycle=4.93172
trans rtoc time=2.85771e+09 ops/cycle=0.212085
trans ctor time=1.87305e+09 ops/cycle=0.323578
trans mmul time=7.66739e+09 ops/cycle=1.18569
trans nonrec cdec time=1.36951e+09 ops/cycle=0.44255
trans vvmul time=4.94341e+08 ops/cycle=1.22603
trans findp time=8.71903e+08 ops/cycle=0.69512
solve tri u time=7.21406e+09 ops/cycle=4.82613e-06
solve tri time=2.32784e+10 ops/cycle=106.643
matmul nk8 time=0 ops/cycle=inf
matmul snk time=66936 ops/cycle=144873
trans mmul8 time=4.14471e+09 ops/cycle=1.16983
trans mmul4 time=2.07339e+09 ops/cycle=1.16925
trans mmul2 time=1.44732e+09 ops/cycle=0.837517
DGEMM2K time=1.33555e+11 ops/cycle=201.368
DGEMM1K time=1.2037e+10 ops/cycle=51.5594
DGEMM512 time=1.19811e+10 ops/cycle=25.9001
DGEMMrest time=2.49127e+10 ops/cycle=12.4559
Emax= 1.201e-07
Nswap=0 cpsec = 128.142 wsec=74.9283 375.491 Gflops
swaprows time=2.79203e+09 ops/cycle=0.217074
scalerow time=1.27818e+08 ops/cycle=4.74173
trans rtoc time=2.84709e+09 ops/cycle=0.212876
trans ctor time=8.70454e+08 ops/cycle=0.696277
trans mmul time=3.65435e+09 ops/cycle=2.48776
trans nonrec cdec time=1.40978e+09 ops/cycle=0.42991
trans vvmul time=5.01347e+08 ops/cycle=1.2089
trans findp time=8.94912e+08 ops/cycle=0.677247
solve tri u time=7.26317e+09 ops/cycle=4.7935e-06
solve tri time=2.32356e+10 ops/cycle=106.84
matmul nk8 time=0 ops/cycle=inf
matmul snk time=46284 ops/cycle=209516
trans mmul8 time=1.10937e+09 ops/cycle=4.37059
trans mmul4 time=1.07647e+09 ops/cycle=2.25209
trans mmul2 time=1.46227e+09 ops/cycle=0.828953
DGEMM2K time=1.33621e+11 ops/cycle=201.268
DGEMM1K time=1.19399e+10 ops/cycle=51.9789
DGEMM512 time=1.19685e+10 ops/cycle=25.9274
DGEMMrest time=2.49315e+10 ops/cycle=12.4466
Emax= 0.000e+00
Nswap=0 cpsec = 128.453 wsec=73.8856 380.79 Gflops
swaprows time=1.41181e+09 ops/cycle=0.42929
scalerow time=2.19263e+09 ops/cycle=0.276415
trans rtoc time=1.76292e+09 ops/cycle=0.343792
trans ctor time=8.81693e+08 ops/cycle=0.687401
trans mmul time=3.68061e+09 ops/cycle=2.47001
trans nonrec cdec time=1.4209e+09 ops/cycle=0.426543
trans vvmul time=5.06208e+08 ops/cycle=1.19729
trans findp time=9.02203e+08 ops/cycle=0.671775
solve tri u time=6.95164e+09 ops/cycle=5.00831e-06
solve tri time=2.31938e+10 ops/cycle=107.032
matmul nk8 time=0 ops/cycle=inf
matmul snk time=64708 ops/cycle=149861
trans mmul8 time=1.13306e+09 ops/cycle=4.27921
trans mmul4 time=1.0784e+09 ops/cycle=2.24807
trans mmul2 time=1.46345e+09 ops/cycle=0.828286
DGEMM2K time=1.33447e+11 ops/cycle=201.53
DGEMM1K time=1.17584e+10 ops/cycle=52.7814
DGEMM512 time=1.19171e+10 ops/cycle=26.0391
DGEMMrest time=2.48778e+10 ops/cycle=12.4734
testdgemm2:
M=8192 N=8192 K=2048 ip=1.592984e-02 jp=8.143597e-02 fo=4.544182e-01 all=5.517840e-01 498.16 GFlops
M=8192 N=4096 K=2048 ip=1.578319e-02 jp=4.071313e-02 fo=2.551323e-01 all=3.116286e-01 441.03 GFlops
M=8192 N=2048 K=2048 ip=1.592580e-02 jp=2.040600e-02 fo=1.555027e-01 all=1.918345e-01 358.22 GFlops
M=8192 N=1024 K=1024 ip=1.277345e-02 jp=5.528171e-03 fo=8.028180e-02 all=9.858342e-02 174.27 GFlops
M=4096 N=1024 K=1024 ip=7.114475e-03 jp=5.504805e-03 fo=4.014735e-02 all=5.276663e-02 162.79 GFlops
M=2048 N=1024 K=1024 ip=4.347098e-03 jp=5.508406e-03 fo=2.007370e-02 all=2.992920e-02 143.50 GFlops
M=1024 N=1024 K=1024 ip=4.942499e-03 jp=1.013344e-02 fo=1.003534e-02 all=2.511127e-02 85.52 GFlops
M=8192 N=512 K=512 ip=7.118638e-03 jp=1.583843e-03 fo=4.267951e-02 all=5.138199e-02 83.59 GFlops
M=4096 N=512 K=512 ip=3.835795e-03 jp=1.580234e-03 fo=2.134295e-02 all=2.675898e-02 80.25 GFlops
M=2048 N=512 K=512 ip=2.492580e-03 jp=1.653200e-03 fo=1.067285e-02 all=1.481863e-02 72.46 GFlops
M=1024 N=512 K=512 ip=1.790577e-03 jp=1.625294e-03 fo=5.337515e-03 all=8.753386e-03 61.33 GFlops
M=512 N=512 K=512 ip=1.439678e-03 jp=1.620455e-03 fo=2.666733e-03 all=5.726866e-03 46.87 GFlops
M N K IP JP FO ALL Gflops
8192 8192 2048 1.592984e-02 8.143597e-02 4.544182e-01 5.517840e-01 498.16
8192 4096 2048 1.578319e-02 4.071313e-02 2.551323e-01 3.116286e-01 441.03
8192 2048 2048 1.592580e-02 2.040600e-02 1.555027e-01 1.918345e-01 358.22
4096 2048 2048 9.295550e-03 2.039877e-02 7.788696e-02 1.075813e-01 319.38
2048 2048 2048 6.399940e-03 2.037454e-02 3.890203e-02 6.567650e-02 261.58
8192 1024 1024 1.277345e-02 5.528171e-03 8.028180e-02 9.858342e-02 174.27
4096 1024 1024 7.114475e-03 5.504805e-03 4.014735e-02 5.276663e-02 162.79
2048 1024 1024 4.347098e-03 5.508406e-03 2.007370e-02 2.992920e-02 143.50
1024 1024 1024 4.942499e-03 1.013344e-02 1.003534e-02 2.511127e-02 85.52
8192 512 512 7.118638e-03 1.583843e-03 4.267951e-02 5.138199e-02 83.59
4096 512 512 3.835795e-03 1.580234e-03 2.134295e-02 2.675898e-02 80.25
2048 512 512 2.492580e-03 1.653200e-03 1.067285e-02 1.481863e-02 72.46
1024 512 512 1.790577e-03 1.625294e-03 5.337515e-03 8.753386e-03 61.33
512 512 512 1.439678e-03 1.620455e-03 2.666733e-03 5.726866e-03 46.87
DGEMM512 トータルで5秒
M=512 138回、1秒。
NOTI=NOTJ=0
M=8192 N=512 K=512 ip=6.408240e-03 jp=1.614339e-03 fo=6.201744e-02 all=7.004002e-02 61.32 GFlops
もちろんもっと遅い。
lu2_mpi_gdr reset_gdr でこける。なんか行列サイズがおかしい?
それ以前に、 UCOMM on にすると、 lu2_mpi_gdr では答があわなくなる、、、
ええええ、、、
OpenMPI 1.2.8 (tread)では×
procid=0 *a, *ar2 size offset worksize= 7f0693e00000 7f0794600000 7f07b4a00000 7f07f5200000 7f0805600000 100800000 171800000 10400000
[mgv01-01:02883] Failing at address: 0x7f0815a00000
上の行列サイズがおかしいのは修正した。
q=4 で bcast_umat の中で止まる。その前の通信がおかしい?
Proc:0 lbl:9 send data 10240 1
Proc:0 lbl:9 send data end 10240 1
Proc:0 lbl:9 send data 10240 1
Proc:0 lbl:9 send data end 10240 1
Proc:0 lbl:9 send data 10240 1
Proc:1 lbl:9 recieve data 10240 0
Proc:1 lbl:9 recieve data end 10240 0
Proc:1 lbl:9 send data 10240 2
Proc:1 lbl:9 send data end 10240 2
Proc:1 lbl:9 recieve data 10240 0
Proc:1 lbl:9 recieve data end 10240 0
Proc:1 lbl:9 send data 10240 2
Proc:2 lbl:9 recieve data 10240 1
Proc:2 lbl:9 recieve data end 10240 1
Proc:2 lbl:9 send data 10240 3
Proc:3 lbl:9 recieve data 10240 2
数はあっているけど 2->3 がおわっていない。何故?
lu2 32k
hugepage: 364.13 Gflops
no hugepage 349.03 Gflops
結構違うのね、、、うーん。
まあ、しょうがないのでとりあえず huge page にしないということで。
今度は別の MPI_Bcast で止まる。うーん?
とりあえず、
/usr2/makino/PDS/openmpi133/bin/mpirun \
そういう問題?むしろ、スイッチの温度とか?
checksum をみたら、3 ノードの計算 123, 125 で、
*** 465,474 ****
という感じで入力行列、しかも放送されたほうが間違っている。うーん。
mvapich-1.1.0 にしてみる。
これ多分デフォルトでは tcp 使ってるな、、、
いや、そんなことはなかった。
lu2_gdr:
NA:1 NB:1 (4097, 2048, 2048) a=1.000000e+00 b=0.000000e+00 LDA=8192 LDB=2048 LDC=8208
mrem=1, mblk=4096
nrem=0, nblk=2048
overlapped dgemm
M=4096 N=2048 K=2048 ip=1.143002e-02 jp=2.032090e-02 fo=7.639036e-02 all=1.081413e-01 317.73 GFlops
gdr_dgemm elapsed : 1.204371e-01 [sec]
gdrflag=1
dgemm M=2048 N=4097 K=2048 time= 0.1203 285.635 Gflops
NA:1 NB:1 (4097, 4096, 2048) a=-1.000000e+00 b=1.000000e+00 LDA=8208 LDB=8208 LDC=8208
mrem=1, mblk=4096
nrem=0, nblk=4096
overlapped dgemm
M=4096 N=4096 K=2048 ip=1.484500e-02 jp=4.057029e-02 fo=1.262614e-01 all=1.816767e-01 378.25 GFlops
gdr_dgemm elapsed : 1.870350e-01 [sec]
gdrflag=1
dgemm M=4096 N=4097 K=2048 time= 0.1869 367.867 Gflops
NA:1 NB:1 (512, 512, 512) a=1.000000e+00 b=0.000000e+00 LDA=8192 LDB=512 LDC=8208
mrem=0, mblk=512
nrem=0, nblk=512
overlapped dgemm
M=512 N=512 K=512 ip=2.594921e-03 jp=3.112463e-03 fo=2.479324e-03 all=8.186709e-03 32.79 GFlops
gdr_dgemm elapsed : 8.739453e-03 [sec]
gdrflag=1
dgemm M=512 N=512 K=512 time= 0.008799 30.5072 Gflops
NA:1 NB:1 (512, 3584, 512) a=-1.000000e+00 b=1.000000e+00 LDA=8208 LDB=8208 LDC=8208
mrem=0, mblk=512
nrem=0, nblk=3584
overlapped dgemm
A->j B->i NOTI=0 NOTJ=0 LDA=8208 LDB=8208 LDC=8208
M=3584 N=512 K=512 ip=6.339491e-03 jp=3.108838e-03 fo=1.809630e-02 all=2.754463e-02 68.22 GFlops
lu2_mpi_gdr
NA:1 NB:1 (2048, 6144, 2048) a=-1.000000e+00 b=1.000000e+00 LDA=2048 LDB=2048 LDC=4112
Proc:1 lbl:9 end bcast_umat
mrem=0, mblk=2048
nrem=0, nblk=6144
overlapped dgemm
A->j B->i NOTI=0 NOTJ=0 LDA=2048 LDB=2048 LDC=4112
gdrflag=1
M=14336 N=2048 K=2048 ip=9.655352e-02 jp=7.023237e-02 fo=4.239722e-01 all=5.907581e-01 203.57 GFlops
gdr_dgemm elapsed : 6.298326e-01 [sec]
dgemm M=14336 N=2048 K=2048 time= 0.6292 191.126 Gflops
P2, end ld_phase2, time=17.9938
Proc:2 lbl:9 lu2_mpi i=8192
P2, enter rfact, time=17.9938
P2, end rfact, time=17.9938
Proc:2 lbl:9 call process_row_comm
P2, enter process_row_comm_init, time=17.9939
P2, end process_row_comm_init, time=17.9939
NA:1 NB:1 (2064, 6144, 2048) a=-1.000000e+00 b=1.000000e+00 LDA=2064 LDB=2048 LDC=4112
Proc:3 lbl:9 end bcast_umat
Proc:3 lbl:9 using_dls, cs=2048, rcomm=98
P3, enter dls_phase_2, time=17.998
mrem=16, mblk=2048
nrem=0, nblk=6144
P2, end swap and scale, time=18.0113
overlapped dgemm
A->j B->i NOTI=0 NOTJ=0 LDA=2064 LDB=2048 LDC=4112
Proc:2 lbl:9 source=0, mypos=0 left=0 right=0
NA:1 NB:1 (2064, 6144, 2048) a=-1.000000e+00 b=1.000000e+00 LDA=2064 LDB=2048 LDC=4112
Proc:2 lbl:9 end bcast_umat
Proc:2 lbl:9 using_dls, cs=2048, rcomm=98
P2, enter dls_phase_2, time=18.0212
mrem=16, mblk=2048
nrem=0, nblk=6144
overlapped dgemm
A->j B->i NOTI=0 NOTJ=0 LDA=2064 LDB=2048 LDC=4112
gdrflag=1
M=6144 N=2048 K=2048 ip=4.573532e-02 jp=7.018384e-02 fo=1.570929e-01 all=2.730121e-01 188.78 GFlops
dgemm M=6144 N=2048 K=2048 time= 0.2728 188.93 Gflops
gdr_dgemm elapsed : 2.730544e-01 [sec]
gdrflag=1
M=6144 N=2048 K=2048 ip=4.570380e-02 jp=7.037145e-02 fo=1.556249e-01 all=2.717001e-01 189.69 GFlops
dgemm M=6144 N=2064 K=2048 time= 0.2855 181.922 Gflops
P3, end dls_phase_2, time=18.2836
gdr_dgemm elapsed : 2.857904e-01 [sec]
gdrflag=1
M=6144 N=2048 K=2048 ip=4.595182e-02 jp=7.032696e-02 fo=1.590896e-01 all=2.753684e-01 187.17 GFlops
dgemm M=6144 N=2064 K=2048 time= 0.2901 179.063 Gflops
P2, end dls_phase_2, time=18.3113
gdr_dgemm elapsed : 2.903524e-01 [sec]
NA:1 NB:1 (512, 512, 512) a=1.000000e+00 b=0.000000e+00 LDA=512 LDB=512 LDC=4112
mrem=0, mblk=512
nrem=0, nblk=512
overlapped dgemm
gdrflag=1
M=512 N=512 K=512 ip=4.979249e-03 jp=6.214275e-03 fo=2.856935e-03 all=1.405046e-02 19.11 GFlops
dgemm M=512 N=512 K=512 time= 0.01436 18.6983 Gflops
問題点:
1)A->j B->i NOTI=0 NOTJ=0 LDA=2048 LDB=2048 LDC=4112
non-mpi
M=4096 N=2048 K=2048 ip=1.143002e-02 jp=2.032090e-02 fo=7.639036e-02 all=1.081413e-01 317.73 GFlops
ip が4倍、jp も 2 倍以上、 fo が、これは3割増しくらい(行列サイズが1.5倍)
2) そういうのなくても M=N=K=512 が異常に遅い
NA:1 NB:1 (512, 512, 512) a=1.000000e+00 b=0.000000e+00 LDA=512 LDB=512 LDC=4112
M=512 N=512 K=512 ip=4.979249e-03 jp=6.214275e-03 fo=2.856935e-03 all=1.405046e-02 19.11 GFlops
NA:1 NB:1 (512, 512, 512) a=1.000000e+00 b=0.000000e+00 LDA=8192 LDB=512 LDC=8208
overlapped dgemm
M=512 N=512 K=512 ip=2.594921e-03 jp=3.112463e-03 fo=2.479324e-03 all=8.186709e-03 32.79 GFlops
上は mvapich-1.1.0 の場合。
mvapich で遅かったのは processor affinity の設定のせい
/usr/mpi/gcc/mvapich-1.1.0/bin/mpirun_rsh -rsh -hostfile ${cwd}/myhostfile -np $np VIADEV_USE_AFFINITY=0 $*
で一応大丈夫。計算間違いもしないと。
-p 2 -q 2 だとどっかで止まる。これは対応必要
Proc:1 lbl:9 numprocs = 2
Proc:0 lbl:9 numprocs = 2
Proc:0 lbl:9 end bcast_umat
Proc:1 lbl:9 end bcast_umat
Proc:0 lbl:9 using_dls, cs=8192, rcomm=2
P0, enter dls_phase_2, time=11.8669
Proc:0 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
gdrflag=0
Proc:0 lbl:9 dgemm M=0 N=16 K=2048 time= 1.478e-05 0 Gflops
P0, end dls_phase_2, time=11.867
Proc:0 lbl:9 end process_right_part_... 12288 :P0
Proc:1 lbl:9 using_dls, cs=8192, rcomm=34
P1, enter dls_phase_2, time=11.8668
Proc:1 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
gdrflag=0
Proc:1 lbl:9 dgemm M=2048 N=16 K=2048 time= 0.004495 29.8584 Gflops
P1, end dls_phase_2, time=11.8713
Proc:1 lbl:9 end process_right_part_... 12288 :P1
P3, end swap and scale, time=12.0416
Proc:3 lbl:9 numprocs = 2
P2, end swap and scale, time=12.0413
Proc:2 lbl:9 numprocs = 2
Proc:2 lbl:9 end bcast_umat
Proc:3 lbl:9 end bcast_umat
Proc:2 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
gdrflag=0
Proc:3 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
NA:1 NB:1 (2048, 2048, 2048) a=-1.000000e+00 b=1.000000e+00 LDA=2048 LDB=2048 LDC=8208
mrem=0, mblk=2048
nrem=0, nblk=2048
overlapped dgemm
Proc:2 lbl:9 dgemm M=0 N=2048 K=2048 time= 1.788e-05 0 Gflops
gdr_dgemm elapsed : 6.616713e-02 [sec]
gdrflag=1
Proc:3 lbl:9 dgemm M=2048 N=2048 K=2048 time= 0.06615 259.707 Gflops
2, 3: bcast umat の次の DGEMM?
P2, P3 だけ抜いてみると
Proc:2 lbl:9 numprocs = 2
Proc:2 lbl:9 end bcast_umat
Proc:2 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
Proc:2 lbl:9 dgemm M=0 N=2048 K=2048 time= 1.717e-05 0 Gflops
P3, end ld_phase2, time=11.616
Proc:3 lbl:9 lu2_mpi i=12288
P3, enter rfact, time=11.616
Proc:3 lbl:9 rfact, ii, nb=14336 2048
P3, end swap and scale, time=11.7964
Proc:3 lbl:9 numprocs = 2
Proc:3 lbl:9 end bcast_umat
Proc:3 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
Proc:3 lbl:9 dgemm M=2048 N=2048 K=2048 time= 0.06622 259.448 Gflops
Proc:2 lbl:9 coldec trans i=15361 find pivot end
Proc:2 lbl:9 coldec trans i=15361 swap rows end
Proc:2 lbl:9 coldec trans i=15361 scale rows end
Proc:2 lbl:9 coldec trans i=15361 call update
Proc:2 lbl:9 coldec trans i=15361 update end
Proc:2 lbl:9 coldec trans i=15362
Proc:2 lbl:9 coldec trans i=15362 find pivot end
Proc:2 lbl:9 coldec trans i=15362 swap rows end
Proc:2 lbl:9 coldec trans i=15362 scale rows end
Proc:2 lbl:9 coldec trans i=15362 call update
Proc:2 lbl:9 coldec trans i=15362 update end
Proc:2 lbl:9 coldec trans i=15363
Proc:2 lbl:9 coldec trans i=15363 find pivot end
Proc:3 lbl:9 coldec trans i=15362 find pivot end
Proc:3 lbl:9 coldec trans i=15362 swap rows end
Proc:3 lbl:9 coldec trans i=15362 scale rows end
Proc:3 lbl:9 coldec trans i=15362 call update
Proc:3 lbl:9 coldec trans i=15362 update end
Proc:3 lbl:9 coldec trans i=15363
Proc:3 lbl:9 coldec trans i=15363 find pivot end
Proc:3 lbl:9 coldec trans i=15363 swap rows end
Proc:3 lbl:9 coldec trans i=15363 scale rows end
Proc:3 lbl:9 coldec trans i=15363 call update
Proc:3 lbl:9 coldec trans i=15363 update end
Proc:3 lbl:9 coldec trans i=15364
つまり、Proc 2 が swap rows で止まっている。
Proc:2 lbl:9 coldec trans i=15362 swap rows end
Proc:2 lbl:9 coldec trans i=15362 scale rows end
Proc:2 lbl:9 coldec trans i=15362 call update
Proc:2 lbl:9 coldec trans i=15362 update end
Proc:2 lbl:9 coldec trans i=15363
Proc:2 lbl:9 coldec trans i=15363 imax=16384 find pivot end
Proc:3 lbl:9 swap_rows_transposed end
Proc:3 lbl:9 coldec trans i=15362 swap rows end
Proc:3 lbl:9 coldec trans i=15362 scale rows end
Proc:3 lbl:9 coldec trans i=15362 call update
Proc:3 lbl:9 coldec trans i=15362 update end
Proc:3 lbl:9 coldec trans i=15363
Proc:3 lbl:9 coldec trans i=15363 imax=16346 find pivot end
で、 imax が何故か違う。
これは、 サイズ0で idmax を呼んでたのが悪かった。
P1, end rfact, time=4.09239
Proc:1 lbl:9 call process_row_comm
P1, enter process_row_comm_init, time=4.0924
P1, end process_row_comm_init, time=4.09256
Proc:1 lbl:9 call process_right_part_... 0
Proc:1 lbl:9 using_dls call first phase1
gdrflag=1
gdr_dgemm elapsed : 6.066865e-01 [sec]
Proc:3 lbl:9 dgemm M=24576 N=2048 K=2048 time= 0.6062 340.105 Gflops
Proc:3 lbl:9 end MP_calculate ld
Proc:3 lbl:9 lu2_mpi i=0
P3, enter rfact, time=4.09852
Proc:3 lbl:9 rfact call dls_phase1, ii, nb=2048 2048
P2, end swap and scale, time=4.21813
P3, end swap and scale, time=4.21823
Proc:3 lbl:9 numprocs = 2
Proc:2 lbl:9 numprocs = 2
Proc:2 lbl:9 end bcast_umat
Proc:3 lbl:9 end bcast_umat
Proc:3 lbl:9 rfact call dls_phase2, ii, nb=2048 2048
Proc:3 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
NA:1 NB:1 (2048, 24576, 2048) a=-1.000000e+00 b=1.000000e+00 LDA=2048 LDB=2048 LDC=24592
Proc:2 lbl:9 rfact call dls_phase2, ii, nb=2048 2048
Proc:2 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
NA:1 NB:1 (2048, 22528, 2048) a=-1.000000e+00 b=1.000000e+00 LDA=2048 LDB=2048 LDC=24592
mrem=0, mblk=2048
nrem=0, nblk=24576
overlapped dgemm
A->j B->i NOTI=0 NOTJ=0 LDA=2048 LDB=2048 LDC=24592
mrem=0, mblk=2048
nrem=0, nblk=22528
overlapped dgemm
A->j B->i NOTI=0 NOTJ=0 LDA=2048 LDB=2048 LDC=24592
P1, end swap and scale, time=4.57918
P0, end swap and scale, time=4.57926
Proc:1 lbl:9 numprocs = 2
Proc:0 lbl:9 numprocs = 2
gdr_dgemm elapsed : 5.218667e-01 [sec]
gdrflag=1
Proc:2 lbl:9 dgemm M=22528 N=2048 K=2048 time= 0.5214 362.458 Gflops
Proc:2 lbl:9 rfact call column_dec ii, nb=2048 2048
gdr_dgemm elapsed : 5.523926e-01 [sec]
gdrflag=1
Proc:3 lbl:9 dgemm M=24576 N=2048 K=2048 time= 0.5519 373.555 Gflops
Proc:3 lbl:9 rfact call column_dec ii, nb=2048 2048
Proc:0 lbl:9 end bcast_umat
Proc:1 lbl:9 end bcast_umat
Proc:0 lbl:9 using_dls end first phase1
Proc:0 lbl:9 using_dls call local_check_and_continue_rcomm
Proc:0 lbl:9 using_dls, cs=2048, rcomm=354
P0, enter dls_phase_2, time=4.95189
Proc:0 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
NA:1 NB:1 (22544, 22528, 2048) a=-1.000000e+00 b=1.000000e+00 LDA=22544 LDB=2048 LDC=24592
mrem=16, mblk=22528
nrem=0, nblk=22528
Proc:1 lbl:9 using_dls end first phase1
Proc:1 lbl:9 using_dls call local_check_and_continue_rcomm
NA:1 NB:1 (22544, 24576, 2048) a=-1.000000e+00 b=1.000000e+00 LDA=22544 LDB=2048 LDC=24592
Proc:1 lbl:9 using_dls, cs=2048, rcomm=386
P1, enter dls_phase_2, time=4.9518
Proc:1 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
mrem=16, mblk=22528
nrem=0, nblk=24576
overlapped dgemm
overlapped dgemm
A->j B->i NOTI=0 NOTJ=0 LDA=22544 LDB=2048 LDC=24592
Proc:3 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
NA:1 NB:1 (512, 512, 512) a=1.000000e+00 b=0.000000e+00 LDA=512 LDB=512 LDC=24592
mrem=0, mblk=512
nrem=0, nblk=512
overlapped dgemm
gdrflag=1
gdr_dgemm elapsed : 5.888301e-03 [sec]
Proc:3 lbl:9 dgemm M=512 N=512 K=512 time= 0.005962 45.0243 Gflops
Proc:2 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
NA:1 NB:1 (512, 22528, 512) a=-1.000000e+00 b=1.000000e+00 LDA=512 LDB=512 LDC=24592
Proc:3 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
NA:1 NB:1 (512, 24064, 512) a=-1.000000e+00 b=1.000000e+00 LDA=512 LDB=512 LDC=24592
mrem=0, mblk=512
nrem=0, nblk=22528
overlapped dgemm
A->j B->i NOTI=0 NOTJ=0 LDA=512 LDB=512 LDC=24592
mrem=0, mblk=512
nrem=0, nblk=24064
overlapped dgemm
A->j B->i NOTI=0 NOTJ=0 LDA=512 LDB=512 LDC=24592
gdrflag=1
gdr_dgemm elapsed : 1.346023e-01 [sec]
Proc:2 lbl:9 dgemm M=22528 N=512 K=512 time= 0.1346 87.7787 Gflops
gdrflag=1
gdr_dgemm elapsed : 1.427996e-01 [sec]
Proc:3 lbl:9 dgemm M=24064 N=512 K=512 time= 0.1427 88.4001 Gflops
Proc:3 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
NA:1 NB:1 (512, 512, 512) a=-1.000000e+00 b=1.000000e+00 LDA=1024 LDB=1024 LDC=1024
mrem=0, mblk=512
nrem=0, nblk=512
overlapped dgemm
gdrflag=1
gdr_dgemm elapsed : 5.831682e-03 [sec]
Proc:3 lbl:9 dgemm M=512 N=512 K=512 time= 0.005902 45.4826 Gflops
Proc:3 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
NA:1 NB:1 (512, 512, 512) a=1.000000e+00 b=0.000000e+00 LDA=512 LDB=512 LDC=1024
mrem=0, mblk=512
nrem=0, nblk=512
overlapped dgemm
gdrflag=1
gdr_dgemm elapsed : 5.864839e-03 [sec]
Proc:3 lbl:9 dgemm M=512 N=512 K=512 time= 0.005932 45.2523 Gflops
Proc:3 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
NA:1 NB:1 (1024, 1024, 1024) a=1.000000e+00 b=0.000000e+00 LDA=1024 LDB=1024 LDC=24592
mrem=0, mblk=1024
nrem=0, nblk=1024
overlapped dgemm
gdrflag=1
gdr_dgemm elapsed : 1.963065e-02 [sec]
Proc:3 lbl:9 dgemm M=1024 N=1024 K=1024 time= 0.0197 109.031 Gflops
NA:1 NB:1 (1024, 23552, 1024) a=-1.000000e+00 b=1.000000e+00 LDA=1024 LDB=1024 LDC=24592
mrem=0, mblk=1024
nrem=0, nblk=23552
overlapped dgemm
A->j B->i NOTI=0 NOTJ=0 LDA=1024 LDB=1024 LDC=24592
NA:1 NB:1 (1024, 22528, 1024) a=-1.000000e+00 b=1.000000e+00 LDA=1024 LDB=1024 LDC=24592
mrem=0, mblk=1024
nrem=0, nblk=22528
overlapped dgemm
A->j B->i NOTI=0 NOTJ=0 LDA=1024 LDB=1024 LDC=24592
gdrflag=1
gdr_dgemm elapsed : 2.539955e-01 [sec]
Proc:2 lbl:9 dgemm M=22528 N=1024 K=1024 time= 0.2538 186.127 Gflops
gdrflag=1
gdr_dgemm elapsed : 2.651944e-01 [sec]
Proc:3 lbl:9 dgemm M=23552 N=1024 K=1024 time= 0.265 186.387 Gflops
Proc:3 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
NA:1 NB:1 (512, 512, 512) a=1.000000e+00 b=0.000000e+00 LDA=512 LDB=512 LDC=24592
mrem=0, mblk=512
nrem=0, nblk=512
overlapped dgemm
gdrflag=1
gdr_dgemm elapsed : 5.834974e-03 [sec]
Proc:3 lbl:9 dgemm M=512 N=512 K=512 time= 0.005907 45.4432 Gflops
Proc:2 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
NA:1 NB:1 (512, 22528, 512) a=-1.000000e+00 b=1.000000e+00 LDA=512 LDB=512 LDC=24592
Proc:3 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
NA:1 NB:1 (512, 23040, 512) a=-1.000000e+00 b=1.000000e+00 LDA=512 LDB=512 LDC=24592
mrem=0, mblk=512
nrem=0, nblk=22528
overlapped dgemm
A->j B->i NOTI=0 NOTJ=0 LDA=512 LDB=512 LDC=24592
mrem=0, mblk=512
nrem=0, nblk=23040
overlapped dgemm
A->j B->i NOTI=0 NOTJ=0 LDA=512 LDB=512 LDC=24592
gdrflag=1
gdr_dgemm elapsed : 1.345651e-01 [sec]
Proc:2 lbl:9 dgemm M=22528 N=512 K=512 time= 0.1345 87.8016 Gflops
gdr_dgemm elapsed : 1.368866e-01 [sec]
gdrflag=1
Proc:3 lbl:9 dgemm M=23040 N=512 K=512 time= 0.1368 88.2844 Gflops
Proc:3 lbl:9 rfact call MP_construct_scale ii, nb=2048 2048
Proc:2 lbl:9 rfact call MP_construct_scale ii, nb=2048 2048
Proc:3 lbl:9 rfact end, ii, nb=2048 2048
Proc:3 lbl:9 call phase1 0
Proc:2 lbl:9 rfact end, ii, nb=2048 2048
Proc:2 lbl:9 call phase1 0
Proc:2 lbl:9 call phase1 end
P2, end rfact, time=7.53258
Proc:2 lbl:9 call process_row_comm
P2, enter process_row_comm_init, time=7.53259
Proc:3 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
NA:1 NB:1 (512, 512, 512) a=-1.000000e+00 b=1.000000e+00 LDA=2048 LDB=2048 LDC=2048
mrem=0, mblk=512
nrem=0, nblk=512
overlapped dgemm
gdrflag=1
gdr_dgemm elapsed : 5.838349e-03 [sec]
Proc:3 lbl:9 dgemm M=512 N=512 K=512 time= 0.005901 45.4891 Gflops
Proc:3 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
NA:1 NB:1 (512, 512, 512) a=1.000000e+00 b=0.000000e+00 LDA=512 LDB=512 LDC=2048
mrem=0, mblk=512
nrem=0, nblk=512
overlapped dgemm
gdrflag=1
gdr_dgemm elapsed : 5.958500e-03 [sec]
Proc:3 lbl:9 dgemm M=512 N=512 K=512 time= 0.006017 44.6131 Gflops
Proc:3 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
NA:1 NB:1 (1024, 1024, 1024) a=-1.000000e+00 b=1.000000e+00 LDA=2048 LDB=2048 LDC=2048
mrem=0, mblk=1024
nrem=0, nblk=1024
overlapped dgemm
gdrflag=1
gdr_dgemm elapsed : 1.881045e-02 [sec]
Proc:3 lbl:9 dgemm M=1024 N=1024 K=1024 time= 0.01885 113.943 Gflops
P2, end process_row_comm_init, time=7.65937
Proc:2 lbl:9 call process_right_part_... 0
Proc:2 lbl:9 using_dls call first phase1
Proc:3 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
NA:1 NB:1 (512, 512, 512) a=-1.000000e+00 b=1.000000e+00 LDA=1024 LDB=2048 LDC=1024
mrem=0, mblk=512
nrem=0, nblk=512
overlapped dgemm
gdrflag=1
gdr_dgemm elapsed : 5.824858e-03 [sec]
Proc:3 lbl:9 dgemm M=512 N=512 K=512 time= 0.005889 45.583 Gflops
Proc:3 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
NA:1 NB:1 (512, 512, 512) a=1.000000e+00 b=0.000000e+00 LDA=512 LDB=512 LDC=1024
mrem=0, mblk=512
nrem=0, nblk=512
overlapped dgemm
gdrflag=1
gdr_dgemm elapsed : 5.878640e-03 [sec]
Proc:3 lbl:9 dgemm M=512 N=512 K=512 time= 0.005945 45.1534 Gflops
Proc:3 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
NA:1 NB:1 (1024, 1024, 1024) a=1.000000e+00 b=0.000000e+00 LDA=1024 LDB=1024 LDC=2048
mrem=0, mblk=1024
nrem=0, nblk=1024
overlapped dgemm
gdrflag=1
gdr_dgemm elapsed : 1.957623e-02 [sec]
Proc:3 lbl:9 dgemm M=1024 N=1024 K=1024 time= 0.01964 109.37 Gflops
Proc:3 lbl:9 call phase1 end
P3, end rfact, time=7.70692
Proc:3 lbl:9 call process_row_comm
P3, enter process_row_comm_init, time=7.70693
P3, end process_row_comm_init, time=7.82203
Proc:3 lbl:9 call process_right_part_... 0
Proc:3 lbl:9 using_dls call first phase1
P3, end swap and scale, time=8.32892
Proc:3 lbl:9 numprocs = 2
P2, end swap and scale, time=8.32876
Proc:2 lbl:9 numprocs = 2
gdr_dgemm elapsed : 3.515226e+00 [sec]
gdrflag=1
Proc:0 lbl:9 dgemm M=22528 N=22544 K=2048 time= 3.512 592.37 Gflops
P0, end dls_phase_2, time=8.46366
Proc:0 lbl:9 end process_right_part_... 0
gdr_dgemm elapsed : 3.815202e+00 [sec]
gdrflag=1
Proc:1 lbl:9 dgemm M=24576 N=22544 K=2048 time= 3.811 595.419 Gflops
P1, end dls_phase_2, time=8.76317
Proc:1 lbl:9 end process_right_part_... 0
Proc:3 lbl:9 end bcast_umat
Proc:2 lbl:9 end bcast_umat
Proc:2 lbl:9 using_dls end first phase1
Proc:2 lbl:9 using_dls call local_check_and_continue_rcomm
NA:1 NB:1 (22544, 22528, 2048) a=-1.000000e+00 b=1.000000e+00 LDA=22544 LDB=2048 LDC=24592
Proc:3 lbl:9 using_dls end first phase1
Proc:3 lbl:9 using_dls call local_check_and_continue_rcomm
NA:1 NB:1 (22544, 24576, 2048) a=-1.000000e+00 b=1.000000e+00 LDA=22544 LDB=2048 LDC=24592
Proc:2 lbl:9 using_dls, cs=2048, rcomm=332
P2, enter dls_phase_2, time=8.98655
Proc:2 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
mrem=16, mblk=22528
nrem=0, nblk=22528
Proc:3 lbl:9 using_dls, cs=2048, rcomm=249
P3, enter dls_phase_2, time=8.98676
Proc:3 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
mrem=16, mblk=22528
nrem=0, nblk=24576
Proc:0 lbl:9 end check_and_continue... 0
P0, end lmat/dls, time=9.0049
Proc:0 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
gdrflag=0
Proc:0 lbl:9 dgemm M=2048 N=1 K=2048 time= 0.002361 3.5529 Gflops
P0, end mult_diag, time=9.01412
overlapped dgemm
overlapped dgemm
A->j B->i NOTI=0 NOTJ=0 LDA=22544 LDB=2048 LDC=24592
gdr_dgemm elapsed : 3.542345e+00 [sec]
gdrflag=1
Proc:2 lbl:9 dgemm M=22528 N=22544 K=2048 time= 3.539 587.839 Gflops
P2, end dls_phase_2, time=12.5254
Proc:2 lbl:9 end process_right_part_... 0
Proc:2 lbl:9 end check_and_continue... 0
P2, end lmat/dls, time=12.5254
Proc:2 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
gdrflag=0
Proc:2 lbl:9 dgemm M=2048 N=1 K=2048 time= 0.002807 2.98831 Gflops
P2, end mult_diag, time=12.5363
gdr_dgemm elapsed : 3.826344e+00 [sec]
gdrflag=1
Proc:3 lbl:9 dgemm M=24576 N=22544 K=2048 time= 3.822 593.684 Gflops
P3, end dls_phase_2, time=12.8093
Proc:3 lbl:9 end process_right_part_... 0
Proc:3 lbl:9 end check_and_continue... 0
Proc:1 lbl:9 end check_and_continue... 0
P3, end lmat/dls, time=12.8902
P3, end mult_diag, time=12.8902
P1, end lmat/dls, time=12.8901
P1, end mult_diag, time=12.8901
P1, end ld_phase1, time=12.9269
P3, end ld_phase1, time=12.9273
P2, end ld_phase1, time=12.927
Proc:0 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
NA:1 NB:1 (2048, 22528, 2048) a=1.000000e+00 b=0.000000e+00 LDA=2048 LDB=2048 LDC=2048
mrem=0, mblk=2048
nrem=0, nblk=22528
Proc:2 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
NA:1 NB:1 (2048, 22528, 2048) a=1.000000e+00 b=0.000000e+00 LDA=2048 LDB=2048 LDC=2048
mrem=0, mblk=2048
nrem=0, nblk=22528
Proc:1 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
NA:1 NB:1 (2048, 24576, 2048) a=1.000000e+00 b=0.000000e+00 LDA=2048 LDB=2048 LDC=2048
mrem=0, mblk=2048
nrem=0, nblk=24576
Proc:3 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
NA:1 NB:1 (2048, 24576, 2048) a=1.000000e+00 b=0.000000e+00 LDA=2048 LDB=2048 LDC=2048
mrem=0, mblk=2048
nrem=0, nblk=24576
overlapped dgemm
A->j B->i NOTI=0 NOTJ=0 LDA=2048 LDB=2048 LDC=2048
overlapped dgemm
A->j B->i NOTI=0 NOTJ=0 LDA=2048 LDB=2048 LDC=2048
overlapped dgemm
A->j B->i NOTI=0 NOTJ=0 LDA=2048 LDB=2048 LDC=2048
overlapped dgemm
A->j B->i NOTI=0 NOTJ=0 LDA=2048 LDB=2048 LDC=2048
gdr_dgemm elapsed : 5.599647e-01 [sec]
gdrflag=1
Proc:0 lbl:9 dgemm M=22528 N=2048 K=2048 time= 0.5595 337.764 Gflops
P0, end ld_phase2, time=13.591
lu_mpi look i=0 end
Proc:0 lbl:9 lu2_mpi i=2048
P0, enter rfact, time=13.591
Proc:0 lbl:9 rfact call dls_phase1, ii, nb=4096 2048
gdr_dgemm elapsed : 5.853835e-01 [sec]
gdrflag=1
Proc:2 lbl:9 dgemm M=22528 N=2048 K=2048 time= 0.5849 323.113 Gflops
P2, end ld_phase2, time=13.6273
Proc:2 lbl:9 lu2_mpi i=2048
P2, enter rfact, time=13.6273
Proc:2 lbl:9 call phase1 2048
Proc:2 lbl:9 call phase1 end
P2, end rfact, time=13.6273
Proc:2 lbl:9 call process_row_comm
P2, enter process_row_comm_init, time=13.6273
P2, end process_row_comm_init, time=13.6274
Proc:2 lbl:9 call process_right_part_... 2048
Proc:2 lbl:9 using_dls call first phase1
gdr_dgemm elapsed : 6.057525e-01 [sec]
gdrflag=1
Proc:1 lbl:9 dgemm M=24576 N=2048 K=2048 time= 0.6052 340.631 Gflops
P1, end ld_phase2, time=13.6536
Proc:1 lbl:9 lu2_mpi i=2048
P1, enter rfact, time=13.6536
Proc:1 lbl:9 rfact call dls_phase1, ii, nb=4096 2048
gdr_dgemm elapsed : 6.114413e-01 [sec]
P2, enter rfact, time=4.06921
P2, end rfact, time=7.53258
P0, enter rfact, time=13.591
P0, end rfact, time=17.0883
P2, enter rfact, time=22.2046
P2, end rfact, time=25.4345
mrem=0, mblk=512
nrem=0, nblk=7680
overlapped dgemm
A->j B->i NOTI=0 NOTJ=0 LDA=512 LDB=512 LDC=8208
gdr_dgemm elapsed : 5.255059e-02 [sec]
gdrflag=1
Proc:0 lbl:9 dgemm M=7680 N=512 K=512 time= 0.05263 76.5037 Gflops
NA:1 NB:1 (2048, 6144, 2048) a=1.000000e+00 b=0.000000e+00 LDA=2048 LDB=2048 LDC=2048
mrem=0, mblk=2048
nrem=0, nblk=6144
overlapped dgemm
A->j B->i NOTI=0 NOTJ=0 LDA=2048 LDB=2048 LDC=2048
gdr_dgemm elapsed : 1.684153e-01 [sec]
gdrflag=1
Proc:0 lbl:9 dgemm M=6144 N=2048 K=2048 time= 0.1684 306.122 Gflops
NA:1 NB:1 (4112, 6144, 2048) a=-1.000000e+00 b=1.000000e+00 LDA=4112 LDB=2048 LDC=8208
mrem=16, mblk=4096
nrem=0, nblk=6144
overlapped dgemm
A->j B->i NOTI=0 NOTJ=0 LDA=4112 LDB=2048 LDC=8208
gdr_dgemm elapsed : 2.662320e-01 [sec]
gdrflag=1
Proc:0 lbl:9 dgemm M=6144 N=4112 K=2048 time= 0.2661 388.948 Gflops
現在は、
ちょっと別の問題点: beta!= 1.0 の時に、 0.0 でもいらんことをする。
Proc:0 lbl:9 end bcast_umat
Proc:0 lbl:9 using_dls end first phase1
Proc:0 lbl:9 using_dls call local_check_and_continue_rcomm
Proc:0 lbl:9 using_dls, cs=4096, rcomm=98
P0, enter dls_phase_2, time=2.29025
Proc:0 lbl:9 mygdrdgemm omp_max_threads=8 procs=4
matmul_tb4_mnk_ovl_dg_trans j_mat send 4096 2048 4112
Proc:0 lbl:9 dgemm M=6144 N=4112 K=2048 time= 0.2653 390.095 Gflops
ここで、
転置する理由は?
API をどうするか?引数増やすのが正しいけど、とりあえずモード指定でごま
かす。
gdr_dgemm_ forceswapab=1
NA:1 NB:1 (4112, 6144, 2048) a=-1.000000e+00 b=1.000000e+00 LDA=4112 LDB=2048 LDC=8208
mrem=16, mblk=4096
nrem=0, nblk=6144
overlapped dgemm
A->j B->i NOTI=0 NOTJ=0 LDA=4112 LDB=2048 LDC=8208
matmul_tb4_mnk_ovl_dg_trans j_mat send 4096 2048 4112
M=6144 N=4096 K=2048 ip=1.945734e-02 jp=4.045566e-02 fo=1.920269e-01 all=2.519399e-01 409.14 GFlop
s
gdr_dgemm elapsed : 2.653799e-01 [sec]
gdrflag=1
Proc:0 lbl:9 dgemm M=6144 N=4112 K=2048 time= 0.2651 390.281 Gflops
Bを J-mat にしないといけない。
これはできた。
j matrix を送るのを1スレッドでする。
というわけで問題点: dgemm16, 32, 128 が異常に遅い
nvidia Tesla ではピーク 900Gflops で SGEMM 300 ちょい (4k x 4k) とのこ
と。そんな遅いのは何故か?
データ量 16MW = 64MB
行き: 128MB
帰り: 64MB
演算数 128G 0.14 秒。300Gflops まで落ちるためには、 0.25秒くらい他の
どこかでかかる必要あり。データは 192MB なので、上り下りの合計で800MB/s
でしかもオーバーラップもできてなければこういう性能になりえる。
mympirun.csh 4 "01 02 06 07 " lu2_mpi_gdr -g -p 2 -q 2 -n 61440
M=2048 N=14336 K=2048 ip=7.918990e-03 jp=2.053758e-01 fo=1.879966e-01 all=4.012914e-01 299.68 GFlops
gdr_dgemm elapsed : 4.013716e-01 [sec]
gdrflag=1
Proc:0 lbl:9 dgemm M=14336 N=2048 K=2048 time= 0.401 299.897 Gflops
P0, end dls_phase_2, time=4.71612
P0, enter dls_phase_1, time=4.71613
P0, end swap and scale, time=4.73158
Proc:0 lbl:9 numprocs = 1
Proc:0 lbl:9 end bcast_umat
P0, end dls_phase_1, time=4.73929
Proc:0 lbl:9 using_dls call local_check_and_continue_rcomm
Proc:0 lbl:9 using_dls, cs=6144, rcomm=226
P0, enter dls_phase_2, time=4.73932
Proc:0 lbl:9 mygdrdgemm omp_max_threads=6 procs=4
gdr_dgemm_ forceswapab=1
NA:1 NB:1 (2048, 14336, 2048) a=-1.000000e+00 b=1.000000e+00 LDA=2048 LDB=2048 LDC=16400
mrem=0, mblk=2048
nrem=0, nblk=14336
overlapped dgemm
matmul_tb4_mnk_ovl_dg j_mat send 14336 2048 2048
M=2048 N=14336 K=2048 ip=8.015228e-03 jp=8.101895e-06 fo=1.880975e-01 all=1.961208e-01 613.19 GFlops
gdr_dgemm elapsed : 1.961749e-01 [sec]
gdrflag=1
Proc:0 lbl:9 dgemm M=14336 N=2048 K=2048 time= 0.196 613.56 Gflops
P0, end dls_phase_2, time=4.93534
P0, enter dls_phase_1, time=4.93534
P0, end swap and scale, time=4.9508
Proc:0 lbl:9 numprocs = 1
Proc:0 lbl:9 end bcast_umat
P0, end dls_phase_1, time=4.9585
Proc:0 lbl:9 using_dls call local_check_and_continue_rcomm
overlapping
M=2048 N=14336 K=2048 ip=2.059820e-02 jp=2.060103e-01 fo=1.960157e-01 all=4.226242e-01 284.55 GFlops
gdr_dgemm elapsed : 4.226805e-01 [sec]
gdrflag=1
Proc:0 lbl:9 dgemm M=14336 N=2048 K=2048 time= 0.4223 284.79 Gflops
P0, end dls_phase_2, time=4.79432
Proc:0 lbl:9 using_dls call local_check_and_continue_rcomm
Proc:0 lbl:9 using_dls, cs=6144, rcomm=226
P0, enter dls_phase_1, time=4.79438
P0, enter dls_phase_2, time=4.79437
Proc:0 lbl:9 mygdrdgemm omp_max_threads=1 procs=4
gdr_dgemm_ forceswapab=1
NA:1 NB:1 (2048, 14336, 2048) a=-1.000000e+00 b=1.000000e+00 LDA=2048 LDB=2048 LDC=16400
mrem=0, mblk=2048
nrem=0, nblk=14336
overlapped dgemm
matmul_tb4_mnk_ovl_dg j_mat send 14336 2048 2048
P0, end swap and scale, time=4.81355
Proc:0 lbl:9 numprocs = 1
Proc:0 lbl:9 end bcast_umat
P0, end dls_phase_1, time=4.82329
M=2048 N=14336 K=2048 ip=2.087803e-02 jp=1.250941e-06 fo=1.965952e-01 all=2.174745e-01 552.98 GFlops
gdr_dgemm elapsed : 2.175336e-01 [sec]
gdrflag=1
Proc:0 lbl:9 dgemm M=14336 N=2048 K=2048 time= 0.2173 553.335 Gflops
P0, end dls_phase_2, time=5.01174
Proc:0 lbl:9 using_dls call local_check_and_continue_rcomm
non-overlapping:
M=2048 N=14336 K=2048 ip=7.918990e-03 jp=2.053758e-01 fo=1.879966e-01 all=4.012914e-01 299.68 GFlops
gdr_dgemm elapsed : 4.013716e-01 [sec]
P0, end dls_phase_2, time=4.71612
P0, enter dls_phase_1, time=4.71613
P0, end swap and scale, time=4.73158
P0, end dls_phase_1, time=4.73929
P0, enter dls_phase_2, time=4.73932
NA:1 NB:1 (2048, 14336, 2048) a=-1.000000e+00 b=1.000000e+00 LDA=2048 LDB=2048 LDC=16400
M=2048 N=14336 K=2048 ip=8.015228e-03 jp=8.101895e-06 fo=1.880975e-01 all=1.961208e-01 613.19 GFlops
gdr_dgemm elapsed : 1.961749e-01 [sec]
P0, end dls_phase_2, time=4.93534
end phase2 - end phase2 0.2192 sec
overlapping
M=2048 N=14336 K=2048 ip=2.059820e-02 jp=2.060103e-01 fo=1.960157e-01 all=4.226242e-01 284.55 GFlops
gdr_dgemm elapsed : 4.226805e-01 [sec]
P0, end dls_phase_2, time=4.79432
P0, enter dls_phase_1, time=4.79438
P0, enter dls_phase_2, time=4.79437
NA:1 NB:1 (2048, 14336, 2048) a=-1.000000e+00 b=1.000000e+00 LDA=2048 LDB=2048 LDC=16400
P0, end swap and scale, time=4.81355
P0, end dls_phase_1, time=4.82329
M=2048 N=14336 K=2048 ip=2.087803e-02 jp=1.250941e-06 fo=1.965952e-01 all=2.174745e-01 552.98 GFlops
gdr_dgemm elapsed : 2.175336e-01 [sec]
Proc:0 lbl:9 dgemm M=14336 N=2048 K=2048 time= 0.2173 553.335 Gflops
P0, end dls_phase_2, time=5.01174
end phase2 - end phase2 0.21742 sec
roughly the same
overall speed: ovl: 145.66, non: 149.949
roughly the same
jp send speed: 1.14 GB/s
遅いところ:
M=2048 N=14336 K=2048 ip=8.001197e-03 jp=1.406880e-01 fo=1.879789e-01 all=3.366680e-01 357.20 GFlops
gdr_dgemm elapsed : 3.367504e-01 [sec]
Proc:0 lbl:9 dgemm M=14336 N=2048 K=2048 time= 0.3364 357.439 Gflops
P0, end dls_phase_2, time=4.53321
P0, enter dls_phase_1, time=4.53322
P0, end swap and scale, time=4.54864
P0, end dls_phase_1, time=4.55634
P0, enter dls_phase_2, time=4.55638
NA:1 NB:1 (2048, 14336, 2048) a=-1.000000e+00 b=1.000000e+00 LDA=2048 LDB=2048 LDC=16400
M=2048 N=14336 K=2048 ip=8.101666e-03 jp=8.242700e-06 fo=1.879834e-01 all=1.960933e-01 613.27 GFlops
Proc:0 lbl:9 dgemm M=14336 N=2048 K=2048 time= 0.196 613.423 Gflops
P0, end dls_phase_2, time=4.75245
jp send speed: 1.7GB/s
155 Gflops
これは結構違う 18.9sec : 19.55 sec
s=384:
M=2048 N=14336 K=2048 ip=2.050511e-02 jp=2.009139e-01 fo=1.957766e-01 all=4.171956e-01 288.26 GFlops
M=2048 N=14336 K=2048 ip=2.050756e-02 jp=2.674155e-01 fo=1.958860e-01 all=4.838090e-01 248.57 GFlops
N=12288, non-uc
P0, enter dls_phase_2, time=5.76919
NA:1 NB:1 (2048, 8192, 2048) a=-1.000000e+00 b=1.000000e+00 LDA=2048 LDB=2048 LDC=12304
M=2048 N=8192 K=2048 ip=7.975510e-03 jp=1.078174e-01 fo=1.135233e-01 all=2.293162e-01 299.67 GFlops
gdr_dgemm elapsed : 2.294347e-01 [sec]
Proc:0 lbl:9 dgemm M=8192 N=2048 K=2048 time= 0.2293 299.743 Gflops
P0, end dls_phase_2, time=5.99849
P0, enter dls_phase_1, time=5.9985
P0, end swap and scale, time=6.01391
P0, end dls_phase_1, time=6.02164
NA:1 NB:1 (2048, 8192, 2048) a=-1.000000e+00 b=1.000000e+00 LDA=2048 LDB=2048 LDC=12304
M=2048 N=8192 K=2048 ip=7.959628e-03 jp=1.377528e-05 fo=1.134495e-01 all=1.214229e-01 565.95 GFlops
gdr_dgemm elapsed : 1.215246e-01 [sec]
Proc:0 lbl:9 dgemm M=8192 N=2048 K=2048 time= 0.1214 565.834 Gflops
P0, end dls_phase_2, time=6.14317
uc version
P0, end dls_phase_1, time=5.88687
M=2048 N=8192 K=2048 ip=2.051659e-02 jp=1.091667e-01 fo=1.220256e-01 all=2.517089e-01 273.01 GFlops
gdr_dgemm elapsed : 2.517636e-01 [sec]
Proc:0 lbl:9 dgemm M=8192 N=2048 K=2048 time= 0.2515 273.207 Gflops
P0, end dls_phase_2, time=6.11046
P0, enter dls_phase_2, time=6.1106
P0, enter dls_phase_1, time=6.1106
NA:1 NB:1 (2048, 8192, 2048) a=-1.000000e+00 b=1.000000e+00 LDA=2048 LDB=2048 LDC=12304
P0, end swap and scale, time=6.1298
Proc:0 lbl:9 numprocs = 1
Proc:0 lbl:9 end bcast_umat
P0, end dls_phase_1, time=6.14016
M=2048 N=8192 K=2048 ip=2.081677e-02 jp=1.192509e-06 fo=1.226711e-01 all=1.434891e-01 478.92 GFlops
gdr_dgemm elapsed : 1.435442e-01 [sec]
Proc:0 lbl:9 dgemm M=8192 N=2048 K=2048 time= 0.1434 479.152 Gflops
P0, end dls_phase_2, time=6.25403
ip も遅くなっている。 fo も。
61440 の現在の性能:
_lookahead の中で、calculate_ld_phase1, phase2 にわたっている引数がお
かしい。
phase2 の第3引数が nrows のまま。これはおかしい。
acp2 から一旦 acp にコピーして、乗算結果を acp2 に戻している。
これは L 行列で、次のステップの update で使われる。
使う時には acp である。
transfer: process_row_com_init: ここで nrows を送っている。
これがそもそも不要。いや、ここでは nrows を計算している。
これを憶えておいて ld_phase2 で使えばいいだけのはず。
これの次は send_i_matrix_mt
ld_phase2 の寸法は修正
4ノード、 N=61440 で
Emax= 6.261e-06
Nswap=0 cpsec = 89.9653 wsec=55.4421 348.605 Gflops
4ノード、32Kの時
ucomm noovl
single node で遅い理由
2: no SMT
3: SMT
4: SMT
あとは no smt
SMT だとおかしくなる。
2.44316: dls phase1/2 start
2.47915 dls phase1 end
2.65152 dls phase2 end
2.65156 dls phase2 start
2.82272 dls phase2 end
2.83534 mult_diag end
2.83538 ld_phase1 end
2.98626 ld_phase2 end
2.98628 rfact start
3.00323 swap and scale end
3.824 rfact end
4k x 2k の rfact にほぼ 0.8 秒かかっている。
演算数は 16G しかないので、ここは 20Gflops しかでてない計算。いくらな
んでもおそすぎ。何が遅いかが問題。
0.897644 end first rfact
1.32214 end first lookahead
この間の DGEMM
Proc:0 lbl:9 dgemm M=512 N=512 K=512 time= 0.007624 35.2086 Gflops
Proc:0 lbl:9 dgemm M=512 N=512 K=512 time= 0.007573 35.4469 Gflops
Proc:0 lbl:9 dgemm M=1024 N=1024 K=1024 time= 0.02232 96.2133 Gflops
Proc:0 lbl:9 dgemm M=512 N=512 K=512 time= 0.007658 35.0529 Gflops
Proc:0 lbl:9 dgemm M=512 N=512 K=512 time= 0.007584 35.3945 Gflops
Proc:0 lbl:9 dgemm M=1024 N=1024 K=1024 time= 0.02356 91.1577 Gflops
Proc:0 lbl:9 dgemm M=6144 N=2048 K=2048 time= 0.1735 297.128 Gflops
0.2499 sec
それ以外: 0.175sec
ここの DGEMM は、、、 0.1735 分はやむをえない。 LD の乗算。
D^-1 の計算のところがおそすぎ?
K=1024, M=7k: 0.836sec
K=512, M=7.5k: 0.04776 sec
そのうち、小さい DGEMM は 0.12秒
2.426 rfact end
最初の512: 0.15 sec
最初の256 0.06 sec
その後処理 0.096 まで。
最初の 128 0.0243sec
その後処理 0.035まで
P0, end first rfact, time=0.883182
P0, end MP_process_diagonal, time=1.05617
P0, end MP_process_lmat, time=1.08064
P0, end first lookahead, time=1.28385
P0, enter rfact, time=1.28385
P0, end swap and scale, time=1.29923
P0, enter column_deconp, time=1.48439
process_diagonal 0.18sec
最初の行列コピーがおかしかったのを直すと 0.12 秒に。
DTRSM の再帰を 128 で止めると速くなる。
P0, end MP_process_lmat, time=0.959718
0.12秒
N=30K
Proc:0 lbl:1 Left bcast etc time=0 ops/cycle=nan
Proc:0 lbl:1 update time=0 ops/cycle=nan
Proc:0 lbl:1 update matmul time=8.315e+10 ops/cycle=103.72
Proc:0 lbl:1 update swap+bcast time=5.99702e+09 ops/cycle=0.618268
Proc:0 lbl:1 total time=1.79205e+11 ops/cycle=48.6525
Proc:0 lbl:1 rfact time=7.79363e+10 ops/cycle=0.00565079
Proc:0 lbl:1 ldmul time=1.72909e+10 ops/cycle=104.326
Proc:0 lbl:1 colum dec with trans time=1.40455e+10 ops/cycle=0.0336037
Proc:0 lbl:1 colum dec right time=4.93532e+10 ops/cycle=10.1872
Proc:0 lbl:1 colum dec left time=3.65347e+08 ops/cycle=0.0857661
Proc:0 lbl:1 rowtocol time=4.04519e+09 ops/cycle=0.116677
Proc:0 lbl:1 column dec in trans time=9.09885e+09 ops/cycle=0.414982
Proc:0 lbl:1 coltorow time=8.94132e+08 ops/cycle=0.527866
Proc:0 lbl:1 dgemm8 time=8.5123e+08 ops/cycle=4.43461
Proc:0 lbl:1 dgemm16 time=1.04084e+09 ops/cycle=7.25353
Proc:0 lbl:1 dgemm32 time=1.40603e+09 ops/cycle=10.7391
Proc:0 lbl:1 dgemm64 time=2.31896e+09 ops/cycle=13.0226
Proc:0 lbl:1 dgemm128 time=4.18161e+09 ops/cycle=14.4437
Proc:0 lbl:1 main dgemm time=9.85097e+10 ops/cycle=177.157
Emax= 6.261e-06
Nswap=0 cpsec = 89.7404 wsec=55.3601 349.121 Gflops
swaprows time=2.18862e+09 ops/cycle=0.215597
scalerow time=1.13234e+08 ops/cycle=4.16713
trans rtoc time=1.30957e+09 ops/cycle=0.360317
trans ctor time=7.34771e+08 ops/cycle=0.642185
trans mmul time=2.74245e+09 ops/cycle=2.58086
trans nonrec cdec time=1.09522e+09 ops/cycle=0.430836
trans vvmul time=3.90413e+08 ops/cycle=1.20861
trans findp time=6.93664e+08 ops/cycle=0.680242
solve tri u time=6.45408e+09 ops/cycle=4.75978e-06
solve tri time=1.84751e+10 ops/cycle=104.613
matmul nk8 time=0 ops/cycle=inf
matmul snk time=72956 ops/cycle=103484
trans mmul8 time=8.24518e+08 ops/cycle=4.57828
trans mmul4 time=7.71164e+08 ops/cycle=2.44752
trans mmul2 time=1.14111e+09 ops/cycle=0.827016
DGEMM2K time=9.60273e+10 ops/cycle=191.206
DGEMM1K time=9.64212e+09 ops/cycle=50.1118
DGEMM512 time=9.61004e+09 ops/cycle=25.1395
DGEMMrest time=1.96678e+10 ops/cycle=12.2836
この2つがおそすぎるような
Proc:0 lbl:1 colum dec with trans time=1.40455e+10 ops/cycle=0.0336037
Proc:0 lbl:1 colum dec right time=4.93532e+10 ops/cycle=10.1872
with trans の中では
Proc:0 lbl:1 rowtocol time=4.04519e+09 ops/cycle=0.116677
Proc:0 lbl:1 column dec in trans time=9.09885e+09 ops/cycle=0.414982
with trans: 5 秒。並列化等で2秒にはできるはず。
rowtocol を OMP チューニング版に置き換え
まあ、これはこんなものかな。4倍速くなって1秒減った。
まあ2倍。残りの大半:
Proc:0 lbl:1 colum dec right time=4.93619e+10 ops/cycle=10.1854
u no-ovl の場合
gdrdgemm は 10% くらい速くなるが、トータルで lu2_gdr に比べると
やはりまだ2割遅い。なんでだっけ?
もうちょっと細かくみたもの:
Proc:0 lbl:1 Left bcast etc time=0 ops/cycle=nan
Proc:0 lbl:1 update time=0 ops/cycle=nan
Proc:0 lbl:1 update matmul time=8.31007e+10 ops/cycle=103.781
movntps, 8 単位
Proc:0 lbl:1 col right misc time=4.35439e+08 ops/cycle=0.308236
Proc:0 lbl:1 col right misc time=4.68374e+08 ops/cycle=0.286561
Proc:0 lbl:1 col right misc time=3.97299e+08 ops/cycle=0.337825
Proc:0 lbl:1 col right misc time=4.81192e+08 ops/cycle=0.278928
Proc:0 lbl:1 col right misc time=3.65113e+08 ops/cycle=0.367606
N=30k
nonc
lu2: 55 sec
Emax= 6.261e-06
Nswap=0 cpsec = 89.7404 wsec=55.3601 349.121 Gflops
swaprows time=2.18862e+09 ops/cycle=0.215597
scalerow time=1.13234e+08 ops/cycle=4.16713
trans rtoc time=1.30957e+09 ops/cycle=0.360317
trans ctor time=7.34771e+08 ops/cycle=0.642185
trans mmul time=2.74245e+09 ops/cycle=2.58086
trans nonrec cdec time=1.09522e+09 ops/cycle=0.430836
trans vvmul time=3.90413e+08 ops/cycle=1.20861
trans findp time=6.93664e+08 ops/cycle=0.680242
solve tri u time=6.45408e+09 ops/cycle=4.75978e-06
solve tri time=1.84751e+10 ops/cycle=104.613
matmul nk8 time=0 ops/cycle=inf
matmul snk time=72956 ops/cycle=103484
trans mmul8 time=8.24518e+08 ops/cycle=4.57828
trans mmul4 time=7.71164e+08 ops/cycle=2.44752
trans mmul2 time=1.14111e+09 ops/cycle=0.827016
DGEMM2K time=9.60273e+10 ops/cycle=191.206
DGEMM1K time=9.64212e+09 ops/cycle=50.1118
DGEMM512 time=9.61004e+09 ops/cycle=25.1395
DGEMMrest time=1.96678e+10 ops/cycle=12.2836
色々いじったあと
3x3, 96k
Proc:0 lbl:1 update time= 3.90032e+11 ops/cycle= 1623.06
Proc:0 lbl:1 update matmul time= 3.20808e+11 ops/cycle= 616.65
Proc:0 lbl:1 update swap+bcast time= 2.71155e+11 ops/cycle= 0.159927
Proc:0 lbl:1 total time= 6.31831e+11 ops/cycle= 1002.35
Proc:0 lbl:1 rfact time= 1.18891e+11 ops/cycle= 0.0414524
Proc:0 lbl:1 ldmul time= 5.97548e+10 ops/cycle= 103.502
Proc:0 lbl:1 colum dec with trans time= 1.53605e+10 ops/cycle= -0.0305739
Proc:0 lbl:1 colum dec right time= 5.63731e+10 ops/cycle= -8.09342
Proc:0 lbl:1 colum dec left time= 6.05967e+09 ops/cycle= 0.00551571
Proc:0 lbl:1 rowtocol time= 2.05166e+09 ops/cycle= 0.26174
Proc:0 lbl:1 column dec in trans time= 1.22862e+10 ops/cycle= 0.349661
Proc:0 lbl:1 coltorow time= 1.01405e+09 ops/cycle= 0.52956
Proc:0 lbl:1 dgemm8 time= 1.14977e+09 ops/cycle= 3.7355
Proc:0 lbl:1 dgemm16 time= 1.24046e+09 ops/cycle= 6.9248
Proc:0 lbl:1 dgemm32 time= 1.62409e+09 ops/cycle= 10.5782
Proc:0 lbl:1 dgemm64 time= 2.66319e+09 ops/cycle= 12.9017
Proc:0 lbl:1 dgemm128 time= 4.77837e+09 ops/cycle= 14.3814
Proc:0 lbl:1 main dgemm time= 3.38273e+11 ops/cycle= 189.07
Proc:0 lbl:1 col trsm time= 2.26439e+09 ops/cycle= 20.2316
Proc:0 lbl:1 col update time= 4.79954e+10 ops/cycle= 0.954513
Proc:0 lbl:1 col r dgemm time= 3.70305e+10 ops/cycle= 29.576
Proc:0 lbl:1 col right misc time= 8.6946e+09 ops/cycle= 0.24699
Proc:0 lbl:1 backsub time= 1.60865e+10 ops/cycle= 0.600731
Proc:0 lbl:1 col dec total time= 7.78e+10 ops/cycle= 0.0219419
backsub に現在2%以上の時間。もうちょっとなんとかするべき。
2x2, 64k
Proc:0 lbl:1 update time= 2.31216e+11 ops/cycle= 810.786
Proc:0 lbl:1 update matmul time= 2.10701e+11 ops/cycle= 413.473
Proc:0 lbl:1 update swap+bcast time= 1.23215e+11 ops/cycle= 0.154647
Proc:0 lbl:1 total time= 4.08955e+11 ops/cycle= 458.853
Proc:0 lbl:1 rfact time= 1.02284e+11 ops/cycle= 0.0216105
Proc:0 lbl:1 ldmul time= 3.98183e+10 ops/cycle= 103.55
Proc:0 lbl:1 colum dec with trans time= 1.23666e+10 ops/cycle= 0.00272392
Proc:0 lbl:1 colum dec right time= 5.28035e+10 ops/cycle= 1.08197
Proc:0 lbl:1 colum dec left time= 4.09929e+09 ops/cycle= 0.00815345
Proc:0 lbl:1 rowtocol time= 2.05734e+09 ops/cycle= 0.261017
Proc:0 lbl:1 column dec in trans time= 9.28677e+09 ops/cycle= 0.462595
Proc:0 lbl:1 coltorow time= 1.0139e+09 ops/cycle= 0.529641
Proc:0 lbl:1 dgemm8 time= 1.1393e+09 ops/cycle= 3.76983
Proc:0 lbl:1 dgemm16 time= 1.25129e+09 ops/cycle= 6.86488
Proc:0 lbl:1 dgemm32 time= 1.6161e+09 ops/cycle= 10.6305
Proc:0 lbl:1 dgemm64 time= 2.64403e+09 ops/cycle= 12.9952
Proc:0 lbl:1 dgemm128 time= 4.77593e+09 ops/cycle= 14.3887
Proc:0 lbl:1 main dgemm time= 2.28187e+11 ops/cycle= 186.856
Proc:0 lbl:1 col trsm time= 2.25847e+09 ops/cycle= 20.2847
Proc:0 lbl:1 col update time= 4.66575e+10 ops/cycle= 0.981884
Proc:0 lbl:1 col r dgemm time= 3.69704e+10 ops/cycle= 29.6241
Proc:0 lbl:1 col right misc time= 7.42236e+09 ops/cycle= 0.289326
Proc:0 lbl:1 backsub time= 1.05089e+10 ops/cycle= 0.4087
Proc:0 lbl:1 col dec total time= 6.92761e+10 ops/cycle= 0.0164076
N=32km p=q=1
Emax= 6.507e-08
Nswap=0 cpsec = 104.573 wsec=65.1045 360.286 Gflops
swaprows time= 2.49729e+09 ops/cycle=0.214982
scalerow time= 1.3404e+08 ops/cycle=4.0053
trans rtoc time= 1.69393e+09 ops/cycle=0.316938
trans ctor time= 9.34798e+08 ops/cycle=0.574318
trans mmul time= 3.15462e+09 ops/cycle=2.55278
tr nr cdec time= 1.25935e+09 ops/cycle=0.426309
trans vvmul time= 4.60062e+08 ops/cycle=1.16695
trans findp time= 7.87413e+08 ops/cycle=0.681816
solve tri u time= 6.86067e+09 ops/cycle=4.77621e-06
solve tri time= 2.07854e+10 ops/cycle=105.797
matmul nk8 time= 0 ops/cycle=inf
matmul snk time= 73044 ops/cycle=117599
trans mmul8 time= 9.44904e+08 ops/cycle=4.5454
trans mmul4 time= 8.74514e+08 ops/cycle=2.45563
trans mmul2 time= 1.32927e+09 ops/cycle=0.807769
DGEMM2K time= 1.14908e+11 ops/cycle=194.563
DGEMM1K time= 1.08493e+10 ops/cycle=50.6722
DGEMM512 time= 1.07845e+10 ops/cycle=25.4883
DGEMMrest time= 2.23522e+10 ops/cycle=12.2976
Total time= 1.72013e+11 ops/cycle=136.363
先週は N=30K で 240Gflops しかでなかったらしい。現状は
Proc:0 lbl:1 ldmul time= 1.7499e+10 ops/cycle= 103.085
Proc:0 lbl:1 rowtocol time= 1.54309e+09 ops/cycle= 0.305868
Proc:0 lbl:1 column dec in trans time= 4.99534e+09 ops/cycle= 0.755876
Proc:0 lbl:1 coltorow time= 8.02318e+08 ops/cycle= 0.588273
Proc:0 lbl:1 dgemm8 time= 9.81078e+08 ops/cycle= 3.84768
Proc:0 lbl:1 dgemm16 time= 1.06053e+09 ops/cycle= 7.11884
Proc:0 lbl:1 dgemm32 time= 1.4035e+09 ops/cycle= 10.7584
Proc:0 lbl:1 dgemm64 time= 2.31584e+09 ops/cycle= 13.0402
Proc:0 lbl:1 dgemm128 time= 4.18114e+09 ops/cycle= 14.4453
Proc:0 lbl:1 main dgemm time= 9.8495e+10 ops/cycle= 177.183
Proc:0 lbl:1 col trsm time= 2.08341e+09 ops/cycle= 20.6148
Proc:0 lbl:1 col update time= 4.00176e+10 ops/cycle= 1.07325
Proc:0 lbl:1 col r dgemm time= 3.23433e+10 ops/cycle= 29.7618
Proc:0 lbl:1 col right misc time= 5.58615e+09 ops/cycle= 0.337878
Proc:0 lbl:1 backsub time= 4.2361e+09 ops/cycle= 0.22278
lookahead の分、行列半分を余計に送っている: 8k の場 256MB弱。これで説明される。
1K, 512, rest は基本的に同じ。
col dec t time= 5.10414e+08 ops/cycle=2.10367
Proc:0 lbl:1 colum dec with trans time= 7.84608e+08 ops/cycle= 0.0428076
で、 16 と 8 で違うので、 dgemm8 の分を加えると 8.5e8 なので、 3.5e8
はここからくる。これも再帰にしないと駄目か?トータルの違いの半分近くは
ここ。後の半分は?
non mpi swap & scale: 2.1e8 くらい
backsub: non-mpi: 0.04sec, mpi: 0.12sec
backsub は速くできる?
非対角のところは Level2 BLAS なのでそっち使ってもいいかも。これはこれ
で十分に速くなった。
update
現在、 10^8 サイクル単位で、
Proc:0 lbl:1 update time= 1.33681e+09 ops/cycle= 257.028
Proc:0 lbl:1 update matmul time= 1.14185e+09 ops/cycle= 210.639
Proc:0 lbl:1 update swap+bcast time= 1.94607e+08 ops/cycle= 0.301737
Proc:0 lbl:1 total time= 1.00126e+10 ops/cycle= 36.6044
Proc:0 lbl:1 rfact time= 7.87956e+09 ops/cycle= 0.00479072
Proc:0 lbl:1 ldmul time= 1.18352e+09 ops/cycle= 87.0952
Proc:0 lbl:1 colum dec with trans time= 7.82664e+08 ops/cycle= 0.042914
Proc:0 lbl:1 colum dec right time= 3.98921e+09 ops/cycle= 10.015
Proc:0 lbl:1 colum dec left time= 9.30375e+07 ops/cycle= 0.0898115
Proc:0 lbl:1 rowtocol time= 1.30659e+08 ops/cycle= 0.257059
Proc:0 lbl:1 column dec in trans time= 5.64202e+08 ops/cycle= 0.476244
Proc:0 lbl:1 coltorow time= 8.62206e+07 ops/cycle= 0.38955
Proc:0 lbl:1 dgemm8 time= 6.7829e+07 ops/cycle= 3.95754
Proc:0 lbl:1 dgemm16 time= 6.87514e+07 ops/cycle= 7.80887
Proc:0 lbl:1 dgemm32 time= 9.49326e+07 ops/cycle= 11.3106
Proc:0 lbl:1 dgemm64 time= 1.64621e+08 ops/cycle= 13.045
Proc:0 lbl:1 dgemm128 time= 3.00375e+08 ops/cycle= 14.2987
Proc:0 lbl:1 main dgemm time= 2.14534e+09 ops/cycle= 112.488
Proc:0 lbl:1 col trsm time= 1.10747e+09 ops/cycle= 11.2034
Proc:0 lbl:1 col update time= 2.78645e+09 ops/cycle= 4.11027
Proc:0 lbl:1 col r dgemm time= 2.41919e+09 ops/cycle= 28.2951
Proc:0 lbl:1 col right misc time= 3.66485e+08 ops/cycle= 0.36623
Proc:0 lbl:1 backsub time= 1.02169e+08 ops/cycle= 0.65684
Proc:0 lbl:1 col dec total time= 4.86607e+09 ops/cycle= 0.00775754
Proc:0 lbl:1 DGEMM2k time= 3.17913e+09 ops/cycle= 130.001
Proc:0 lbl:1 DGEMM1k time= 1.29121e+09 ops/cycle= 46.5684
Proc:0 lbl:1 DGEMM512 time= 1.21036e+09 ops/cycle= 21.2911
Proc:0 lbl:1 update time= 1.33681e+09 ops/cycle= 257.028
Proc:0 lbl:1 rfact time= 7.87956e+09 ops/cycle= 0.00479072
Proc:0 lbl:1 total time= 1.00126e+10 ops/cycle= 36.6044
なので、 update と rfact を足しても合計にならない。あれ?
最後の ld が落ちてた。
Proc:0 lbl:1 update time= 1.3379e+09 ops/cycle= 256.818
Proc:0 lbl:1 update matmul time= 1.14199e+09 ops/cycle= 210.613
Proc:0 lbl:1 update swap+bcast time= 1.95296e+08 ops/cycle= 0.300673
Proc:0 lbl:1 total time= 1.00634e+10 ops/cycle= 36.4195
Proc:0 lbl:1 rfact time= 8.66379e+09 ops/cycle= 0.00435707
Proc:0 lbl:1 ldmul time= 1.1601e+09 ops/cycle= 88.8535
Proc:0 lbl:1 colum dec with trans time= 7.9729e+08 ops/cycle= 0.0421267
Proc:0 lbl:1 colum dec right time= 4.06239e+09 ops/cycle= 9.83462
Proc:0 lbl:1 colum dec left time= 9.32217e+07 ops/cycle= 0.0896341
Proc:0 lbl:1 rowtocol time= 1.38603e+08 ops/cycle= 0.242327
Proc:0 lbl:1 column dec in trans time= 5.68763e+08 ops/cycle= 0.472425
Proc:0 lbl:1 coltorow time= 8.83471e+07 ops/cycle= 0.380173
Proc:0 lbl:1 dgemm8 time= 6.79227e+07 ops/cycle= 3.95207
Proc:0 lbl:1 dgemm16 time= 6.91404e+07 ops/cycle= 7.76493
Proc:0 lbl:1 dgemm32 time= 9.49419e+07 ops/cycle= 11.3095
Proc:0 lbl:1 dgemm64 time= 1.64813e+08 ops/cycle= 13.0298
Proc:0 lbl:1 dgemm128 time= 3.00318e+08 ops/cycle= 14.3014
Proc:0 lbl:1 main dgemm time= 2.14695e+09 ops/cycle= 112.403
Proc:0 lbl:1 col trsm time= 1.11308e+09 ops/cycle= 11.147
Proc:0 lbl:1 col update time= 2.85346e+09 ops/cycle= 4.01375
Proc:0 lbl:1 col r dgemm time= 2.48771e+09 ops/cycle= 27.5157
Proc:0 lbl:1 col right misc time= 3.65018e+08 ops/cycle= 0.367702
Proc:0 lbl:1 backsub time= 1.0231e+08 ops/cycle= 0.655936
Proc:0 lbl:1 col dec total time= 4.95406e+09 ops/cycle= 0.00761976
Proc:0 lbl:1 DGEMM2k time= 3.15848e+09 ops/cycle= 130.851
Proc:0 lbl:1 DGEMM1k time= 1.3194e+09 ops/cycle= 45.5734
Proc:0 lbl:1 DGEMM512 time= 1.24036e+09 ops/cycle= 20.7761
Proc:0 lbl:1 DGEMMrest time= 1.66913e+09 ops/cycle= 12.3699
Proc:0 lbl:1 TRSM U time= 1.64247e+09 ops/cycle= 24.4061
Proc:0 lbl:1 col r swap/scale time= 9.51111e+07 ops/cycle= 0.175707
これはあっている。
Proc:0 lbl:1 rfact time= 8.66379e+09 ops/cycle= 0.00435707
Proc:0 lbl:1 ldmul time= 1.1601e+09 ops/cycle= 88.8535
Proc:0 lbl:1 col dec total time= 4.95406e+09 ops/cycle= 0.00761976
timer37
Proc:0 lbl:1 rfact ex coldec time= 3.71574e+09 ops/cycle= 0
Proc:0 lbl:1 ld_phase1 time= 20256 ops/cycle= 828.259
Proc:0 lbl:1 rfact misc1 time= 9.12441e+08 ops/cycle= 0
Proc:0 lbl:1 rfact misc2 time= 1.18606e+09 ops/cycle= 0
Proc:0 lbl:1 rfact misc3 time= 8.79734e+08 ops/cycle= 0
Proc:0 lbl:1 rfact misc4 time= 7.37513e+08 ops/cycle= 0
misc1:
1.8e9 cycles 多い
DGEMM2k 0.38
col dec t 0.3
col r misc 0.4
(copysubmat 0.5!!!)
p=q=3, n=96k
p=q=3, N=90K
n=32k, p=q=1
non-gdr, p=q=1, 4 mt
p=q=2
Proc:3 lbl:1 update time= 2.26132e+10 ops/cycle= 16.1442
Proc:3 lbl:1 update matmul time= 2.20347e+10 ops/cycle= 7.88202
Proc:3 lbl:1 update swap+bcast time= 5.50403e+08 ops/cycle= 0.308151
Proc:3 lbl:1 total time= 3.28133e+10 ops/cycle= 11.1694
Proc:3 lbl:1 rfact time= 1.01479e+10 ops/cycle= 0.00348737
Proc:3 lbl:1 ldmul time= 4.87866e+09 ops/cycle= 3.52143
Proc:3 lbl:1 colum dec with trans time= 2.39425e+08 ops/cycle= -0.00431112
Proc:3 lbl:1 colum dec right time= 1.55774e+09 ops/cycle= -0.0547767
Proc:3 lbl:1 colum dec left time= 2.60356e+07 ops/cycle= 0.0396455
Proc:3 lbl:1 rowtocol time= 5.74925e+07 ops/cycle= 0.146193
Proc:3 lbl:1 column dec in trans time= 1.49378e+08 ops/cycle= 0.450132
Proc:3 lbl:1 coltorow time= 3.19624e+07 ops/cycle= 0.262965
Proc:3 lbl:1 dgemm8 time= 4.58253e+07 ops/cycle= 1.46445
Proc:3 lbl:1 dgemm16 time= 5.65839e+07 ops/cycle= 2.37201
Proc:3 lbl:1 dgemm32 time= 8.9316e+07 ops/cycle= 3.00546
Proc:3 lbl:1 dgemm64 time= 1.60073e+08 ops/cycle= 3.35392
Proc:3 lbl:1 dgemm128 time= 2.95797e+08 ops/cycle= 3.63
Proc:3 lbl:1 main dgemm time= 2.45935e+10 ops/cycle= 3.77655
Proc:3 lbl:1 col trsm time= 1.94587e+08 ops/cycle= 1.99215
Proc:3 lbl:1 col update time= 1.33806e+09 ops/cycle= 0.267423
Proc:3 lbl:1 col r dgemm time= 1.21739e+09 ops/cycle= 3.47288
Proc:3 lbl:1 col right misc time= 1.20488e+08 ops/cycle= 0.208865
Proc:3 lbl:1 backsub time= 1.49501e+08 ops/cycle= 0.448885
Proc:3 lbl:1 col dec total time= 1.82375e+09 ops/cycle= 0.0113554
Proc:3 lbl:1 DGEMM2k time= 0 ops/cycle= nan
Proc:3 lbl:1 DGEMM1k time= 0 ops/cycle= nan
Proc:3 lbl:1 DGEMM512 time= 2.92767e+10 ops/cycle= 3.7594
Proc:3 lbl:1 DGEMMrest time= 1.55558e+09 ops/cycle= 3.46558
Proc:3 lbl:1 TRSM U time= 3.26076e+08 ops/cycle= 3.8416
Proc:3 lbl:1 col r swap/scale time= 2.48456e+07 ops/cycle= 0.0830886
Proc:3 lbl:1 rfact ex coldec time= 8.32223e+09 ops/cycle= 0
Proc:3 lbl:1 ld_phase1 time= 7.47223e+07 ops/cycle= 0.0561319
Proc:3 lbl:1 rfact misc1 time= 1.1054e+09 ops/cycle= 0
Proc:3 lbl:1 rfact misc2 time= 2.61532e+09 ops/cycle= 0
Proc:3 lbl:1 rfact misc3 time= 2.63945e+08 ops/cycle= 0
Proc:3 lbl:1 rfact misc4 time= 4.33757e+09 ops/cycle= 0
Proc:3 lbl:1 copysubmats time= 1.22777e+08 ops/cycle= 0.230459
Proc:0 lbl:1 colum dec with trans time= 8.05956e+08 ops/cycle= 0.0416737
Proc:3 lbl:1 colum dec with trans time= 2.39425e+08 ops/cycle= -0.00431112
multibord lib
gdr_init (dgemmbody.c)
grape_init (testmatmul32.c)
SING_openMC (sing_chip.c)
CTRL_open (ctrl.c)
hib_openMC (
use 24 22 20
複数ボードだと計算間違えると、、、、 i 行列のほうがおかしい。
間違えの例:
index: 1044 1964, data: 6.2749866559918388e-01 4.5666739620376262e-01 3fe4147814e10740 3fdd3a09e2f60e80
index: 1044 1967, data: 1.7915175719931398e+00 1.6885521591134278e+00 3ffcaa0e545eb7c0 3ffb044f44cfb7c0
index: 1045 1965, data: 9.6876898867483874e-01 4.8733740306923323e-01 3fef0027d2779900 3fdf308938133200
index: 1045 1966, data: 1.2053199343074468e+00 5.5101685886733520e-01 3ff348fd8e3113e0 3fe1a1ee1b8c27c0
index: 1046 1964, data: 1.2470400469103211e+00 5.8659476765772212e-01 3ff3f3e043a483a0 3fe2c56263e30740
index: 1046 1967, data: 1.3884263863251221e+00 1.3552665955462402e+00 3ff636fe9622b7c0 3ff5af2c0693b7c0
index: 1047 1967, data: 1.5435423516423583e+00 8.0114474691389148e-01 3ff8b2597704b7c0 3fe9a2fa4eeb6f80
rms err = 5.449365e-04
index: 1556 1133, data: 1.5333820511025635e+00 7.1086790373581721e-01 3ff888bb9e1c2480 3fe6bf6e0bca4900
index: 1557 1132, data: 1.0344499822128697e+00 9.3491319561483266e-01 3ff08d1b6caf3ba0 3fedeacf13f87740
index: 1557 1134, data: 1.3921392483250585e+00 4.4712908760333647e-01 3ff64633cdf08be0 3fdc9dc352162f80
index: 1558 1132, data: 1.1007572683917957e+00 8.1348134795891980e-01 3ff19cb3a7493ba0 3fea080a092c7740
index: 1558 1133, data: 1.4385087387657052e+00 1.0558067747790858e+00 3ff70421bd402480 3ff0e495a5092480
index: 1558 1135, data: 1.0109914186295867e+00 1.2572980639832565e-01 3ff02d055678cfc0 3fc017ea0f4e7e00
index: 1559 1132, data: 7.9158628690104393e-01 4.2985248263332920e-01 3fe954acc3c67740 3fdb82b3fcc0ee80
index: 1559 1133, data: 1.2246184826674664e+00 1.0833069853709105e+00 3ff398098cd22480 3ff15539b49b2480
index: 1560 1135, data: 1.6490035214928724e+00 8.7883561729994142e-01 3ffa6251843ccfc0 3fec1f6bdf5b9f80
index: 1540 1564, data: 1.6219153633388501e+00 9.3446025700141178e-01 3ff9f35d8626b9a0 3fede71932677340
index: 1540 1566, data: 6.9475380656114538e-01 3.9468716533485093e-01 3fe63b6c55be73c0 3fd9428df4d0e780
index: 1540 1567, data: 4.0928498485151010e-01 1.9135936250528118e-01 3fda31b9a62b9700 3fc87e76addf2e00
index: 1542 1565, data: 1.5182041633931078e+00 1.3031136894102531e+00 3ff84a9072e6ca80 3ff4d98dbd6fca80
index: 1543 1565, data: 1.7801618873023983e+00 1.3787732813767946e+00 3ffc7b8b07f8ca80 3ff60f749281ca80
index: 1544 1564, data: 1.6035968011525270e+00 9.9617881181948320e-01 3ff9a8551e8eb9a0 3fefe0b263377340
index: 1544 1566, data: 1.0181195643850671e+00 1.0169697398701985e+00 3ff04a37bd8739e0 3ff045820fdc39e0
rms err = 5.583744e-04
index: 1556 1934, data: 1.3227512413541191e+00 7.4835231054384366e-01 3ff529fd34a5bfe0 3fe7f2808b757fc0
index: 1556 1935, data: 8.3659121193271346e-01 4.2796383575408470e-01 3feac55aeeebe780 3fdb63c26d9bcf00
index: 1557 1932, data: 1.5706772074090409e+00 1.4797546274976199e+00 3ff9217e6c664fa0 3ff7ad1330334fa0
index: 1557 1935, data: 1.1470220064504559e+00 9.3342317374411721e-01 3ff25a33bf57f3c0 3fedde9a4691e780
index: 1558 1932, data: 1.6229629069611988e+00 1.4699420623555639e+00 3ff9f7a7f4004fa0 3ff784e1f7cd4fa0
index: 1558 1933, data: 8.8163883675090915e-01 8.5236656463033000e-01 3fec3662a6575100 3feb46963ee95100
index: 1558 1935, data: 8.4750988791277848e-01 8.3284584867872979e-01 3feb1ecd0e73e780 3feaa6ac5655e780
index: 1559 1932, data: 1.5510520771249290e+00 9.4921421782508020e-01 3ff8d11bfb9a4fa0 3fee5ff67ece9f40
index: 1540 1178, data: 1.7650932584631036e+00 1.3368751061618340e+00 3ffc3dd26db7d360 3ff563d726bcd360
index: 1540 1179, data: 1.6916045981525514e+00 8.9981961550445533e-01 3ffb10cffbad4140 3feccb52819c8280
index: 1541 1178, data: 6.3692843823556444e-01 4.5569214514144818e-01 3fe461b7bf83a6c0 3fdd2a0f631b4d80
index: 1542 1176, data: 9.0797924955172249e-01 4.5540266532538709e-01 3fed0e2a7fc8ae40 3fdd255138855c80
index: 1542 1177, data: 1.0764478892066336e+00 7.2534302611677504e-01 3ff139216bffda00 3fe7360293f1b400
index: 1542 1179, data: 8.3843380284459101e-01 5.3884061173091879e-01 3fead47320628280 3fe13e2eaaa48280
index: 1044 3336, data: 1.3423246853333879e+00 1.0110625699006235e+00 3ff57a297301ed20 3ff02d4ff1feed20
index: 1044 3338, data: 1.0783731370807672e+00 8.5928741306050682e-01 3ff1410430ca5960 3feb7f48511eb2c0
index: 1045 3337, data: 4.6104507076552181e-01 2.0513956073727968e-01 3fdd81c32f3ae000 3fca42035c3dc000
index: 1045 3338, data: 7.5909817341524644e-01 5.6609281934432687e-01 3fe84a8840a8b2c0 3fe21d6eb032b2c0
index: 1045 3339, data: 1.2356426146333916e+00 8.7084095772748071e-01 3ff3c53130b64f40 3febddeddb2e9e80
index: 1046 3338, data: 4.9198394964840730e-01 4.0709021552682856e-01 3fdf7caa3f796580 3fda0dc41e8d6580
index: 1046 3339, data: 1.0907560976965698e+00 1.0598036324563083e+00 3ff173bcaa784f40 3ff0f4f4a7594f40
index: 1047 3336, data: 1.3891524558410495e+00 6.9459740789790914e-01 3ff639f7ecefed20 3fe63a2457d9da40
index: 1556 18793, data: 8.0133434673030024e-01 3.3776378838069832e-01 3fe9a487ed8bc800 3fd59dec02379000
index: 1556 18794, data: 1.1964836608688856e+00 6.6122904143534100e-01 3ff324cc0d1a1560 3fe528c9ce842ac0
index: 1557 18792, data: 1.5602226576925844e+00 9.5727990748543590e-01 3ff8f6ac08944920 3feea20978f89240
index: 1557 18795, data: 1.6987358252424229e+00 8.9246601202985687e-01 3ffb2e059ddf5b40 3fec8f14e1ceb680
3fe9a487ed8bc800 0100 1000 0111 1110 1101 100010111100100000000000
3fd59dec02379000 1101 1110 1100 0000 0010 001101111001000000000000
2009/12/17
mgv07-01 board 0
index: 20 1917, data: 1.3358618922551670e+00 9.7219225943754850e-01 3ff55fb0b8335680 3fef1c32f0f6ad00
index: 20 1918, data: 1.5958435966580211e+00 1.5689219021418168e+00 3ff988934b92d5e0 3ff91a4dda3ad5e0
index: 21 1918, data: 1.3798908326256125e+00 6.8056008049222072e-01 3ff6140868e2d5e0 3fe5c725ef15abc0
index: 21 1919, data: 1.6039484710828305e+00 1.3571315287309602e+00 3ff9a9c5df3c51c0 3ff5b6cf8cc451c0
index: 22 1917, data: 1.1131474723128179e+00 7.2753570082332431e-01 3ff1cf73b9535680 3fe747f8f336ad00
index: 20 12684, data: 1.1225098444929031e+00 1.0238974108442349e+00 3ff1f5cce1f88fa0 3ff061e240608fa0
index: 20 12685, data: 1.7751643038195937e+00 1.3024571599512740e+00 3ffc6712af5ee880 3ff4d6dd51a6e880
index: 20 12687, data: 1.0060189692187436e+00 7.0900985702176911e-01 3ff018a758bf33c0 3fe6b035708e6780
index: 21 12686, data: 1.1237877294770371e+00 9.0583479503401776e-01 3ff1fb08d79bffe0 3fecfc994087ffc0
index: 532 12750, data: 9.1473628034372467e-01 6.9243164058797646e-01 3fed458505114fc0 3fe6286666614fc0
index: 533 12748, data: 1.3727175685776061e+00 7.3997947903942674e-01 3ff5f6a6b27af7a0 3fe7ade971c5ef40
index: 533 12749, data: 8.6219549303044118e-01 5.3086058279134818e-01 3feb971b00aa6100 3fe0fccf553a6100
index: 533 12750, data: 4.3301762583222825e-01 4.0646799095929254e-01 3fdbb68f8f629f80 3fda039252029f80
index: 533 12751, data: 7.2709243213078878e-01 3.7458594182292870e-01 3fe7445759257780 3fd7f937506aef00
index: 534 12749, data: 9.5147879755225517e-01 5.4374313047722467e-01 3fee7283a9ca6100 3fe16657fe5a6100
index: 535 12748, data: 1.0767810795655137e+00 7.8452760916795938e-01 3ff13a7ecc1af7a0 3fe91ad9a505ef40
index: 536 12749, data: 6.7164086558025815e-01 1.1110368483335265e-01 3fe57e14fc0a6100 3fbc714a84d30800
index: 536 12750, data: 1.3369217208914890e+00 8.9763710066699076e-01 3ff5640807c8a7e0 3fecb97170e14fc0
index: 536 12751, data: 8.2918605864300332e-01 6.5262866501483074e-01 3fea88b133857780 3fe4e25582957780
index: 4 12300, data: 1.3153935394093210e+00 1.2423129341641257e+00 3ff50bda18921fa0 3ff3e08386fa1fa0
index: 4 12302, data: 1.3873335529360631e+00 1.2854795588655108e+00 3ff63284aae80fe0 3ff4915303900fe0
index: 4 12303, data: 1.1306395221639320e-01 6.1400253704263719e-02 3fbcf1c259203c00 3faf6fdaa3407800
index: 5 12300, data: 1.1164979539189304e+00 9.2069090824404753e-01 3ff1dd2cf5621fa0 3fed764cc7943f40
index: 5 12302, data: 1.6465161897949585e+00 1.4786984506072187e+00 3ffa58215c380fe0 3ff7a8bfb4e00fe0
index: 6 12300, data: 6.7214948756916471e-01 3.5361600146459438e-01 3fe5823fa4643f40 3fd6a1a502687e80
index: 6 12301, data: 1.9172739358796491e+00 1.4434784708023756e+00 3ffead276f413880 3ff7187ce1893880
index: 6 12302, data: 7.7377133641947893e-01 5.3998985211455164e-01 3fe8c2bc1b101fc0 3fe14798cc601fc0
index: 6 12303, data: 1.5458439726210003e+00 1.2234588385619958e+00 3ff8bbc6e3b203c0 3ff39349933a03c0
rms err = 1.509920e-04
board 1
index: 532 29293, data: 1.1737817898377045e+00 7.1613636717509621e-01 3ff2c7cf69ffe480 3fe6ea96d08fc900
index: 532 29295, data: 4.8899143419929203e-01 4.8771933522310462e-01 3fdf4ba2ba7a3f00 3fdf36cb289a3f00
index: 533 29292, data: 1.2976356707510845e+00 8.0598477052965478e-01 3ff4c31d9efffba0 3fe9caa092cff740
index: 533 29294, data: 1.5098510703435224e+00 1.3244109646081981e+00 3ff82859988f4be0 3ff530c98d374be0
index: 534 29292, data: 1.0115994953082250e+00 8.4839402965710775e-01 3ff02f82f3cffba0 3feb260b3c6ff740
index: 534 29293, data: 6.8258608551539623e-01 5.6042039918091291e-01 3fe5d7bec63fc900 3fe1eef6c2cfc900
index: 535 29294, data: 8.0803815716785010e-01 2.3676431119815078e-01 3fe9db72d65e97c0 3fce4e4afeba5f00
index: 535 29295, data: 1.2570851587015426e+00 8.3605903140504267e-01 3ff41d0553ce8fc0 3feac0fedead1f80
index: 536 29293, data: 1.5333093265055879e+00 7.4662337649922961e-01 3ff8886f5c3fe480 3fe7e456b50fc900
なんらかの意味で最初のほうで起きている。なので、
OMP_NUM_THREADS = 2 だと止まる。
mgv07-02 で、 2kx32k 1000回実行
board 0 でも 10 回程度。なので、エラーレートは 1/100 程度。
1つだけ動かすと 1000 回でも完全に no error
これは、 mgv07-02 で
メモリに送るタイミングをずらしてもやはり最初のほうにエラーがでる。
最初のほうだけしかエラーがでないのは何故?
1560, 536, 1046, 21 etc
bb0 用のデータを全部0にすると答はあう。
i: 1556-1558 etc
j の値
1484-1487 3772-3775 26716-26719 20108-20111 32124-32127 11276-11279
16300-16303
256 で割ると
207 188 92 143 124 12 172
16 で割ると: 12-15
i
20 1556 1540 532 1044 1556 536 24
j: 16 でわったあまり 12-15
i: 512でわったあまり 32 より小さくて、 4-7?, 20-27
a でみると、例えば a[0][0]-a[15][7] が連続アドレスに入る
aem の構造:
連続領域:pe 毎、 16x4 の領域 64語
その上: BB 1024語
その上: PE の中の4領域、連続は縦に2つ (32x4) で、4個で 32x8 4096語
その上: PE 131072語
エラーの入りかた: 奇数番目の PEの後半領域、BBは 0
16語 (256バイト)の連続領域でのエラー: ペイロードとしか思えない、、、
index: 1044 22700, 3feb5dda591423a0 3fc75e01f7908e80
index: 1044 22701, 3fcda6567453b200 3fdd944c5349d900
index: 1044 22702, 3fe1f2b5b463b3e0 3fdcc695db6767c0
index: 1044 22703, 3fe6dcb5748ed7c0 3fda26f9773daf80
index: 1045 22700, 3fc75e01f7908e80 3fe573c6a2b423a0
index: 1045 22701, 3fdd944c5349d900 3faa8d6b634ec800
index: 1045 22702, 3fdcc695db6767c0 3f81e009c0ecf800
index: 1045 22703, 3fda26f9773daf80 3fcd15900abb5f00
index: 1046 22700, 3fe573c6a2b423a0 3fd465598f084740
index: 1046 22701, 3faa8d6b634ec800 3f469d0b13b20000
index: 1046 22702, 3f81e009c0ecf800 3fce7d55814ecf80
index: 1046 22703, 3fcd15900abb5f00 3fc5c9ad26fb5f00
なのは変わらないのですが、問題は何をどこまで並列にできるかです。
なわけですから、まずUPDATE に必要な上側の正方形パネルについて考えます。
というのが最速でしょう。逆行列作成は 0.1秒程度、転送や行列積は
(転送は 1GB/s 程度を仮定すれば)ずっと短いので、その程度です。
ということになります。いま一つよくわからないので、プロセッサについて、
a) 対角パネルをもつ
b) 対角パネルと同じ列
c) 対角パネルと同じ行
d) 対角パネルの隣
e) 次の対角パネルと同じ列(対角パネルを含み、それより下)
f) 上のどれでもない
ケースについて、することを記述してみます。
b) 対角パネルと同じ列
c) 対角パネルと同じ行
d) 対角パネルの隣
e) 次の対角パネルと同じ列(対角パネルを含み、それより下)
f) 上のどれでもないつまり、対角パネルの隣の右、対角パネルの下
今回の計算方法の通常の方式との違いは、UPDATE と PUPDATE の並列動
作が前提になっていることで、これが暗黙に lookahead をしていることに
なります。
が全て並行して進んでいる「かもしれない」わけで、メモリアクセスの負荷を
大きく下げることができる row major はかなり魅力的です。もっとも、プロ
セッサグリッドが大きい場合には、 それぞれのプロセッサが受け取るデータ
量があまり大きくなく、平均的にはあまり意味がないような気がします。
行き先の新しい配列を用意する
自分の中に行き先がある行列は、この新しい配列にコピー
それ以外は他のプロセッサに送る
他のプロセッサからくるデータを新しい配列にコピーする
が手順になり、それ以外は
ピボットのプロセッサに送るべきものを送る
ピボットから受け取ったものを格納する
というだけ、ということになります。両方のプロセッサでバッファがちゃんと
あれば、順序がおかしくてもデータが壊れたりはしません。
対角パネルプロセッサ 対角の隣 次の対角
1 最初の縦パネルの消去
1 L の送出 L のGRAPE-DR への転送 Lの GRAPE-DR への転送
2 ピボットの送出 ピボット受け取り ピボット受け取り
2 対角パネル右に送出 1パネル分交換、 1パネル分交換
3 行交換 DTRSM DTRSM、下に放送 1パネル分アップデート
3 U放送 残りのDTRSM
4 アップデート U放送、アップデート 縦パネル消去開始
4 残りアップデート
対角の下
1 最初の縦パネルの消去
1 L の送出
2 ピボット送出
3 行交換
3 U 受け取り
4 アップデート
このように見ると、最初のパネル消去においては、結局 DTRSM をしないとい
けない分だけ対角パネルをもつプロセッサの仕事は同じ列のプロセッサより多
く、同じ列でもその分下のプロセッサは遊んでいることがわかります。
0|-----|--------|--------|--------|-----|--------|--------|--------|
P0 U0 U1 U2 P4 U3 U4 U5
1 |-----|--------|--------|--------|--------|-----|--------|
P1 U0 U1 U2 U3 P5 U4
2 |--------|-----|--------|--------|--------|--------|-----|--------|
U0 P2 U1 U2 U3 U4 P6 U5
3 |--------|--------|-----|--------|--------|--------|--------|
U0 U1 P3 U2 U3 U4 U5
この状況を示したのが上のタイムシーケンスです。ここでは、4つプロセッサ
列があって、順番にピボットパネルがくることを想定します(ブロックサイク
リックにすれば当然こうなります)。そうすると、依存関係は
Pn -> Un
Pn -> Pn+1
だけなので、 遅れて終わることで穴があくわけではなく、また P が隠蔽され
ないことのインパクトはプロセッサ数が多いとあまり大きくないことがわかり
ます。ちなみに、普通に Ui が終わった後で Pi+1 を始めてみると
0|-----|--------| --------|
P0 U0 U1
1 |--------|-----|--------|
U0 P1 U1
2 |--------| --------|
U0 U1
3 |--------| --------|
U0 U1
とやたら空きができて全く話になりません。従って、実装の単純さを優先する
なら、並列版では Pupdate と update の並列動作にこだわらず、
を実現することが必要、ということになります。
が並行して進む必要があるからです。うーん、このことを考えると、行交換と
放送を混ぜるアルゴリズムはやはり魅力的ですね。
という同一の動作をすればよいことになり、話がだいぶ簡単になります。
列の数だけ以下を繰り返す
MPI_ALLREDUCE (最大値とそれがあるプロセッサがわかる)
問題のプロセッサでその行をスケール
その行を放送
問題のプロセッサが対角パネルでなければ、対角パネルから交換される
べき行を受け取る
対角パネル、および最大値のソースプロセッサでは、行を更新
右側(があれば)を update
この部分の通信がボトルネックにならないか、というのが問題ですが、
1行あたりの処理にミリ秒程度のはずなので、 ALLREDUCE と SEND/RECEIVE の
レイテンシがあわせて 20マイクロ秒程度なら問題ないはずで、 IB ならさす
がにもうちょっと小さいと思うのでおそらく致命的な問題にはならないはずで
す。但し、かなりクリティカルであることはわかると思います。
処理するパネルが残っていたら以下を繰り返す。
自分がピボット列であれば列パネル消去
アップデート処理
で、列パネル消去は
最初のパネルでなければ
左から L をもらう(通信はずっと前に起動している)
1パネル分について update 処理・送れる L は送る
本当の列パネル処理
で、本当の列パネル処理は再帰で、アップデート処理は
L がまだきてなければくるまで待つ
次の L を待ち始める
適当にブロック化して、
行交換
DTRSM
UPDATE
を並行して行う
です。ここで一つ問題なのは、次のLを待つのと他の処理をスレッドで並行処
理した時にコアの数が足りなくなったりしないか、ということですが、これは
やってみないとわかりません。
A00 A01 A02 A03
A10 A11 A12 A13
A20 A21 A22 A23
A30 A31 A32 A33
で、これを
A00 A02 A01 A03
A20 A22 A21 A23
A10 A12 A11 A13
A30 A32 A31 A33
というふうに格納するわけです。そうすると、まず Ax0 列の処理では、 A20
と A10 が入れ替わっていますがそれを処理するプログラムが意識する必要は
ありません。
A22 A21 A23
A12 A11 A13
A32 A31 A33
という状態になっています。 Ax1 列の処理では、通常の場合と同じですが、
を意識する必要があります。行入れ替え等の判定のためには、(プロセッサ番号,
行位置)や(プロセッサ番号, 列位置)とグローバルな行位置、列位置の相互変換
の関数ないしマクロを作っておいて基本的にはグローバルな側で処理するのが
安全そうです。とはいえ、アップデートやスワップ処理では、結局ローカルに
考えたプロセッサ内部ではサイクリックブロッキングを意識するところは特に
なく、意識する必要があるのは次のブロックがどこか、というのの判定だけの
ように思われます。
 でない時はどうでしょう?もっとも簡単なケース
として 2 プロセッサで縦にわけてみます。
でない時はどうでしょう?もっとも簡単なケース
として 2 プロセッサで縦にわけてみます。
A00 A02 A01 A03
A20 A22 A21 A23
A10 A12 A11 A13
A30 A32 A31 A33
この場合には、
A22 A21 A23
A12 A11 A13
A32 A31 A33
A22 A23
A32 A33
と、穴があいてしまいそうです、、、あれ、これはおかしいですね。
A00 A02 A01 A03
A10 A12 A11 A13
A20 A22 A21 A23
A30 A32 A31 A33
と、中のブロックを
1 2
の形にすれば
A12 A11 A13
A22 A21 A23
A32 A31 A33
A22 A23
A32 A33
となって穴があくことはない、ということがわかります。割り当ての一般式を導出
しておきましょう。
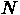 、 ブロックサイズを
、 ブロックサイズを 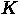 、 プロセッサの行、列数をそ
れぞれ
、 プロセッサの行、列数をそ
れぞれ  とします。
とします。
i行は、ブロック i/K の i%K 行にあります。
逆に、 ブロック l の i' 行は l*K+i' 行です。
ブロック l はプロセッサ行 l%P の l/P 個めのブロックになります
逆に、プロセッサ行 p のブロック l' は、p+Pl' ブロックです。
という感じですね。
0 1
であって
0
1
ではない。これは、 npcol が「コラムの数」と思うこと。
0: 5.688e-01 9.527e-01 7.854e-01 3.638e-01 1.000e+00
1: 5.050e-01 9.333e-01 2.201e-01 1.810e-01 1.000e+00
0: 5.366e-02 8.510e-01 5.746e-01 8.587e-01 1.000e+00
1: 6.317e-01 8.170e-01 3.353e-01 3.798e-01 1.000e+00
答
0: 1.000e+00 1.293e+00 5.308e-01 6.013e-01 3.168e-01
1: 2.622e+00 1.000e+00 2.228e+00 1.000e-01 8.658e-01
Printmat_MP: Proc 1, loc = 0 1
0: -7.510e-01 -4.168e-01 1.000e+00 2.241e-01 -2.017e-01
1: 5.281e-02 7.692e-01 -1.177e+00 1.000e+00 4.217e-01
ちなみに、 q=1, p=2 ではまだ全然おかしい
make lu2_mpi ; mpirun -n 4 lu2_mpi -n 32 -q 4 -p 1
でも動いた。縦方向は一応大丈夫なはず?
for(i=0;i<n;i+=m){
column_decomposition(n, a, m, pv,i);
process_right_part(n,a,m,awork, pv,i,n+1);
}
column_decomposition、process_right_part の中身は以下の通り。
という辺りに注意が必要。
void column_decomposition(int n, double a[n][RDIM], int m, int pv[], int i)
{
int j, k;
int ip,ii;
double ainv;
for(ip=0;ip<m;ip++){
ii=i+ip;
int p = findpivot(n,a,ii);
if (fabs(a[p][ii]) > 2* fabs(a[ii][ii])){
pv[ip]=p;
swaprows(n,a,p,ii,i,i+m);
nswap++;
}else{
pv[ip]=ii;
}
// normalize row ii
ainv = 1.0/a[ii][ii];
scalerow(n,a,ainv,ii,i,ii);
scalerow(n,a,ainv,ii,ii+1,i+m);
// subtract row ii from all lower rows
vvmulandsub(n, a, ii, ii+1, i+m, ii+1, n);
}
}
void process_right_part(int n,
double a[n][RDIM],
int m,
double awork[][n],
int pv[],
int i,
int iend)
{
int ii;
for(ii=i;ii<i+m;ii++){
swaprows_simple_with_scale(n,a,pv[ii-i],ii,i+m,iend,
1.0/a[ii][ii] );
}
solve_triangle(n,a,m,awork, i,iend);
mmmulandsub(n, a, i,i+m, i+m, iend, i+m, n);
}
global index で colum l1-l2 が与えられた時に、自分のインデックスで関係
するのはどこからどこまでかを判定する関数が必要。
bl2 がかかっていればかかっている
そうでないとき: bl1 のあとの最初の自分のブロックが bl2 より手前ならば
かかっている
こんな感じかな。
0000111122223333000011112222333300001111222233330000111122223333
0 1 2 3 4 5 6 7 8 9 A B C D E F
X Y
X: 18, Y: 38
C1 C2
0: 6 11
1: 4 10
2: 4 7
3: 4 7




えーと、本当にレイテンシは減るのかな?
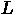 ,
, 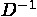 はカレントの縦パネルをもつプロセッサで計算できる
ので、 U を待つことなく計算を始めることができる。このため、クリティ
カルパスが短くなる。
はカレントの縦パネルをもつプロセッサで計算できる
ので、 U を待つことなく計算を始めることができる。このため、クリティ
カルパスが短くなる。
処理するパネルが残っていたら以下を繰り返す。
L の処理を行う。つまり
L がまだきていなければくるまで待つ
Dm (<$D^{-1}$> も待つ
L' = L*Dm を計算する
さらに次の L を待ち始める
上の L の処理と並行して、U の処理。
1パネルについて行交換、放送
さらにその分の DGEMM
このパネルがピボットであれば再帰パネル分解
適当にブロック化して
行交換、放送
さらにその分の DGEMM
0|-----|--------|--------|--------|-----|--------|--------|--------|
P0 U0 U1 U2 P4 U3 U4 U5
1 |-----|--------|--------|--------|--------|-----|--------|
P1 U0 U1 U2 U3 P5 U4
2 |--------|-----|--------|--------|--------|--------|-----|--------|
U0 P2 U1 U2 U3 U4 P6 U5
3 |--------|--------|-----|--------|--------|--------|--------|
U0 U1 P3 U2 U3 U4 U5
このシーケンスで空きがでないためには、
0|--------|--------|--------|--------|-----|--------|--------|--------|
P0 U0 U1 U2 P4 U3 U4 U5
1 |--------|--------|--------|--------|--------|-----|--------|
P1 U0 U1 U2 U3 P5 U4
2 |--------|--------|--------|--------|--------|--------|-----|
U0 P2 U1 U2 U3 U4 P6 U5
3 |--------|--------|--------|--------|--------|--------|--------|
U0 U1 P3 U2 U3 U4 U5
0|----------|--------| --------| --------|---------|--------|
P0 U0 U1 U2 P4 U3 U4 U5
1 |----------|--------|--------|--------|--------|-----|--------|
P1 U0 U1 U2 U3 P5 U4
2 |--------| --------|--------|--------|--------|--------|-----|
U0 P2 U1 U2 U3 U4 P6 U5
3 |--------| --------| --------|--------|--------|--------|
U0 U1 P3 U2 U3 U4 U5
と、図を書いて考えるまでもなく、 Pi が(正確にいうと Pi の開始から Pi+1
の開始までが) Ui より長くてはいかんわけですね。このためには、、、、
Pi 自体はそうはいってもそんなにかからない(はず)?上の例で、演算数は
L はきている。
DmU を1ブロック計算する。
これからPi+1 のアップデートをする
Pi+1 のパネル分解をする
L を送る
DmU の計算のあと アップデートを、適当なブロックサイズで
先に LDm を計算するなら
L はきている。
LDm を計算する
L をGDRに送る
U1パネル使って、 Pi+1 のアップデートをする
Pi+1 のパネル分解をする
アップデートを、適当なブロックサイズで
この場合、パネル分解の前に L 相当の行列を2回送ることになって、レイテン
シは増える。
L はきている。
DmU を1ブロック計算する。
これからPi+1 のアップデートをする
Pi+1 のパネル分解をする
LDm を計算する
L をGDRに送る
アップデートを、適当なブロックサイズで
この手順は画期的で、 EM 上に複数行列を置く必要がない。
for (ii=0;ii<nb;ii++){
i = ii+ifirst;
MP_update_single_blocked_local(nnrow, nncol, a, parms, controls,
i,c1,nncol,nb-ii);
}
これをその形に。
の形にすれば、後は DTRSM にできるはず
した。あとするべきことは転置。
0: 6.317e-01 1.293e+00 5.308e-01 6.013e-01 7.901e-01
1: 6.866e-02 7.816e-01 6.987e-01 1.057e+00 3.521e-02
Printmat_MP: Proc 1, loc = 0 1
0: 5.050e-01 2.802e-01 -2.437e-01 -4.189e-01 7.621e-01
1: 5.688e-01 2.170e-01 3.319e-01 -2.077e-01 5.704e-01
正しい
0: 6.317e-01 1.293e+00 5.308e-01 6.013e-01 3.168e-01
1: 6.866e-02 7.816e-01 6.987e-01 1.057e+00 8.658e-01
Printmat_MP: Proc 1, loc = 0 1
0: 5.050e-01 2.802e-01 3.319e-01 -6.258e-01 -2.017e-01
1: 5.688e-01 2.170e-01 4.265e-01 -5.714e-01 4.217e-01
mpirun -np 2 lu2_mpi_ok -n 4 -p 2
縦パネル分解 (関係しないプロセッサは同期待ち)
L 放送
行交換
DTRSM (関係しないプロセッサは同期待ち)
U放送
UPDATE
これを
縦パネル分解
Dm 計算、放送
L放送開始
Dm 受け取り起動
L 受け取り起動
ここからループ
* Dm 受け取る
* L 受け取る
* 1ブロック分行交換
* 1ブロック分放送
* DmU を1ブロック計算する。
* これからPi+1 のアップデートをする
* Pi+1 のパネル分解をする
* Dm 計算、放送
* L放送開始
LDm を計算する
L をGDRに送る
次の Dm 受け取り起動
次の L 受け取り起動
Dm, L の受け取りと並行してアップデートを、適当なブロックサイズで
1ブロック行交換
1ブロックスケール、放送
計算
うーん、U をもつ行だと、DmU を、、、計算、あれ、D を憶えておいて計算し
ないですますことはできない?
U00 U01 b0
U11 b1
U01 b1 は U01= D0 U'01 なら (D0 U'01) b1 と同じなので、 D0 (U'01 b1)
と計算してもよい。なので、 Dm を憶えておけば U の変形は必要ない。
loop:
rfact
update
計算手順として lookahead すればいい?
初期化:
縦パネル分解
Dm 計算、放送
L放送開始
Dm 受け取り起動
L 受け取り起動
Loop:
* Dm 受け取る
* L 受け取る
* 1ブロック分行交換
* 1ブロック分放送
* DmU を1ブロック計算する。
* これからPi+1 のアップデートをする
* Pi+1 のパネル分解をする
* Dm 計算、放送
* L放送開始
LDm を計算する
L をGDRに送る
次の Dm 受け取り起動
次の L 受け取り起動
Dm, L の受け取りと並行してアップデートを、適当なブロックサイズで
1ブロック行交換
1ブロックスケール、放送
計算
まず、 Dm, L, U の転送を分離する。
334 23:07 mpirun -np 2 lu2_mpi -n 8 -p 2
335 23:07 mpirun -np 8 lu2_mpi -n 16 -p 2 -q 4
336 23:08 mpirun -np 16 lu2_mpi -n 16 -p 4 -q 4
337 23:09 mpirun -np 16 lu2_mpi -n 32 -p 4 -q 4
338 23:10 mpirun -np 16 lu2_mpi -n 54 -p 4 -q 4
339 23:10 mpirun -np 16 lu2_mpi -n 64 -p 4 -q 4
340 23:11 mpirun -np 16 lu2_mpi -n 64 -p 2 -q 8
341 23:12 mpirun -np 16 lu2_mpi -n 64 -p 8 -q 2
342 23:12 mpirun -np 16 lu2_mpi -n 128 -p 8 -q 2
343 23:12 mpirun -np 16 lu2_mpi -n 64 -p 8 -q 2 -b 4
全てで正しい答になったような気がする。
mpirun -np 2 lu2_mpi -n 64 -p 2 -q 1 -b 32
ano3 では動作したりしなかったり。
縦通信はループ分割の必要あり。
L(DU) を (LD)U に変更する必要あり。
一応やった。これはまだ最適化されてない(backward substitution の時にす
るようになっていない)。
time mpirun -np 2 lu2_mpi -n 4096 -p 2 -b 256
で、 横通信は並列にしていない時に、時間がこんな感じ
esum = 1.580317e-23
Proc:0 lbl:0 Error = 3.975320e-12
Proc:0 lbl:1 Left bcast etc time=2.66596e+09 ops/cycle=0.0029499
Proc:0 lbl:1 update time=5.39088e+09 ops/cycle=3.85906
Proc:0 lbl:1 update matmul time=4.79956e+09 ops/cycle=2.0519
Proc:0 lbl:1 update swap+bcast time=7.46533e+07 ops/cycle=0.39592
8.720u 0.152s 0:05.43 163.3% 0+0k 0+0io 15pf+0w
0|-----|--------|--------|--------|-----|--------|--------|--------|
P0 U0 U1 U2 P4 U3 U4 U5
1 |-----|--------|--------|--------|--------|-----|--------|
P1 U0 U1 U2 U3 P5 U4
2 |--------|-----|--------|--------|--------|--------|-----|--------|
U0 P2 U1 U2 U3 U4 P6 U5
3 |--------|--------|-----|--------|--------|--------|--------|
U0 U1 P3 U2 U3 U4 U5
基本的にはなっている。
{
omp_set_nested(1);
fprintf(stderr,"Omp_get_nested=%d\n", omp_get_nested());
}
をいれると、、、
P0, enter process_lmat, time=0.0156181
P0, enter dls_phase_2, time=0.0211031
P0, enter dls_phase_1, time=0.021112
P0, end dls_phase_2, time=0.0228231
P0, end process_lmat, time=0.026711
P0, end dls_phase_1, time=0.034306
P0, enter dls_phase_1, time=0.0436211
P0, enter dls_phase_2, time=0.0436201
P0, end dls_phase_2, time=0.045222
P0, end dls_phase_1, time=0.127567
P0, enter dls_phase_2, time=0.128052
P0, end dls_phase_2, time=0.129799
0|-----|--------|--------|--------|-----|--------|--------|--------|
P0 U0 U1 U2 P4 U3 U4 U5
1 |-----|--------|--------|--------|--------|-----|--------|
P1 U0 U1 U2 U3 P5 U4
2 |--------|-----|--------|--------|--------|--------|-----|--------|
U0 P2 U1 U2 U3 U4 P6 U5
3 |--------|--------|-----|--------|--------|--------|--------|
U0 U1 P3 U2 U3 U4 U5
LCOMM -- -- -- ------- --
あれ?
0|-----|--------|--------|--------|-----|--------|--------|--------|
P0 U0 U1 U2 P4 U3 U4 U5
1 |-----|--------|--------|--------|--------|-----|--------|
P1 U0 U1 U2 U3 P5 U4
2 |--------|-----|--------|--------|--------|--------|-----|--------|
U0 P2 U1 U2 U3 U4 P6 U5
3 |--------|--------|-----|--------|--------|--------|--------|
U0 U1 P3 U2 U3 U4
少し違う方式を考えるべき?
実際のデータ量 16K*2K*8 256MB くらい。 1.2GB/s でるので、0.2-0.3 秒
計算にかかる時間 20K*20K*2K*2= 1.6T 演算。1Tf でたとして 1.6 秒。
`which mpirun` -np 4 lu2_mpi -p 2 -q 2 -b 2048 -n 16384
の場合。行列は最大で 2048x8192 になっているかな?とすると演算数は
2K*2K*8K*2 = 64G, 10 G 出れば6秒。もうちょっと行列小さいところと思うと
4-5秒。まああってる。
0|-----|--------|--------|--------|-----|--------|--------|--------|
P0 U0 U1 U2 P4 U3 U4 U5
1 |-----|--------|--------|--------|--------|-----|--------|
P1 U0 U1 U2 U3 P5 U4
2 |--------|-----|--------|--------|--------|--------|-----|--------|
U0 P2 U1 U2 U3 U4 P6 U5
3 |--------|--------|-----|--------|--------|--------|--------|
U0 U1 P3 U2 U3 U4
リングでの非同期通信に変更する。
acolinv2 (diagonal)
pvp2
scalep2
l
基本的には受け取ったものを隣に回すだけ。
P3 は 0 には速くいく必要あり。
基本的に、current は単純に細かくわけて ISEND して、それ以外は
順番にステータスみて受けとるだけ。
色々考えるのは面倒なので、最初に、
ポインタ
データ数
ハンドル
の構造体の配列を作ることにする。
lu_mpi look i=2048 end
P0, enter process_lmat, time=65.715
P1, enter process_lmat, time=66.7893
P1, enter dls_phase_2, time=71.2159
P1, enter dls_phase_1, time=71.2409
P0, enter dls_phase_2, time=71.2662
P0, enter dls_phase_1, time=71.2742
P1, end dls_phase_1, time=73.2175
P0, end dls_phase_1, time=73.2175
P0, end dls_phase_2, time=76.4328
P0, enter dls_phase_2, time=76.6744
P1, end dls_phase_2, time=78.45
P1, enter dls_phase_2, time=78.6682
P2, enter process_lmat, time=78.9553
P3, enter process_lmat, time=79.5863
P1, end process_lmat, time=80.0502
P3, end process_lmat, time=80.0501
P3, enter dls_phase_2, time=80.6247
P2, enter dls_phase_2, time=80.6957
P2, enter dls_phase_1, time=80.8317
P0, end dls_phase_2, time=80.8975
P3, enter dls_phase_1, time=81.0377
P0, end process_lmat, time=81.2736
P2, end process_lmat, time=81.2736
P1, end dls_phase_2, time=82.7323
P3, end dls_phase_1, time=83.0167
P2, end dls_phase_1, time=83.0168
P2, end dls_phase_2, time=84.3344
P2, enter dls_phase_2, time=84.5809
P3, end dls_phase_2, time=84.7351
P3, enter dls_phase_2, time=84.7588
P2, end dls_phase_2, time=86.9622
lu_mpi look i=4096 end
0|-----|--------|-----|--------|--------|-----|--------|
P0 U0 P2 U1 U2 P4 U3
1 |-----|--------|--------|-----|--------|--------|
P1 U0 U1 P3 U2 U3
0 1
1.71 lmat start p1 start
3.26 p1 end/U0 start
3.34 lmat send end
5.98 U0 end
5.98 rfact start
7.10 U0 end
7.32 P2 end
mpirun -np 2 lu2_mpi -b 1024 -n 16384 -p 2 -g
P0, enter rfact, time=3.17814
P0, end rfact, time=3.17821
P0, enter process_lmat, time=3.1783
P1, enter rfact, time=3.1959
P0, enter dls_phase_2, time=3.27343
P0, enter dls_phase_1, time=3.28942
P0, end dls_phase_1, time=3.31881
P1, end rfact, time=6.15371
P1, enter process_lmat, time=6.15385
P1, enter dls_phase_2, time=6.23722
P1, enter dls_phase_1, time=6.25321
P1, end dls_phase_1, time=6.26754
P0, end dls_phase_2, time=6.37445
P1, end process_lmat, time=6.42638
P0, end process_lmat, time=6.42638
P0, enter dls_phase_2, time=6.42644
P0, enter dls_phase_1, time=6.44134
P0, end dls_phase_1, time=6.47432
P1, end dls_phase_2, time=7.89122
P1, enter dls_phase_2, time=7.89137
P1, enter dls_phase_1, time=7.89139
P1, end dls_phase_1, time=7.92618
P0, end dls_phase_2, time=8.02559
P0, enter dls_phase_2, time=8.02572
P0, enter dls_phase_1, time=8.02575
P0, end dls_phase_1, time=8.07419
P1, end dls_phase_2, time=9.49075
P1, enter dls_phase_2, time=9.49088
P1, enter dls_phase_1, time=9.4909
P1, end dls_phase_1, time=9.52613
P0, end dls_phase_2, time=9.62465
P0, enter dls_phase_2, time=9.62478
P0, enter dls_phase_1, time=9.6248
P0, end dls_phase_1, time=9.65821
P1, end dls_phase_2, time=11.0905
P1, enter dls_phase_2, time=11.0906
P1, enter dls_phase_1, time=11.0906
P1, end dls_phase_1, time=11.1261
P0, end dls_phase_2, time=11.2239
P0, enter dls_phase_2, time=11.224
P0, enter dls_phase_1, time=11.2241
P0, end dls_phase_1, time=11.2581
P1, end dls_phase_2, time=12.6899
P1, enter dls_phase_2, time=12.69
P1, enter dls_phase_1, time=12.69
P1, end dls_phase_1, time=12.726
P0, end dls_phase_2, time=12.823
P0, enter dls_phase_2, time=12.8231
P0, enter dls_phase_1, time=12.8232
P0, end dls_phase_1, time=12.8527
P1, end dls_phase_2, time=14.289
P1, enter dls_phase_2, time=14.2891
P1, enter dls_phase_1, time=14.2892
P1, end dls_phase_1, time=14.3166
P0, end dls_phase_2, time=14.4165
P0, enter dls_phase_2, time=14.4167
P1, end dls_phase_2, time=15.8832
P1, enter dls_phase_2, time=15.8833
P0, end dls_phase_2, time=16.0225
P0, end mult_diag, time=16.7937
P0, end ld_phase1, time=16.7938
P1, end dls_phase_2, time=17.4919
P1, end mult_diag, time=18.3679
P1, end ld_phase1, time=18.3679
P0, end ld_phase2, time=18.4555
lu_mpi look i=0 end
P0, enter rfact, time=18.4556
P1, end ld_phase2, time=20.0277
これで 1.5 倍程度になるのはやむをえない?
rfact に 3 秒。これはちょっと遅い感じあり。
0.732 1.09
0.375 0,383
正しいもの
mpirun -np 2 lu2_mpi -n 8192 -p 2 -q 1 -b 256 -g
DU on の時に
P0, enter backward_sub, time=13.2305
P1, end backward_sub, time=13.378
cpsec = 25.4856 wsec=13.3843 27.3831 Gflops
mpirun -np 2 lu2_mpi -n 8192 -p 2 -q 1 -b 1024 -g
off
P0, end lmat/dls, time=19.0987
P0, end mult_diag, time=19.1032
P0, enter backward_sub, time=19.1033
P1, end lmat/dls, time=19.2076
P1, end mult_diag, time=19.2118
P1, enter backward_sub, time=19.2118
P0, end backward_sub, time=19.2818
P1, end backward_sub, time=19.2818
cpsec = 37.2263 wsec=19.2828 19.0068 Gflops
mpirun -np 1 lu2_mpi -b 512 -n 8192 で
P0, enter rfact, time=0.421307
P0, end rfact, time=0.797415
P0, enter process_lmat, time=0.797537
P0, end process_lmat, time=0.811278
P0, end lmat/dls, time=2.34804
P0, end mult_diag, time=2.34928
P0, end ld_phase1, time=2.34928
P0, end ld_phase2, time=2.46584
mpirun -np 1 lu2_mpi -b 1024 -n 8192 で
P0, enter rfact, time=1.1541
P0, end rfact, time=2.18727
P0, enter process_lmat, time=2.1874
P0, end process_lmat, time=2.24038
P0, end lmat/dls, time=4.63959
P0, end mult_diag, time=4.64479
P0, end ld_phase1, time=4.6448
P0, end ld_phase2, time=5.04504
env GOTO_NUM_THREADS=4 mpirun -np 1 lu2_mpi -b 256 -n 8192 -g
での色々な部分の時間
Proc:0 lbl:1 Left bcast etc time=1.94522e+08 ops/cycle=0.167106
Proc:0 lbl:1 update time=0 ops/cycle=nan
Proc:0 lbl:1 update matmul time=2.27695e+10 ops/cycle=2.06533
Proc:0 lbl:1 update swap+bcast time=7.66965e+08 ops/cycle=0.194395
Proc:0 lbl:1 total time=2.94829e+10 ops/cycle=5.92722
Proc:0 lbl:1 rfact time=3.4178e+09 ops/cycle=0.00951074
Proc:0 lbl:1 ldmul time=2.90985e+09 ops/cycle=11.4391
Proc:0 lbl:1 colum dec with trans time=9.66295e+08 ops/cycle=0.0347588
Proc:0 lbl:1 colum dec right time=1.28045e+09 ops/cycle=3.31924
Proc:0 lbl:1 colum dec left time=1.62492e+07 ops/cycle=0.0625142
Proc:0 lbl:1 rowtocol time=1.63453e+08 ops/cycle=0.205485
Proc:0 lbl:1 column dec in trans time=6.25881e+08 ops/cycle=0.429311
Proc:0 lbl:1 coltorow time=1.76311e+08 ops/cycle=0.190499
Proc:0 lbl:1 dgemm8 time=1.69414e+08 ops/cycle=1.5845
Proc:0 lbl:1 dgemm16 time=5.95291e+07 ops/cycle=9.01863
Proc:0 lbl:1 dgemm32 time=8.91065e+07 ops/cycle=12.0501
Proc:0 lbl:1 dgemm64 time=1.71081e+08 ops/cycle=12.5525
Proc:0 lbl:1 dgemm128 time=3.00845e+08 ops/cycle=14.2763
cpsec = 44.6828 wsec=11.2728 32.5123 Gflops
n=32768 で backward_sub_blocked_mpi が無限ループ。何故かしら?
cpusec = 160.761 wsec=40.7913 71.8789 Gflops
遅くなる、、、
cpusec = 22.0247 wsec=5.54302 66.1199 Gflops
DGEMM 15 演算
8192, 512 で 4 core, Uconc, no L
cpusec = 25.996 wsec=6.5298 56.1279 Gflops
DGEMM 9 演算まで低下
することは基本的には:
MPI_Bcast(aip2,sizeof(double)*nb*nb,MPI_BYTE,
pcol, controls->row_comm);
MPI_Bcast(pvp2,sizeof(int)*nb,MPI_BYTE,
pcol, controls->row_comm);
MPI_Bcast(scalep2,sizeof(double)*nb,MPI_BYTE,
pcol, controls->row_comm);
MP_mybcast(acp2,sizeof(double)*nrows*nb, pcol, controls->row_comm);
これを、ポインタ+長さのリストにして、
わかる。放送との組合せは、レイテンシを減らすとか考えるなら allgatherv
とか使うべきだが、非同期にするなら全然そういう話ではない?
考えるべきこと:
0|-----|--------|--------|--------|-----|--------|--------|--------|
P0 U0 U1 U2 P4 U3 U4 U5
1 |-----|--------|--------|--------|--------|-----|--------|
P1 U0 U1 U2 U3 P5 U4
2 |--------|-----|--------|--------|--------|--------|-----|--------|
U0 P2 U1 U2 U3 U4 P6 U5
3 |--------|--------|-----|--------|--------|--------|--------|
U0 U1 P3 U2 U3 U4
L の通信は
起きるので、通信と計算が上手くいかないと大変。
copytomatb_tb4_dg(LDB, NOTB, b, ichip, k, DIMK, br0);
が呼ばれる。
とりあえず、lu2 で 小池 DGEMM を使うテストが必要。
testdgemm2 -m 4096 -c 1
だと
M=4096 N=2048 K=2048 ip=1.766941e-02 jp=3.520389e-02 fo=7.809485e-02 all=1.309682e-01 262.35 GFlops
for (i=0;i<bb;i++){ //BB
double * dest = brf[i];
double * src = b[k]+jstep*ichip+i*32;
for(j=0;j<32;j++){ //reg
x = jstep*ichip+i*32+j;
brf[i][j]=b[k][x];
dest[j]=src[j];
}
}
Nswap=0 cpsec = 25.6421 wsec=12.8153 228.792 Gflops
dest のほう
Nswap=0 cpsec = 25.6651 wsec=12.8031 229.009 Gflops
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls s/call s/call name
28.42 6.76 6.76 dgemm_kernel
11.88 9.59 2.83 CTRL_write
9.37 11.82 2.23 backcalcmatc
8.24 13.78 1.96 CTRL_write_nhib
5.67 15.13 1.35 hib_finish_dmawMC
5.04 16.33 1.20 backsendamat_mtwork
3.87 17.25 0.92 copytomata_em_1024_tb4_dg
3.07 17.98 0.73 send_j_matrix_mtwork
2.94 18.68 0.70 dgemm_oncopy
2.44 19.26 0.58 2061 0.00 0.00 transpose_rowtocol16_3
2.35 19.82 0.56 55415 0.00 0.00 swaprows_simple_with_scale
2.35 20.38 0.56 2 0.28 0.28 randomsetmat
2.19 20.90 0.52 copytomata_tb4_dg_onebb
1.39 21.23 0.33 CTRL_hit_headerdata2
1.26 21.53 0.30 1 0.30 0.30 showresult
1.18 21.81 0.28 hib_mem_readMC
0.97 22.04 0.23 7650 0.00 0.00 matmul_for_nk4_7
0.88 22.25 0.21 1024 0.00 0.00 solve_triangle
0.84 22.45 0.20 3753 0.00 0.00 matmul_for_nk8_5
0.76 22.63 0.18 dgemm_itcopy
0.67 22.79 0.16 1 0.16 0.16 backward_sub
0.59 22.93 0.14 gdr_dgemm_
0.55 23.06 0.13 SING_EM_send_i
0.42 23.16 0.10 7168 0.00 0.00 process_right_part
0.42 23.26 0.10 1024 0.00 0.00 solve_triangle_for_unit_mat_recursive
11/13 朝 34k
--mca btl openib,sm,self\
--mca btl_openib_use_srq 1 \
--mca mpi_leave_pinned 1 \
--mca btl_openib_ib_timeout 30 \
--mca btl_openib_flags 6 \
--mca pls_rsh_agent "/usr/bin/rsh" -hostfile ${cwd}/hostfile\
-np $*
だと
mympirun.csh 4 lu2_mpi -q 4 -n 16384
がとまらない。 -p 4, -p 2 -q 2 でも OK みたい。
Proc 2 : dgemmsum : mblk=2048 nblk=2048 K=2048 A=fe315e6860e998f6 B=80a94d954c7e0762 C=81ef36a3d8b0fd11
! Proc 0 : inputsum : A=7f0281d5fa7a3b8a B=7f2f44fa315f1459
! Proc 1 : inputsum : A=7f0281d5fa7a3b8a B=fe95e8a9188bf6fe
! Proc 2 : inputsum : A=7f0281d5fa7a3b8a B=01ecbfacf894dc92
! C sum : ff1b1dd6670e2709
! Proc 0 : dgemmsum : mblk=2048 nblk=6144 K=2048 A=7f0281d5fa7a3b8a B=7f2f44fa315f1459 C=ff1b1dd6670e2709
! C sum : 80dc9d70f5014c78
! C sum : 010437943d634c68
! Proc 1 : dgemmsum : mblk=2048 nblk=8192 K=2048 A=7f0281d5fa7a3b8a B=fe95e8a9188bf6fe C=80dc9d70f5014c78
! Proc 2 : dgemmsum : mblk=2048 nblk=8192 K=2048 A=7f0281d5fa7a3b8a B=01ecbfacf894dc92 C=010437943d634c68
--- 465,474 ----
Proc 2 : dgemmsum : mblk=2048 nblk=2048 K=2048 A=fe315e6860e998f6 B=80a94d954c7e0762 C=81ef36a3d8b0fd11
! Proc 0 : inputsum : A=1ac045fbc33122d0 B=7f2f44fa315f1459
! Proc 1 : inputsum : A=1ac045fbc33122d0 B=fe95e8a9188bf6fe
! Proc 2 : inputsum : A=1ac045fbc33122d0 B=81e9ab360c7cd2c7
! C sum : ffea20be661e2859
! Proc 0 : dgemmsum : mblk=2048 nblk=6144 K=2048 A=1ac045fbc33122d0 B=7f2f44fa315f1459 C=ffea20be661e2859
! C sum : 009567b26f4d2c83
! C sum : 81dc47a532453cee
! Proc 1 : dgemmsum : mblk=2048 nblk=8192 K=2048 A=1ac045fbc33122d0 B=fe95e8a9188bf6fe C=009567b26f4d2c83
! Proc 2 : dgemmsum : mblk=2048 nblk=8192 K=2048 A=1ac045fbc33122d0 B=81e9ab360c7cd2c7 C=81dc47a532453cee
がでているので遅い。
mpi:
A->j B->i NOTI=0 NOTJ=0 LDA=2064 LDB=2048 LDC=4112
gdrflag=1
M=6144 N=2048 K=2048 ip=4.573532e-02 jp=7.018384e-02 fo=1.570929e-01 all=2.730121e-01 188.78 GFlops
mympirun.csh 1 "01 02" lu2_mpi_gdr -q 1 -n 8192 -g > & log
の結果から:
必要あり。
gdr_dgemm_(¬a, ¬b, &n, &m, &k, &alpha, &beta, &nb, &na, &nc,
b, a, c, &gdrdoneflag);
nota=1, notb=1;
mygdrdgemm(m, n, k, alpha, a, na, b, nb, beta, c, nc);
mydgemm(nrow-startrow, c2-c1, nbin, -1.0, &(acol[0][0]), nbin,
&(arow[0][0]), c2-c1, 1.0, &(a[startrow][c1]), nncol );
acol: B, arow:A
SING_EM_sendMC(s, emid1,index_in_EM,count,ip);
を、チップ、データの配列をもらうようにする必要あり。
SING_EM_sendMC_singlethread(s, emid1,index_in_EM,count,ip);
とする。s, emid はどうせポインタなので問題ないはず。
しかし、なんかネストが無意味に深いよね、、、
一応動くようになった。 192語毎の切換えでも 1.1GB/s もでるのは何故だ?
Error = 1.270799e-10
Proc:0 lbl:1 Left bcast etc time=0 ops/cycle=nan
Proc:0 lbl:1 update time=0 ops/cycle=nan
Proc:0 lbl:1 update matmul time=1.53501e+09 ops/cycle=78.3441
Proc:0 lbl:1 update swap+bcast time=6.58467e+07 ops/cycle=0.254792
Proc:0 lbl:1 total time=9.99297e+09 ops/cycle=12.0344
Proc:0 lbl:1 rfact time=6.55067e+09 ops/cycle=0.00384172
Proc:0 lbl:1 ldmul time=2.14579e+09 ops/cycle=96.0758
Proc:0 lbl:1 colum dec with trans time=9.47019e+08 ops/cycle=0.0354662
Proc:0 lbl:1 colum dec right time=5.13081e+09 ops/cycle=7.7867
Proc:0 lbl:1 colum dec left time=9.24529e+07 ops/cycle=0.0903794
Proc:0 lbl:1 rowtocol time=1.69955e+08 ops/cycle=0.197624
Proc:0 lbl:1 column dec in trans time=6.77899e+08 ops/cycle=0.396368
Proc:0 lbl:1 coltorow time=9.77612e+07 ops/cycle=0.343564
Proc:0 lbl:1 dgemm8 time=6.71367e+07 ops/cycle=3.99834
Proc:0 lbl:1 dgemm16 time=2.44274e+09 ops/cycle=0.219782
Proc:0 lbl:1 dgemm32 time=1.44083e+09 ops/cycle=0.745226
Proc:0 lbl:1 dgemm64 time=1.65342e+08 ops/cycle=12.9881
Proc:0 lbl:1 dgemm128 time=1.55439e+09 ops/cycle=2.76312
Proc:0 lbl:1 main dgemm time=2.57346e+09 ops/cycle=93.7739
Error = 1.871036e-09
Error = 1.871036e-09
Proc:0 lbl:1 Left bcast etc time=0 ops/cycle=nan
Proc:0 lbl:1 update time=0 ops/cycle=nan
Proc:0 lbl:1 update matmul time=1.76187e+11 ops/cycle=202.674
Proc:0 lbl:1 update swap+bcast time=1.02691e+11 ops/cycle=0.150795
Proc:0 lbl:1 total time=3.97652e+11 ops/cycle=184.802
Proc:0 lbl:1 rfact time=9.98087e+10 ops/cycle=0.0182802
Proc:0 lbl:1 ldmul time=6.74015e+10 ops/cycle=107.053
Proc:0 lbl:1 colum dec with trans time=1.79654e+10 ops/cycle=0.00175783
Proc:0 lbl:1 colum dec right time=5.60626e+10 ops/cycle=0.955377
Proc:0 lbl:1 colum dec left time=3.848e+09 ops/cycle=0.00814304
Proc:0 lbl:1 rowtocol time=4.00115e+09 ops/cycle=0.117962
Proc:0 lbl:1 column dec in trans time=1.30404e+10 ops/cycle=0.28955
Proc:0 lbl:1 coltorow time=9.16765e+08 ops/cycle=0.514834
Proc:0 lbl:1 dgemm8 time=8.54889e+08 ops/cycle=4.41563
Proc:0 lbl:1 dgemm16 time=1.04965e+09 ops/cycle=7.19263
Proc:0 lbl:1 dgemm32 time=1.40659e+09 ops/cycle=10.7348
Proc:0 lbl:1 dgemm64 time=2.32178e+09 ops/cycle=13.0068
Proc:0 lbl:1 dgemm128 time=4.19791e+09 ops/cycle=14.3876
Proc:0 lbl:1 main dgemm time=1.9219e+11 ops/cycle=181.609
Proc:1 lbl:1 Left bcast etc time=0 ops/cycle=nan
Proc:2 lbl:9 esum = 1.755998e-18
Proc:2 lbl:0
Error = 1.871036e-09
Error = 1.871036e-09
Proc:1 lbl:1 update time=0 ops/cycle=nan
Proc:1 lbl:1 update matmul time=1.84718e+11 ops/cycle=193.313
Proc:1 lbl:1 update swap+bcast time=7.76725e+10 ops/cycle=0.199367
Proc:1 lbl:1 total time=3.97523e+11 ops/cycle=184.862
Proc:1 lbl:1 rfact time=9.12246e+10 ops/cycle=0.0200003
Proc:1 lbl:1 ldmul time=7.18913e+10 ops/cycle=107.537
Proc:1 lbl:1 colum dec with trans time=1.59105e+10 ops/cycle=0.00198486
Proc:1 lbl:1 colum dec right time=5.81624e+10 ops/cycle=0.920886
Proc:1 lbl:1 colum dec left time=3.84236e+09 ops/cycle=0.00815499
Proc:1 lbl:1 rowtocol time=4.32079e+09 ops/cycle=0.116487
Proc:1 lbl:1 column dec in trans time=1.06419e+10 ops/cycle=0.378365
Proc:1 lbl:1 coltorow time=9.39883e+08 ops/cycle=0.53551
Proc:1 lbl:1 dgemm8 time=9.37491e+08 ops/cycle=4.29501
Proc:1 lbl:1 dgemm16 time=1.12445e+09 ops/cycle=7.16179
Proc:1 lbl:1 dgemm32 time=1.50646e+09 ops/cycle=10.6914
Proc:1 lbl:1 dgemm64 time=2.4788e+09 ops/cycle=12.9951
Proc:1 lbl:1 dgemm128 time=4.48718e+09 ops/cycle=14.3575
Proc:1 lbl:1 main dgemm time=2.00682e+11 ops/cycle=182.923
Proc:2 lbl:1 Left bcast etc time=0 ops/cycle=nan
Proc:2 lbl:1 update time=0 ops/cycle=nan
Proc:2 lbl:1 update matmul time=1.88132e+11 ops/cycle=199.895
Proc:2 lbl:1 update swap+bcast time=1.04577e+11 ops/cycle=0.156941
Proc:2 lbl:1 total time=3.97564e+11 ops/cycle=184.843
Proc:2 lbl:1 rfact time=1.01214e+11 ops/cycle=0.0180265
Proc:2 lbl:1 ldmul time=7.11865e+10 ops/cycle=101.361
Proc:3 lbl:1 Left bcast etc time=0 ops/cycle=nan
Proc:2 lbl:1 colum dec with trans time=1.89448e+10 ops/cycle=-0.00165399
Proc:2 lbl:1 colum dec right time=5.39382e+10 ops/cycle=-0.196742
Proc:2 lbl:1 colum dec left time=3.27096e+09 ops/cycle=0.00957957
Proc:2 lbl:1 rowtocol time=4.12593e+09 ops/cycle=0.10674
Proc:2 lbl:1 column dec in trans time=1.38673e+10 ops/cycle=0.254067
Proc:2 lbl:1 coltorow time=9.42718e+08 ops/cycle=0.467162
Proc:2 lbl:1 dgemm8 time=8.96048e+08 ops/cycle=3.93195
Proc:2 lbl:1 dgemm16 time=1.06958e+09 ops/cycle=6.58801
Proc:2 lbl:1 dgemm32 time=1.36889e+09 ops/cycle=10.2951
Proc:2 lbl:1 dgemm64 time=2.2075e+09 ops/cycle=12.7682
Proc:2 lbl:1 dgemm128 time=3.96529e+09 ops/cycle=14.2162
Proc:2 lbl:1 main dgemm time=2.0502e+11 ops/cycle=179.043
cpusec = 222.532 wsec=157.125 984.049 Gflops
Proc:3 lbl:1 update time=0 ops/cycle=nan
Proc:3 lbl:1 update matmul time=1.93667e+11 ops/cycle=194.182
Proc:3 lbl:1 update swap+bcast time=9.34264e+10 ops/cycle=0.175671
Proc:3 lbl:1 total time=3.97559e+11 ops/cycle=184.845
Proc:3 lbl:1 rfact time=1.07533e+11 ops/cycle=0.0169671
Proc:3 lbl:1 ldmul time=7.25826e+10 ops/cycle=106.512
Proc:3 lbl:1 colum dec with trans time=1.50262e+10 ops/cycle=-0.00208532
Proc:3 lbl:1 colum dec right time=5.56059e+10 ops/cycle=-0.190841
Proc:3 lbl:1 colum dec left time=3.30611e+09 ops/cycle=0.00947773
Proc:3 lbl:1 rowtocol time=2.89797e+09 ops/cycle=0.162866
Proc:3 lbl:1 column dec in trans time=1.12103e+10 ops/cycle=0.336821
Proc:3 lbl:1 coltorow time=9.10499e+08 ops/cycle=0.518378
Proc:3 lbl:1 dgemm8 time=8.51049e+08 ops/cycle=4.43556
Proc:3 lbl:1 dgemm16 time=1.04562e+09 ops/cycle=7.22033
Proc:3 lbl:1 dgemm32 time=1.40422e+09 ops/cycle=10.7529
Proc:3 lbl:1 dgemm64 time=2.31895e+09 ops/cycle=13.0227
Proc:3 lbl:1 dgemm128 time=4.18789e+09 ops/cycle=14.422
Proc:3 lbl:1 main dgemm time=2.12784e+11 ops/cycle=182.207
Error = 2.987479e-10
Proc:0 lbl:1 Left bcast etc time=0 ops/cycle=nan
Proc:0 lbl:1 update time=0 ops/cycle=nan
Proc:0 lbl:1 update matmul time=8.38006e+10 ops/cycle=102.915
Proc:0 lbl:1 update swap+bcast time=5.91174e+09 ops/cycle=0.627186
Proc:0 lbl:1 total time=1.99905e+11 ops/cycle=43.6147
Proc:0 lbl:1 rfact time=8.17903e+10 ops/cycle=0.00538453
Proc:0 lbl:1 ldmul time=3.34995e+10 ops/cycle=107.696
Proc:0 lbl:1 colum dec with trans time=1.39766e+10 ops/cycle=0.0337695
Proc:0 lbl:1 colum dec right time=5.15968e+10 ops/cycle=9.74423
Proc:0 lbl:1 colum dec left time=3.65253e+08 ops/cycle=0.0857881
Proc:0 lbl:1 rowtocol time=3.97661e+09 ops/cycle=0.118689
Proc:0 lbl:1 column dec in trans time=9.09202e+09 ops/cycle=0.415293
Proc:0 lbl:1 coltorow time=9.0091e+08 ops/cycle=0.523895
Proc:0 lbl:1 dgemm8 time=8.54582e+08 ops/cycle=4.41722
Proc:0 lbl:1 dgemm16 time=1.045e+09 ops/cycle=7.22464
Proc:0 lbl:1 dgemm32 time=1.40459e+09 ops/cycle=10.7501
Proc:0 lbl:1 dgemm64 time=2.31815e+09 ops/cycle=13.0272
Proc:0 lbl:1 dgemm128 time=4.18658e+09 ops/cycle=14.4266
Proc:0 lbl:1 main dgemm time=1.00405e+11 ops/cycle=173.813
cpusec = 116.597 wsec=80.5781 239.859 Gflops
non-overlapping:
mt send_j
cpusec = 30.8033 wsec=20.0437 146.282 Gflops
s=64:
cpusec = 31.4312 wsec=20.7621 141.221 Gflops
まだ non-uc のほうが速いのはなぜ?
cpusec = 220.398 wsec=155.674 993.224 Gflops
計算の後のほうでも大きな行列がでてくるのはなんか間違ってるような、、、、
process_right_part_mpi_using_dls_concurrent acol
process_right_part_mpi_using_dls_phase2 acol
update_using_lu : acol[0][0], nrow-startrow
ld_phase2: copy is done starting at 0,0
cpusec = 200.72 wsec=142.995 1081.29 Gflops
1ノード、N=30720 で
cpusec = 106.218 wsec=73.6948 262.262 Gflops
lu2_gdr では
cpusec = 52.839 wsec=44.0207 532.846 Gflops
ovl
cpusec = 52.2691 wsec=39.2617 597.434 Gflops
8ノード
mympirun.csh 8 "02 06 07 08 09 10 11 12 " lu2_mpi_gdr -g -p 2 -q 4 -n 65536
cpusec = 183.763 wsec=140.427 1336.28 Gflops
p=4 q=2 だと
cpusec = 163.009 wsec=127.708 1469.36 Gflops
72k, p=2, q=4
cpusec = 235.452 wsec=175.633 1521.24 Gflops
80k
cpusec = 293.711 wsec=214.02 1712.47 Gflops
mympirun.csh 8 "02 06 07 08 09 10 11 12 " lu2_mpi_gdr -g -p 4 -q 2 -n 40960
no uc
cpusec = 65.2281 wsec=55.3511 827.68 Gflops
uc
cpusec = 66.5289 wsec=55.0273 832.551 Gflops
q=2 だとあまり差がでない?
6.5k: 0.0417 sec
大きい DGEMM (K>=2048, N が大きい)は 1.32秒のうち
0.35秒。あと1秒はそれ以外
cpusec = 105.501 wsec=72.7675 265.604 Gflops
lu2_gdr N=30K
Error = 3.139189e-10
Proc:0 lbl:1 Left bcast etc time=0 ops/cycle=nan
Proc:0 lbl:1 update time=0 ops/cycle=nan
Proc:0 lbl:1 update matmul time=8.3126e+10 ops/cycle=103.75
Proc:0 lbl:1 update swap+bcast time=6.01633e+09 ops/cycle=0.616284
Proc:0 lbl:1 total time=1.76692e+11 ops/cycle=49.3444
Proc:0 lbl:1 rfact time=7.5382e+10 ops/cycle=0.00584227
Proc:0 lbl:1 ldmul time=1.73609e+10 ops/cycle=103.905
Proc:0 lbl:1 colum dec with trans time=1.11029e+10 ops/cycle=0.0425099
Proc:0 lbl:1 colum dec right time=4.93324e+10 ops/cycle=10.1915
Proc:0 lbl:1 colum dec left time=3.66624e+08 ops/cycle=0.0854674
Proc:0 lbl:1 rowtocol time=1.09738e+09 ops/cycle=0.430098
Proc:0 lbl:1 column dec in trans time=9.18104e+09 ops/cycle=0.411267
Proc:0 lbl:1 coltorow time=8.16705e+08 ops/cycle=0.57791
Proc:0 lbl:1 dgemm8 time=8.66406e+08 ops/cycle=4.35693
Proc:0 lbl:1 dgemm16 time=1.04083e+09 ops/cycle=7.25361
Proc:0 lbl:1 dgemm32 time=1.40448e+09 ops/cycle=10.7509
Proc:0 lbl:1 dgemm64 time=2.32689e+09 ops/cycle=12.9782
Proc:0 lbl:1 dgemm128 time=4.18009e+09 ops/cycle=14.449
Proc:0 lbl:1 main dgemm time=9.84777e+10 ops/cycle=177.214
cpusec = 105.017 wsec=71.6706 269.669 Gflops
Proc:0 lbl:1 rowtocol time=1.09738e+09 ops/cycle=0.430098
くらいかな。320くらいはいくはずだし。
for (i=c1;i<c2;i++){
double * ap = a[i]+startrow;
double * v = acol;
double s = arow[i-c1];
for (j=0;j<nrow-startrow;j++){
ap[j] -= v[j]*s;
}
}
をもう2倍くらい速くしたい?
Error = 3.139189e-10
Proc:0 lbl:1 Left bcast etc time=0 ops/cycle=nan
Proc:0 lbl:1 update time=0 ops/cycle=nan
Proc:0 lbl:1 update matmul time=8.3117e+10 ops/cycle=103.761
Proc:0 lbl:1 update swap+bcast time=6.02712e+09 ops/cycle=0.61518
Proc:0 lbl:1 total time=1.73101e+11 ops/cycle=50.3683
Proc:0 lbl:1 rfact time=7.17912e+10 ops/cycle=0.00613448
Proc:0 lbl:1 ldmul time=1.73685e+10 ops/cycle=103.859
Proc:0 lbl:1 colum dec with trans time=6.85998e+09 ops/cycle=0.0688022
Proc:0 lbl:1 colum dec right time=4.93619e+10 ops/cycle=10.1854
Proc:0 lbl:1 colum dec left time=3.64584e+08 ops/cycle=0.0859456
Proc:0 lbl:1 rowtocol time=1.06277e+09 ops/cycle=0.444104
Proc:0 lbl:1 column dec in trans time=4.98312e+09 ops/cycle=0.75773
Proc:0 lbl:1 coltorow time=8.06925e+08 ops/cycle=0.584915
Proc:0 lbl:1 dgemm8 time=8.71908e+08 ops/cycle=4.32944
Proc:0 lbl:1 dgemm16 time=1.04728e+09 ops/cycle=7.20891
Proc:0 lbl:1 dgemm32 time=1.40578e+09 ops/cycle=10.741
Proc:0 lbl:1 dgemm64 time=2.31943e+09 ops/cycle=13.02
Proc:0 lbl:1 dgemm128 time=4.18066e+09 ops/cycle=14.447
Proc:0 lbl:1 main dgemm time=9.84973e+10 ops/cycle=177.179
cpusec = 103.843 wsec=70.1169 275.645 Gflops
Proc:0 lbl:1 column dec in trans time=9.18104e+09 ops/cycle=0.411267
Proc:0 lbl:1 column dec in trans time=4.98312e+09 ops/cycle=0.75773
Error = 3.139189e-10
Proc:0 lbl:1 Left bcast etc time=0 ops/cycle=nan
Proc:0 lbl:1 update time=0 ops/cycle=nan
Proc:0 lbl:1 update matmul time=7.46473e+10 ops/cycle=115.534
Error = 3.139189e-10
Proc:0 lbl:1 update swap+bcast time=4.87332e+09 ops/cycle=0.760829
Proc:0 lbl:1 total time=1.69688e+11 ops/cycle=51.3814
Proc:0 lbl:1 rfact time=7.20917e+10 ops/cycle=0.00610891
Proc:0 lbl:1 ldmul time=1.72753e+10 ops/cycle=104.42
Proc:0 lbl:1 colum dec with trans time=7.35331e+09 ops/cycle=0.0641864
Proc:0 lbl:1 colum dec right time=4.92662e+10 ops/cycle=10.2052
Proc:0 lbl:1 colum dec left time=3.65789e+08 ops/cycle=0.0856624
Proc:0 lbl:1 rowtocol time=1.52696e+09 ops/cycle=0.3091
Proc:0 lbl:1 column dec in trans time=5.02414e+09 ops/cycle=0.751542
Proc:0 lbl:1 coltorow time=7.93755e+08 ops/cycle=0.594619
cpusec = 104.464 wsec=68.8385 280.764 Gflops
Proc:0 lbl:1 dgemm8 time=8.70708e+08 ops/cycle=4.33541
Proc:0 lbl:1 dgemm16 time=1.04622e+09 ops/cycle=7.21623
Proc:0 lbl:1 dgemm32 time=1.40587e+09 ops/cycle=10.7404
Proc:0 lbl:1 dgemm64 time=2.31857e+09 ops/cycle=13.0248
Proc:0 lbl:1 dgemm128 time=4.18907e+09 ops/cycle=14.418
Proc:0 lbl:1 main dgemm time=8.99833e+10 ops/cycle=193.943
15.1. 2009/12/8
Error = 3.139189e-10
Proc:0 lbl:1 update swap+bcast time=6.01316e+09 ops/cycle=0.616608
Proc:0 lbl:1 total time=1.72798e+11 ops/cycle=50.4564
Proc:0 lbl:1 rfact time=7.15661e+10 ops/cycle=0.00615378
Proc:0 lbl:1 ldmul time=1.73251e+10 ops/cycle=104.12
Proc:0 lbl:1 colum dec with trans time=6.91975e+09 ops/cycle=0.068208
Proc:0 lbl:1 colum dec right time=4.88854e+10 ops/cycle=10.2847
Proc:0 lbl:1 colum dec left time=3.65462e+08 ops/cycle=0.0857391
Proc:0 lbl:1 rowtocol time=1.14127e+09 ops/cycle=0.413557
Proc:0 lbl:1 column dec in trans time=4.96614e+09 ops/cycle=0.760321
Proc:0 lbl:1 coltorow time=8.05183e+08 ops/cycle=0.58618
Proc:0 lbl:1 dgemm8 time=8.70303e+08 ops/cycle=4.33742
cpusec = 104.104 wsec=69.9809 276.18 Gflops
Proc:0 lbl:1 dgemm16 time=1.04253e+09 ops/cycle=7.24176
Proc:0 lbl:1 dgemm32 time=1.40723e+09 ops/cycle=10.73
Proc:0 lbl:1 dgemm64 time=2.32012e+09 ops/cycle=13.0161
Proc:0 lbl:1 dgemm128 time=4.19139e+09 ops/cycle=14.41
Proc:0 lbl:1 main dgemm time=9.85897e+10 ops/cycle=177.013
Proc:0 lbl:1 col trsm time=2.10595e+09 ops/cycle=20.3941
Proc:0 lbl:1 col update time=4.64853e+10 ops/cycle=0.923928
Proc:0 lbl:1 col rest dgemm time=2.24337e+10 ops/cycle=37.6921
Proc:0 lbl:1 col right misc time=1.21094e+10 ops/cycle=0.155865
MP_update_multiple_blocked_global_withacol
の中での行列コピーに時間かかっている。行列コピー専用のルーチンをかいて
おこう。
cpusec = 7.28689 wsec=4.16787 87.9355 Gflops
普通の代入
cpusec = 7.31889 wsec=4.16111 88.0785 Gflops
prefetch 消す
cpusec = 7.15991 wsec=4.10502 89.2818 Gflops
no openmp
cpusec = 7.00094 wsec=4.19179 87.4337 Gflops
10000 で切換え
cpusec = 7.2049 wsec=4.11675 89.0276 Gflops
Error = 3.139189e-10
Proc:0 lbl:1 Left bcast etc time=0 ops/cycle=nan
Proc:0 lbl:1 update time=0 ops/cycle=nan
Proc:0 lbl:1 update matmul time=8.31055e+10 ops/cycle=103.775
Proc:0 lbl:1 update swap+bcast time=5.99012e+09 ops/cycle=0.61898
Proc:0 lbl:1 total time=1.67465e+11 ops/cycle=52.0633
Proc:0 lbl:1 rfact time=6.61979e+10 ops/cycle=0.0066528
Proc:0 lbl:1 ldmul time=1.73381e+10 ops/cycle=104.042
Proc:0 lbl:1 colum dec with trans time=7.33448e+09 ops/cycle=0.0643511
Proc:0 lbl:1 colum dec right time=4.23121e+10 ops/cycle=11.8824
Proc:0 lbl:1 colum dec left time=3.68855e+08 ops/cycle=0.0849504
Proc:0 lbl:1 rowtocol time=1.50158e+09 ops/cycle=0.314323
Proc:0 lbl:1 column dec in trans time=5.01504e+09 ops/cycle=0.752907
Proc:0 lbl:1 coltorow time=8.09911e+08 ops/cycle=0.582758
Proc:0 lbl:1 dgemm8 time=9.78884e+08 ops/cycle=3.8563
Proc:0 lbl:1 dgemm16 time=1.05453e+09 ops/cycle=7.15935
Proc:0 lbl:1 dgemm32 time=1.40196e+09 ops/cycle=10.7703
Proc:0 lbl:1 dgemm64 time=2.31722e+09 ops/cycle=13.0324
Proc:0 lbl:1 dgemm128 time=4.19635e+09 ops/cycle=14.393
Proc:0 lbl:1 main dgemm time=9.84414e+10 ops/cycle=177.28
Proc:0 lbl:1 col trsm time=2.07046e+09 ops/cycle=20.7437
Proc:0 lbl:1 col update time=3.98918e+10 ops/cycle=1.07664
Proc:0 lbl:1 col rest dgemm time=2.22898e+10 ops/cycle=37.9354
Proc:0 lbl:1 col right misc time=5.57868e+09 ops/cycle=0.33833
cpusec = 106.44 wsec=67.6376 285.749 Gflops
uconn: N=8k
Error = 1.289304e-10
Proc:0 lbl:1 Left bcast etc time=0 ops/cycle=nan
Proc:0 lbl:1 update time=1.63224e+09 ops/cycle=210.507
Proc:0 lbl:1 update matmul time=1.50266e+09 ops/cycle=160.061
Proc:0 lbl:1 update swap+bcast time=8.63137e+07 ops/cycle=0.194375
Error = 1.289304e-10
Proc:0 lbl:1 Left bcast etc time=0 ops/cycle=nan
Proc:0 lbl:1 update time=1.341e+09 ops/cycle=256.225
Proc:0 lbl:1 update matmul time=1.14468e+09 ops/cycle=210.118
Proc:0 lbl:1 update swap+bcast time=6.7019e+07 ops/cycle=0.250335
Error = 3.139189e-10
Proc:0 lbl:1 Left bcast etc time=0 ops/cycle=nan
Proc:0 lbl:1 update time=8.0307e+10 ops/cycle=239.599
Proc:0 lbl:1 update matmul time=7.46056e+10 ops/cycle=231.197
Proc:0 lbl:1 update swap+bcast time=4.86675e+09 ops/cycle=0.761857
Proc:0 lbl:1 total time=1.63865e+11 ops/cycle=53.207
Proc:0 lbl:1 rfact time=6.62659e+10 ops/cycle=0.00664599
Proc:0 lbl:1 ldmul time=1.73185e+10 ops/cycle=104.16
Proc:0 lbl:1 colum dec with trans time=7.38614e+09 ops/cycle=0.0639011
Proc:0 lbl:1 colum dec right time=4.23328e+10 ops/cycle=11.8766
Proc:0 lbl:1 colum dec left time=3.68322e+08 ops/cycle=0.0850734
Proc:0 lbl:1 rowtocol time=1.54664e+09 ops/cycle=0.305165
Proc:0 lbl:1 column dec in trans time=5.02752e+09 ops/cycle=0.751037
Proc:0 lbl:1 coltorow time=8.03131e+08 ops/cycle=0.587678
Proc:0 lbl:1 dgemm8 time=9.84585e+08 ops/cycle=3.83397
Proc:0 lbl:1 dgemm16 time=1.05458e+09 ops/cycle=7.15902
Proc:0 lbl:1 dgemm32 time=1.39973e+09 ops/cycle=10.7874
Proc:0 lbl:1 dgemm64 time=2.31708e+09 ops/cycle=13.0332
Proc:0 lbl:1 dgemm128 time=4.1934e+09 ops/cycle=14.4031
Proc:0 lbl:1 main dgemm time=8.99652e+10 ops/cycle=193.982
Proc:0 lbl:1 col trsm time=2.0639e+09 ops/cycle=20.8096
Proc:0 lbl:1 col update time=3.99125e+10 ops/cycle=1.07608
Proc:0 lbl:1 col rest dgemm time=2.23033e+10 ops/cycle=37.9125
Proc:0 lbl:1 col right misc time=5.59245e+09 ops/cycle=0.337497
Error = 3.139189e-10
Proc:0 lbl:1 update time= 8.39176e+10 ops/cycle= 229.29
Proc:0 lbl:1 update matmul time= 8.30989e+10 ops/cycle= 207.567
Proc:0 lbl:1 update swap+bcast time= 5.98931e+09 ops/cycle= 0.619064
Proc:0 lbl:1 total time= 1.73989e+11 ops/cycle= 111.084
Proc:0 lbl:1 rfact time= 7.26784e+10 ops/cycle= 0.00686754
Proc:0 lbl:1 ldmul time= 1.74294e+10 ops/cycle= 103.497
Proc:0 lbl:1 colum dec with trans time= 6.85832e+09 ops/cycle= 0.0688189
Proc:0 lbl:1 colum dec right time= 4.23977e+10 ops/cycle= 11.8584
Proc:0 lbl:1 colum dec left time= 3.68511e+08 ops/cycle= 0.0850297
Proc:0 lbl:1 rowtocol time= 1.06496e+09 ops/cycle= 0.443192
Proc:0 lbl:1 column dec in trans time= 4.96938e+09 ops/cycle= 0.759825
Proc:0 lbl:1 coltorow time= 8.17004e+08 ops/cycle= 0.577699
Proc:0 lbl:1 dgemm8 time= 9.78743e+08 ops/cycle= 3.85686
Proc:0 lbl:1 dgemm16 time= 1.05854e+09 ops/cycle= 7.13221
Proc:0 lbl:1 dgemm32 time= 1.40412e+09 ops/cycle= 10.7537
Proc:0 lbl:1 dgemm64 time= 2.31797e+09 ops/cycle= 13.0282
Proc:0 lbl:1 dgemm128 time= 4.18176e+09 ops/cycle= 14.4432
Proc:0 lbl:1 main dgemm time= 9.84209e+10 ops/cycle= 177.317
Proc:0 lbl:1 col trsm time= 2.07138e+09 ops/cycle= 20.7345
Proc:0 lbl:1 col update time= 3.99737e+10 ops/cycle= 1.07443
Proc:0 lbl:1 col r dgemm time= 3.23213e+10 ops/cycle= 29.782
Proc:0 lbl:1 col right misc time= 5.5764e+09 ops/cycle= 0.338469
Proc:0 lbl:1 backsub time= 4.23506e+09 ops/cycle= 0.222835
Proc:0 lbl:1 col dec total time= 4.96304e+10 ops/cycle= 0.0100568
cpusec = 105.675 wsec=66.6827 289.841 Gflops
Proc:0 lbl:1 rfact time= 7.26784e+10 ops/cycle= 0.00686754
Proc:0 lbl:1 col dec total time= 4.96304e+10 ops/cycle= 0.0100568
Proc:0 lbl:1 colum dec with trans time= 6.85832e+09 ops/cycle= 0.0688189
Proc:0 lbl:1 colum dec right time= 4.23977e+10 ops/cycle= 11.8584
Proc:0 lbl:1 col r dgemm time= 3.23213e+10 ops/cycle= 29.782
Proc:0 lbl:1 col right misc time= 5.5764e+09 ops/cycle= 0.338469
Proc:0 lbl:1 colum dec left time= 3.68511e+08 ops/cycle= 0.0850297
9 nodes, 84k
cpusec = 266.826 wsec=181.633 2335.88 Gflops
60k
cpusec = 363.821 wsec=242.418 2612.5 Gflops
Proc:8 lbl:1 update matmul time= 3.66155e+11 ops/cycle= 576.689
Proc:8 lbl:1 update swap+bcast time= 2.6402e+11 ops/cycle= 0.176576
Proc:8 lbl:1 total time= 6.31871e+11 ops/cycle= 1002.29
Proc:8 lbl:1 rfact time= 1.25575e+11 ops/cycle= 0.0392458
Proc:8 lbl:1 ldmul time= 6.79007e+10 ops/cycle= 99.1818
cpusec = 363.821 wsec=242.418 2612.5 Gflops
Proc:8 lbl:1 colum dec with trans time= 1.13248e+10 ops/cycle= -0.0533207
Proc:8 lbl:1 colum dec right time= 5.71651e+10 ops/cycle= -10.3761
Proc:8 lbl:1 colum dec left time= 5.43323e+09 ops/cycle= 0.00615166
Proc:8 lbl:1 rowtocol time= 2.61998e+09 ops/cycle= 0.204964
Proc:8 lbl:1 column dec in trans time= 7.61579e+09 ops/cycle= 0.564093
Proc:8 lbl:1 coltorow time= 1.07943e+09 ops/cycle= 0.497487
Proc:8 lbl:1 dgemm8 time= 1.30787e+09 ops/cycle= 3.28394
Proc:8 lbl:1 dgemm16 time= 1.39091e+09 ops/cycle= 6.17575
Proc:8 lbl:1 dgemm32 time= 1.69159e+09 ops/cycle= 10.1561
Proc:8 lbl:1 dgemm64 time= 2.69338e+09 ops/cycle= 12.7571
Proc:8 lbl:1 dgemm128 time= 4.80411e+09 ops/cycle= 14.3043
Proc:8 lbl:1 main dgemm time= 3.86831e+11 ops/cycle= 188.087
Proc:8 lbl:1 col trsm time= 2.37195e+09 ops/cycle= 19.3142
Proc:8 lbl:1 col update time= 4.95476e+10 ops/cycle= 0.924611
Proc:8 lbl:1 col r dgemm time= 3.74598e+10 ops/cycle= 29.2371
Proc:8 lbl:1 col right misc time= 9.70964e+09 ops/cycle= 0.22117
Proc:8 lbl:1 backsub time= 1.60446e+10 ops/cycle= 0.602301
Proc:8 lbl:1 col dec total time= 7.39313e+10 ops/cycle= 0.0239978
cpusec = 233.513 wsec=156.942 1195.66 Gflops
Proc:3 lbl:1 update time= 2.48942e+11 ops/cycle= 753.053
Proc:3 lbl:1 update matmul time= 2.30239e+11 ops/cycle= 397.19
Proc:3 lbl:1 update swap+bcast time= 1.07307e+11 ops/cycle= 0.187422
Proc:3 lbl:1 total time= 4.09016e+11 ops/cycle= 458.784
Proc:3 lbl:1 rfact time= 1.10388e+11 ops/cycle= 0.0200239
Proc:3 lbl:1 ldmul time= 4.28469e+10 ops/cycle= 102.646
Proc:3 lbl:1 colum dec with trans time= 1.02054e+10 ops/cycle= -0.00327505
Proc:3 lbl:1 colum dec right time= 5.25233e+10 ops/cycle= -0.215511
Proc:3 lbl:1 colum dec left time= 3.55824e+09 ops/cycle= 0.00939323
Proc:3 lbl:1 rowtocol time= 2.07053e+09 ops/cycle= 0.259355
Proc:3 lbl:1 column dec in trans time= 7.1354e+09 ops/cycle= 0.602071
Proc:3 lbl:1 coltorow time= 9.90327e+08 ops/cycle= 0.542247
Proc:3 lbl:1 dgemm8 time= 1.14655e+09 ops/cycle= 3.746
Proc:3 lbl:1 dgemm16 time= 1.23691e+09 ops/cycle= 6.94467
Proc:3 lbl:1 dgemm32 time= 1.61343e+09 ops/cycle= 10.648
Proc:3 lbl:1 dgemm64 time= 2.64012e+09 ops/cycle= 13.0145
Proc:3 lbl:1 dgemm128 time= 4.76217e+09 ops/cycle= 14.4303
Proc:3 lbl:1 main dgemm time= 2.49996e+11 ops/cycle= 188.157
Proc:3 lbl:1 col trsm time= 2.259e+09 ops/cycle= 20.2799
Proc:3 lbl:1 col update time= 4.68649e+10 ops/cycle= 0.977539
Proc:3 lbl:1 col r dgemm time= 3.69471e+10 ops/cycle= 29.6428
Proc:3 lbl:1 col right misc time= 7.65281e+09 ops/cycle= 0.280614
Proc:3 lbl:1 backsub time= 1.04504e+10 ops/cycle= 0.410986
Proc:3 lbl:1 col dec total time= 6.62941e+10 ops/cycle= 0.0181579
Error = 2.954316e-10
Error = 2.954316e-10
Proc:0 lbl:1 update time= 1.01405e+11 ops/cycle= 230.408
Proc:0 lbl:1 update matmul time= 1.00502e+11 ops/cycle= 209.914
Proc:0 lbl:1 update swap+bcast time= 6.99869e+09 ops/cycle= 0.654434
Proc:0 lbl:1 total time= 2.04656e+11 ops/cycle= 114.613
Proc:0 lbl:1 rfact time= 8.32635e+10 ops/cycle= 0.00680047
Proc:0 lbl:1 ldmul time= 1.98856e+10 ops/cycle= 103.672
Proc:0 lbl:1 colum dec with trans time= 8.66771e+09 ops/cycle= 0.0619543
Proc:0 lbl:1 colum dec right time= 4.83385e+10 ops/cycle= 11.8025
Proc:0 lbl:1 colum dec left time= 3.92447e+08 ops/cycle= 0.0851666
Proc:0 lbl:1 rowtocol time= 2.0383e+09 ops/cycle= 0.263456
Proc:0 lbl:1 column dec in trans time= 5.61797e+09 ops/cycle= 0.764691
Proc:0 lbl:1 coltorow time= 1.00305e+09 ops/cycle= 0.535368
Proc:0 lbl:1 dgemm8 time= 1.1376e+09 ops/cycle= 3.77545
Proc:0 lbl:1 dgemm16 time= 1.23679e+09 ops/cycle= 6.94537
Proc:0 lbl:1 dgemm32 time= 1.61608e+09 ops/cycle= 10.6306
Proc:0 lbl:1 dgemm64 time= 2.64217e+09 ops/cycle= 13.0044
Proc:0 lbl:1 dgemm128 time= 4.77055e+09 ops/cycle= 14.4049
Proc:0 lbl:1 main dgemm time= 1.1808e+11 ops/cycle= 180.549
Proc:0 lbl:1 col trsm time= 2.24339e+09 ops/cycle= 20.421
Proc:0 lbl:1 col update time= 4.57442e+10 ops/cycle= 1.00149
Proc:0 lbl:1 col r dgemm time= 3.69863e+10 ops/cycle= 29.6114
Proc:0 lbl:1 col right misc time= 6.50961e+09 ops/cycle= 0.329894
Proc:0 lbl:1 backsub time= 4.85309e+09 ops/cycle= 0.221249
Proc:0 lbl:1 col dec total time= 5.74051e+10 ops/cycle= 0.00986377
cpusec = 123.382 wsec=78.3879 299.233 Gflops
lu2_gdr
15.2. 2009/12/10
Error = 3.139189e-10
Proc:0 lbl:1 update time= 8.3975e+10 ops/cycle= 229.133
Proc:0 lbl:1 update matmul time= 8.31377e+10 ops/cycle= 207.47
Proc:0 lbl:1 update swap+bcast time= 5.99923e+09 ops/cycle= 0.61804
Proc:0 lbl:1 total time= 1.74741e+11 ops/cycle= 110.606
Proc:0 lbl:1 rfact time= 7.33068e+10 ops/cycle= 0.00680868
Proc:0 lbl:1 ldmul time= 1.7499e+10 ops/cycle= 103.085
Proc:0 lbl:1 colum dec with trans time= 7.34937e+09 ops/cycle= 0.0642208
Proc:0 lbl:1 colum dec right time= 4.24429e+10 ops/cycle= 11.8458
Proc:0 lbl:1 colum dec left time= 3.66998e+08 ops/cycle= 0.0853803
Proc:0 lbl:1 rowtocol time= 1.54309e+09 ops/cycle= 0.305868
Proc:0 lbl:1 column dec in trans time= 4.99534e+09 ops/cycle= 0.755876
Proc:0 lbl:1 coltorow time= 8.02318e+08 ops/cycle= 0.588273
Proc:0 lbl:1 dgemm8 time= 9.81078e+08 ops/cycle= 3.84768
Proc:0 lbl:1 dgemm16 time= 1.06053e+09 ops/cycle= 7.11884
Proc:0 lbl:1 dgemm32 time= 1.4035e+09 ops/cycle= 10.7584
Proc:0 lbl:1 dgemm64 time= 2.31584e+09 ops/cycle= 13.0402
Proc:0 lbl:1 dgemm128 time= 4.18114e+09 ops/cycle= 14.4453
Proc:0 lbl:1 main dgemm time= 9.8495e+10 ops/cycle= 177.183
Proc:0 lbl:1 col trsm time= 2.08341e+09 ops/cycle= 20.6148
Proc:0 lbl:1 col update time= 4.00176e+10 ops/cycle= 1.07325
Proc:0 lbl:1 col r dgemm time= 3.23433e+10 ops/cycle= 29.7618
Proc:0 lbl:1 col right misc time= 5.58615e+09 ops/cycle= 0.337878
Proc:0 lbl:1 backsub time= 4.2361e+09 ops/cycle= 0.22278
Proc:0 lbl:1 col dec total time= 5.01653e+10 ops/cycle= 0.00994955
cpusec = 106.328 wsec=66.9643 288.622 Gflops
Proc:0 lbl:1 rfact time= 7.33068e+10 ops/cycle= 0.00680868
Proc:0 lbl:1 col dec total time= 5.01653e+10 ops/cycle= 0.00994955
Proc:0 lbl:1 colum dec right time= 4.24429e+10 ops/cycle= 11.8458
Proc:0 lbl:1 colum dec left time= 3.66998e+08 ops/cycle= 0.0853803
Proc:0 lbl:1 colum dec with trans time= 7.34937e+09 ops/cycle= 0.0642208
Error = 1.289304e-10
Proc:0 lbl:1 update time= 1.63632e+09 ops/cycle= 209.981
Proc:0 lbl:1 update matmul time= 1.50643e+09 ops/cycle= 159.661
Proc:0 lbl:1 update swap+bcast time= 8.57218e+07 ops/cycle= 0.195717
Proc:0 lbl:1 total time= 1.02782e+10 ops/cycle= 35.6585
Proc:0 lbl:1 rfact time= 7.83408e+09 ops/cycle= 0.00481853
Proc:0 lbl:1 ldmul time= 1.16044e+09 ops/cycle= 88.8275
Proc:0 lbl:1 colum dec with trans time= 7.93445e+08 ops/cycle= 0.0423308
Proc:0 lbl:1 colum dec right time= 3.98414e+09 ops/cycle= 10.0278
Proc:0 lbl:1 colum dec left time= 9.33899e+07 ops/cycle= 0.0894726
Proc:0 lbl:1 rowtocol time= 1.33051e+08 ops/cycle= 0.252438
Proc:0 lbl:1 column dec in trans time= 5.7203e+08 ops/cycle= 0.469726
Proc:0 lbl:1 coltorow time= 8.67459e+07 ops/cycle= 0.387191
Proc:0 lbl:1 dgemm8 time= 6.76419e+07 ops/cycle= 3.96848
Proc:0 lbl:1 dgemm16 time= 6.90931e+07 ops/cycle= 7.77026
Proc:0 lbl:1 dgemm32 time= 9.50601e+07 ops/cycle= 11.2954
Proc:0 lbl:1 dgemm64 time= 1.65391e+08 ops/cycle= 12.9843
Proc:0 lbl:1 dgemm128 time= 3.00057e+08 ops/cycle= 14.3138
Proc:0 lbl:1 main dgemm time= 2.51034e+09 ops/cycle= 96.1318
Proc:0 lbl:1 col trsm time= 5.51606e+08 ops/cycle= 20.7631
Proc:0 lbl:1 col update time= 3.33323e+09 ops/cycle= 3.43603
Proc:0 lbl:1 col r dgemm time= 2.41619e+09 ops/cycle= 28.3301
Proc:0 lbl:1 col right misc time= 3.64573e+08 ops/cycle= 0.36815
Proc:0 lbl:1 backsub time= 3.11763e+08 ops/cycle= 0.215256
Proc:0 lbl:1 col dec total time= 4.8722e+09 ops/cycle= 0.00774777
Proc:0 lbl:1 DGEMM2k time= 3.51966e+09 ops/cycle= 117.423
Proc:0 lbl:1 DGEMM1k time= 1.27689e+09 ops/cycle= 47.0906
Proc:0 lbl:1 DGEMM512 time= 1.18782e+09 ops/cycle= 21.695
Proc:0 lbl:1 DGEMMrest time= 1.66845e+09 ops/cycle= 12.3749
cpusec = 7.08792 wsec=3.96233 92.497 Gflops
Emax= 1.406e-08
Nswap=0 cpsec = 6.01409 wsec=3.12815 117.163 Gflops
swaprows time= 1.87592e+08 ops/cycle=0.178869
scalerow time= 2.94069e+07 ops/cycle=1.14104
trans rtoc time= 7.9404e+07 ops/cycle=0.422579
trans ctor time= 6.74848e+07 ops/cycle=0.497215
trans mmul time= 2.63212e+08 ops/cycle=1.91221
tr nr cdec time= 8.25043e+07 ops/cycle=0.406699
trans vvmul time= 2.93499e+07 ops/cycle=1.14325
trans findp time= 5.04255e+07 ops/cycle=0.665426
solve tri u time= 1.72505e+09 ops/cycle=4.74884e-06
solve tri time= 1.667e+09 ops/cycle=82.4468
matmul nk8 time= 0 ops/cycle=inf
matmul snk time= 69688 ops/cycle=7703.92
trans mmul8 time= 9.55725e+07 ops/cycle=2.80871
trans mmul4 time= 8.17092e+07 ops/cycle=1.64263
trans mmul2 time= 8.48264e+07 ops/cycle=0.791132
DGEMM2K time= 2.77013e+09 ops/cycle=107.498
DGEMM1K time= 1.27147e+09 ops/cycle=27.0235
DGEMM512 time= 1.18622e+09 ops/cycle=14.4828
DGEMMrest time= 1.89104e+09 ops/cycle=9.08487
col dec t time= 5.10414e+08 ops/cycle=2.10367
Total time= 8.23662e+09 ops/cycle=44.4969
= 0.3sec
ucomm non-ovl:
Error = 1.289304e-10
Proc:0 lbl:1 update time= 1.33766e+09 ops/cycle= 256.865
Proc:0 lbl:1 update matmul time= 1.14235e+09 ops/cycle= 210.546
Proc:0 lbl:1 update swap+bcast time= 6.64721e+07 ops/cycle= 0.252395
Proc:0 lbl:1 total time= 9.95987e+09 ops/cycle= 36.7981
Proc:0 lbl:1 rfact time= 7.81896e+09 ops/cycle= 0.00482785
Proc:0 lbl:1 ldmul time= 1.16817e+09 ops/cycle= 88.2401
Proc:0 lbl:1 colum dec with trans time= 7.84608e+08 ops/cycle= 0.0428076
Proc:0 lbl:1 colum dec right time= 3.9726e+09 ops/cycle= 10.0569
Proc:0 lbl:1 colum dec left time= 9.35108e+07 ops/cycle= 0.089357
Proc:0 lbl:1 rowtocol time= 1.33374e+08 ops/cycle= 0.251827
Proc:0 lbl:1 column dec in trans time= 5.63945e+08 ops/cycle= 0.47646
Proc:0 lbl:1 coltorow time= 8.54167e+07 ops/cycle= 0.393216
Proc:0 lbl:1 dgemm8 time= 6.79698e+07 ops/cycle= 3.94933
Proc:0 lbl:1 dgemm16 time= 6.9072e+07 ops/cycle= 7.77263
Proc:0 lbl:1 dgemm32 time= 9.49168e+07 ops/cycle= 11.3125
Proc:0 lbl:1 dgemm64 time= 1.64665e+08 ops/cycle= 13.0415
Proc:0 lbl:1 dgemm128 time= 3.00238e+08 ops/cycle= 14.3052
Proc:0 lbl:1 main dgemm time= 2.14529e+09 ops/cycle= 112.49
Proc:0 lbl:1 col trsm time= 5.50394e+08 ops/cycle= 20.8088
Proc:0 lbl:1 col update time= 3.32787e+09 ops/cycle= 3.44156
Proc:0 lbl:1 col r dgemm time= 2.41403e+09 ops/cycle= 28.3555
Proc:0 lbl:1 col right misc time= 3.62584e+08 ops/cycle= 0.37017
Proc:0 lbl:1 backsub time= 3.10153e+08 ops/cycle= 0.216373
Proc:0 lbl:1 col dec total time= 4.85184e+09 ops/cycle= 0.00778029
Proc:0 lbl:1 DGEMM2k time= 3.16488e+09 ops/cycle= 130.586
Proc:0 lbl:1 DGEMM1k time= 1.27577e+09 ops/cycle= 47.1321
Proc:0 lbl:1 DGEMM512 time= 1.19026e+09 ops/cycle= 21.6506
Proc:0 lbl:1 DGEMMrest time= 1.66784e+09 ops/cycle= 12.3795
cpusec = 7.16291 wsec=3.84264 95.3782 Gflops
non-ovl だと 0.39e9 cycles 0.15 sec
gdrdgemm non-gdr-dgemm rest total
mpi 5.62 1.67 2.66 9.95
nonmpi 5.22 1.89 1.11 8.22
なので、 non-gdr の部分がまだ倍程度遅い。その一部は TRSM なのでしょう
がないけど。
int jmin = current_lrow - nb+1;
for(k=0;k<nb;k++){
int jmax;
jmax = current_lrow-k;
bwork[k]=b[jmax];
double btmp=bwork[k];
for(j=jmin;j<jmax;j++){
b[j] -= btmp*a[j][current_lcol-k];
}
}
jと k を入れ替えできるはず。
int jmin = current_lrow - nb+1;
for(k=0;k<nb;k++){
int jmax;
jmax = current_lrow-k;
bwork[k]=b[jmax];
for(j=jmin;j<jmax;j++){
b[j] -= b[current_lrow-k]*a[j][current_lcol-k];
}
}
for(j=n-2;j>=0;j--)
for(k=j+1;k<n;k++) b[j] -= b[k]*a[j][k];
for(j=current_lrow-1;j>=current_lrow-nb+1;j--){
for(k=1;k<current_lrow-j;k++){
b[j] -= b[current_lrow-k]*a[j][current_lcol-k];
}
}
結局 OMP いれた。
Proc:0 lbl:1 backsub time= 1.01146e+08 ops/cycle= 0.663488
col decomp with transpose 3-4
DGEMM2K 3
で 7 は説明ついていて、あと 10 近く遅い。
cpusec = 7.12992 wsec=3.78453 96.8427 Gflops
Proc:0 lbl:1 DGEMMrest time= 1.66783e+09 ops/cycle= 12.3796
Proc:0 lbl:1 TRSM U time= 1.66031e+09 ops/cycle= 24.1439
Proc:0 lbl:1 col r swap/scale time= 9.46556e+07 ops/cycle= 0.176552
cpusec = 7.08892 wsec=3.80358 96.3575 Gflops
Proc:0 lbl:1 total time= 1.00634e+10 ops/cycle= 36.4195
Proc:0 lbl:1 rfact time= 8.66379e+09 ops/cycle= 0.00435707
Proc:0 lbl:1 update time= 1.3379e+09 ops/cycle= 256.818
MPI_Bcast(pv,sizeof(int)*nb,MPI_BYTE, pcolid(i,parms,controls),
controls->row_comm);
MP_construct_scalevector(nnrow, nncol, a, parms, controls, i, nb, scale);
MPI_Bcast(scale,sizeof(double)*nb,MPI_BYTE, pcolid(i,parms,controls),
controls->row_comm);
MP_process_diagonal(nnrow, nncol, a, parms, controls,
i,nb,acolinv,0);
int nrows=MP_process_lmat(nnrow, nncol, a, parms, controls,i,nb,i+nb,acol);
MP_calculate_ld(nb, acol, nrows, acol2, acolinv,i,controls, parms);
misc2:
process_right_part_mpi_using_dls_phase1(i, nb, c1, c2, nnrow,
nncol, a, aip, acp,arp,
pvp,scalep,
controls, parms);
process_right_part_mpi_using_dls_phase2(i, nb, c1, c2, nnrow,
nncol, a, aip, acp,arp,
pvp,scalep,
controls, parms);
misc3:
MP_process_diagonal_phase1(nnrow, nncol, a, parms, controls,
misc4:
check_and_continue_rcomm_transfer(&rcomm,1);
print_current_time("end lmat/dls");
MP_update_multiple_using_diagonal(nnrow, nncol, a, parms,
controls,
i,controls->ncol,controls->ncol+1,nb,aip);
MP_store_diagonal_inverse(nnrow, nb, dinv, parms,controls, i, aip);
MP_calculate_ld_phase1(nb, acp2, nrows, aip2, ii,
controls, parms);
MP_calculate_ld_phase2(nb, acp2, nrows, acp, aip2, ii,controls, parms);
non-uc での数字
Error = 1.265311e-10
Proc:0 lbl:1 update time= 1.34046e+09 ops/cycle= 256.329
Proc:0 lbl:1 update matmul time= 1.14394e+09 ops/cycle= 210.254
Proc:0 lbl:1 update swap+bcast time= 1.95494e+08 ops/cycle= 0.300369
Proc:0 lbl:1 total time= 9.97657e+09 ops/cycle= 36.7365
Proc:0 lbl:1 rfact time= 8.57351e+09 ops/cycle= 0.00440295
Proc:0 lbl:1 ldmul time= 1.16319e+09 ops/cycle= 88.618
Proc:0 lbl:1 colum dec with trans time= 7.82838e+08 ops/cycle= 0.0429044
Proc:0 lbl:1 colum dec right time= 3.98307e+09 ops/cycle= 10.0305
Proc:0 lbl:1 colum dec left time= 9.27519e+07 ops/cycle= 0.0900881
Proc:0 lbl:1 rowtocol time= 1.30361e+08 ops/cycle= 0.257647
Proc:0 lbl:1 column dec in trans time= 5.64778e+08 ops/cycle= 0.475758
Proc:0 lbl:1 coltorow time= 8.60163e+07 ops/cycle= 0.390475
Proc:0 lbl:1 dgemm8 time= 6.77938e+07 ops/cycle= 3.95959
Proc:0 lbl:1 dgemm16 time= 6.90448e+07 ops/cycle= 7.77569
Proc:0 lbl:1 dgemm32 time= 9.50717e+07 ops/cycle= 11.294
Proc:0 lbl:1 dgemm64 time= 1.64748e+08 ops/cycle= 13.035
Proc:0 lbl:1 dgemm128 time= 3.00654e+08 ops/cycle= 14.2854
Proc:0 lbl:1 main dgemm time= 2.14864e+09 ops/cycle= 112.314
Proc:0 lbl:1 col trsm time= 1.10443e+09 ops/cycle= 11.2343
Proc:0 lbl:1 col update time= 2.78344e+09 ops/cycle= 4.11472
Proc:0 lbl:1 col r dgemm time= 2.41916e+09 ops/cycle= 28.2954
Proc:0 lbl:1 col right misc time= 3.63705e+08 ops/cycle= 0.369029
Proc:0 lbl:1 backsub time= 1.02153e+08 ops/cycle= 0.656942
Proc:0 lbl:1 col dec total time= 4.85997e+09 ops/cycle= 0.00776728
Proc:0 lbl:1 DGEMM2k time= 3.16187e+09 ops/cycle= 130.711
Proc:0 lbl:1 DGEMM1k time= 1.28382e+09 ops/cycle= 46.8363
Proc:0 lbl:1 DGEMM512 time= 1.19964e+09 ops/cycle= 21.4813
Proc:0 lbl:1 DGEMMrest time= 1.66733e+09 ops/cycle= 12.3832
Proc:0 lbl:1 TRSM U time= 1.6427e+09 ops/cycle= 24.4027
Proc:0 lbl:1 col r swap/scale time= 9.4584e+07 ops/cycle= 0.176686
Proc:0 lbl:1 rfact ex coldec time= 3.71302e+09 ops/cycle= 0
Proc:0 lbl:1 ld_phase1 time= 20240 ops/cycle= 828.914
Proc:0 lbl:1 rfact misc1 time= 8.97017e+08 ops/cycle= 0
Proc:0 lbl:1 rfact misc2 time= 1.19039e+09 ops/cycle= 0
Proc:0 lbl:1 rfact misc3 time= 8.8732e+08 ops/cycle= 0
Proc:0 lbl:1 rfact misc4 time= 7.38299e+08 ops/cycle= 0
cpusec = 7.14491 wsec=3.77106 97.1884 Gflops
Emax= 1.406e-08
Nswap=0 cpsec = 6.04808 wsec=3.12539 117.267 Gflops
swaprows time= 1.86838e+08 ops/cycle=0.179591
scalerow time= 2.94364e+07 ops/cycle=1.13989
trans rtoc time= 7.88049e+07 ops/cycle=0.425791
trans ctor time= 6.54667e+07 ops/cycle=0.512542
trans mmul time= 2.57285e+08 ops/cycle=1.95626
tr nr cdec time= 8.17042e+07 ops/cycle=0.410682
trans vvmul time= 2.92133e+07 ops/cycle=1.1486
trans findp time= 5.0332e+07 ops/cycle=0.666663
solve tri u time= 1.7223e+09 ops/cycle=4.75644e-06
solve tri time= 1.66216e+09 ops/cycle=82.6871
matmul nk8 time= 0 ops/cycle=inf
matmul snk time= 63024 ops/cycle=8518.52
trans mmul8 time= 8.9048e+07 ops/cycle=3.0145
trans mmul4 time= 8.21812e+07 ops/cycle=1.63319
trans mmul2 time= 8.48754e+07 ops/cycle=0.790675
DGEMM2K time= 2.78007e+09 ops/cycle=107.114
DGEMM1K time= 1.27326e+09 ops/cycle=26.9857
DGEMM512 time= 1.18439e+09 ops/cycle=14.5053
DGEMMrest time= 1.89063e+09 ops/cycle=9.08685
col dec t time= 5.00253e+08 ops/cycle=2.1464
Total time= 8.22907e+09 ops/cycle=44.5377
cpusec = 309.991 wsec=206.913 2522.02 Gflops
Proc:8 lbl:1 update time= 3.62049e+11 ops/cycle= 1440.64
Proc:8 lbl:1 update matmul time= 3.06794e+11 ops/cycle= 567.148
Proc:8 lbl:1 update swap+bcast time= 2.66005e+11 ops/cycle= 0.159696
Proc:8 lbl:1 total time= 5.48239e+11 ops/cycle= 951.846
Proc:8 lbl:1 rfact time= 1.82286e+11 ops/cycle= 0.0237918
Proc:8 lbl:1 ldmul time= 6.04587e+10 ops/cycle= 98.0348
Proc:8 lbl:1 colum dec with trans time= 9.53348e+09 ops/cycle= -0.0560814
Proc:8 lbl:1 colum dec right time= 5.04669e+10 ops/cycle= -10.3829
Proc:8 lbl:1 colum dec left time= 5.08962e+09 ops/cycle= 0.00615653
Proc:8 lbl:1 rowtocol time= 1.72315e+09 ops/cycle= 0.273906
Proc:8 lbl:1 column dec in trans time= 6.91118e+09 ops/cycle= 0.546341
Proc:8 lbl:1 coltorow time= 8.90535e+08 ops/cycle= 0.529998
Proc:8 lbl:1 dgemm8 time= 1.1339e+09 ops/cycle= 3.32912
Proc:8 lbl:1 dgemm16 time= 1.19888e+09 ops/cycle= 6.29735
Proc:8 lbl:1 dgemm32 time= 1.46489e+09 ops/cycle= 10.3076
Proc:8 lbl:1 dgemm64 time= 2.36012e+09 ops/cycle= 12.7955
Proc:8 lbl:1 dgemm128 time= 4.21923e+09 ops/cycle= 14.3149
Proc:8 lbl:1 main dgemm time= 3.25e+11 ops/cycle= 184.892
Proc:8 lbl:1 col trsm time= 4.31115e+09 ops/cycle= 10.7925
Proc:8 lbl:1 col update time= 4.12245e+10 ops/cycle= 1.04183
Proc:8 lbl:1 col r dgemm time= 3.28039e+10 ops/cycle= 29.3438
Proc:8 lbl:1 col right misc time= 8.41697e+09 ops/cycle= 0.224242
Proc:8 lbl:1 backsub time= 4.77323e+09 ops/cycle= 1.7794
Proc:8 lbl:1 col dec total time= 6.50962e+10 ops/cycle= 0.0240977
Proc:8 lbl:1 DGEMM2k time= 3.74878e+11 ops/cycle= 176.791
Proc:8 lbl:1 DGEMM1k time= 9.79302e+09 ops/cycle= 59.2075
Proc:8 lbl:1 DGEMM512 time= 9.76588e+09 ops/cycle= 28.0368
Proc:8 lbl:1 DGEMMrest time= 2.00374e+10 ops/cycle= 12.5678
Proc:8 lbl:1 TRSM U time= 6.3099e+09 ops/cycle= 23.8235
Proc:8 lbl:1 col r swap/scale time= 4.92817e+09 ops/cycle= 0.0127165
Proc:8 lbl:1 rfact ex coldec time= 1.17188e+11 ops/cycle= 0
Proc:8 lbl:1 ld_phase1 time= 7.45724e+09 ops/cycle= 0.0253101
Proc:8 lbl:1 rfact misc1 time= 1.29572e+10 ops/cycle= 0
Proc:8 lbl:1 rfact misc2 time= 2.96095e+10 ops/cycle= 0
Proc:8 lbl:1 rfact misc3 time= 4.60131e+09 ops/cycle= 0
Proc:8 lbl:1 rfact misc4 time= 7.00195e+10 ops/cycle= 0
Proc:8 lbl:1 copysubmats time= 7.10105e+09 ops/cycle= 0.279069
Error = 9.393042e-10
Proc:0 lbl:1 update time= 3.31323e+11 ops/cycle= 1574.24
Proc:0 lbl:1 update matmul time= 2.6673e+11 ops/cycle= 608.41
Proc:0 lbl:1 update swap+bcast time= 2.66687e+11 ops/cycle= 0.148561
Proc:0 lbl:1 total time= 5.48204e+11 ops/cycle= 951.905
Proc:0 lbl:1 rfact time= 2.14294e+11 ops/cycle= 0.0202381
Proc:0 lbl:1 ldmul time= 5.24644e+10 ops/cycle= 103.149
Proc:0 lbl:1 colum dec with trans time= 1.31e+10 ops/cycle= -0.0312077
Proc:0 lbl:1 colum dec right time= 4.99062e+10 ops/cycle= -7.92785
Proc:0 lbl:1 colum dec left time= 5.64448e+09 ops/cycle= 0.00555134
Proc:0 lbl:1 rowtocol time= 1.50888e+09 ops/cycle= 0.312802
Proc:0 lbl:1 column dec in trans time= 1.07553e+10 ops/cycle= 0.35107
Proc:0 lbl:1 coltorow time= 8.27492e+08 ops/cycle= 0.570376
Proc:0 lbl:1 dgemm8 time= 9.83399e+08 ops/cycle= 3.8386
Proc:0 lbl:1 dgemm16 time= 1.0627e+09 ops/cycle= 7.10431
Proc:0 lbl:1 dgemm32 time= 1.41171e+09 ops/cycle= 10.6959
Proc:0 lbl:1 dgemm64 time= 2.32834e+09 ops/cycle= 12.9702
Proc:0 lbl:1 dgemm128 time= 4.19898e+09 ops/cycle= 14.384
Proc:0 lbl:1 main dgemm time= 2.82077e+11 ops/cycle= 185.605
Proc:0 lbl:1 col trsm time= 4.13363e+09 ops/cycle= 11.256
Proc:0 lbl:1 col update time= 4.00302e+10 ops/cycle= 1.07292
Proc:0 lbl:1 col r dgemm time= 3.25541e+10 ops/cycle= 29.569
Proc:0 lbl:1 col right misc time= 7.47281e+09 ops/cycle= 0.252574
Proc:0 lbl:1 backsub time= 4.81698e+09 ops/cycle= 1.76323
Proc:0 lbl:1 col dec total time= 6.86564e+10 ops/cycle= 0.0219318
Proc:0 lbl:1 DGEMM2k time= 3.26141e+11 ops/cycle= 177.913
Proc:0 lbl:1 DGEMM1k time= 9.79213e+09 ops/cycle= 59.2129
Proc:0 lbl:1 DGEMM512 time= 9.77504e+09 ops/cycle= 28.0105
Proc:0 lbl:1 DGEMMrest time= 1.95494e+10 ops/cycle= 12.8815
Proc:0 lbl:1 TRSM U time= 6.08464e+09 ops/cycle= 24.7054
Proc:0 lbl:1 col r swap/scale time= 5.73952e+09 ops/cycle= 0.0109188
Proc:0 lbl:1 rfact ex coldec time= 1.45635e+11 ops/cycle= 0
Proc:0 lbl:1 ld_phase1 time= 1.77314e+10 ops/cycle= 0.0106446
Proc:0 lbl:1 rfact misc1 time= 5.31556e+09 ops/cycle= 0
Proc:0 lbl:1 rfact misc2 time= 2.81408e+10 ops/cycle= 0
Proc:0 lbl:1 rfact misc3 time= 4.08916e+09 ops/cycle= 0
Proc:0 lbl:1 rfact misc4 time= 1.0809e+11 ops/cycle= 0
Proc:0 lbl:1 copysubmats time= 6.00964e+09 ops/cycle= 0.338824
Error = 2.938615e-10
Proc:0 lbl:1 update time= 1.01502e+11 ops/cycle= 230.19
Proc:0 lbl:1 update matmul time= 1.00601e+11 ops/cycle= 209.709
Proc:0 lbl:1 update swap+bcast time= 7.84566e+09 ops/cycle= 0.656491
Proc:0 lbl:1 total time= 2.04397e+11 ops/cycle= 114.759
Proc:0 lbl:1 rfact time= 1.00804e+11 ops/cycle= 0.00561718
Proc:0 lbl:1 ldmul time= 1.97303e+10 ops/cycle= 104.488
Proc:0 lbl:1 colum dec with trans time= 8.67499e+09 ops/cycle= 0.0619023
Proc:0 lbl:1 colum dec right time= 4.82205e+10 ops/cycle= 11.8314
Proc:0 lbl:1 colum dec left time= 3.92583e+08 ops/cycle= 0.0851371
Proc:0 lbl:1 rowtocol time= 2.0472e+09 ops/cycle= 0.262311
Proc:0 lbl:1 column dec in trans time= 5.60226e+09 ops/cycle= 0.766836
Proc:0 lbl:1 coltorow time= 1.01505e+09 ops/cycle= 0.52904
Proc:0 lbl:1 dgemm8 time= 1.14001e+09 ops/cycle= 3.76748
Proc:0 lbl:1 dgemm16 time= 1.23781e+09 ops/cycle= 6.93964
Proc:0 lbl:1 dgemm32 time= 1.61718e+09 ops/cycle= 10.6233
Proc:0 lbl:1 dgemm64 time= 2.64121e+09 ops/cycle= 13.0091
Proc:0 lbl:1 dgemm128 time= 4.76127e+09 ops/cycle= 14.433
Proc:0 lbl:1 main dgemm time= 1.18091e+11 ops/cycle= 180.532
Proc:0 lbl:1 col trsm time= 4.40175e+09 ops/cycle= 11.2751
Proc:0 lbl:1 col update time= 4.34209e+10 ops/cycle= 1.05507
Proc:0 lbl:1 col r dgemm time= 3.69038e+10 ops/cycle= 29.6776
Proc:0 lbl:1 col right misc time= 6.51389e+09 ops/cycle= 0.329678
Proc:0 lbl:1 backsub time= 1.5432e+09 ops/cycle= 0.69579
Proc:0 lbl:1 col dec total time= 5.72942e+10 ops/cycle= 0.00988288
Proc:0 lbl:1 DGEMM2k time= 1.34666e+11 ops/cycle= 175.663
Proc:0 lbl:1 DGEMM1k time= 1.08127e+10 ops/cycle= 60.377
Proc:0 lbl:1 DGEMM512 time= 1.09045e+10 ops/cycle= 28.3586
Proc:0 lbl:1 DGEMMrest time= 2.21242e+10 ops/cycle= 12.9056
Proc:0 lbl:1 TRSM U time= 6.44717e+09 ops/cycle= 24.8706
Proc:0 lbl:1 col r swap/scale time= 3.94522e+08 ops/cycle= 0.169437
Proc:0 lbl:1 rfact ex coldec time= 4.35071e+10 ops/cycle= 0
Proc:0 lbl:1 ld_phase1 time= 92348 ops/cycle= 726.695
Proc:0 lbl:1 rfact misc1 time= 2.98368e+09 ops/cycle= 0
Proc:0 lbl:1 rfact misc2 time= 1.84234e+10 ops/cycle= 0
Proc:0 lbl:1 rfact misc3 time= 4.35268e+09 ops/cycle= 0
Proc:0 lbl:1 rfact misc4 time= 1.77474e+10 ops/cycle= 0
Proc:0 lbl:1 copysubmats time= 6.90548e+09 ops/cycle= 0.334044
cpusec = 123.014 wsec=77.0525 304.419 Gflops
mt/mpi 比較
Error = 5.565707e-11
Proc:0 lbl:1 update time= 7.92986e+10 ops/cycle= 4.60377
Proc:0 lbl:1 update matmul time= 7.92317e+10 ops/cycle= 4.16044
Proc:0 lbl:1 update swap+bcast time= 4.14927e+08 ops/cycle= 0.77583
Proc:0 lbl:1 total time= 8.70284e+10 ops/cycle= 4.21131
Proc:0 lbl:1 rfact time= 7.5768e+09 ops/cycle= 0.00467076
Proc:0 lbl:1 ldmul time= 2.44332e+09 ops/cycle= 13.1838
Proc:0 lbl:1 colum dec with trans time= 8.05956e+08 ops/cycle= 0.0416737
Proc:0 lbl:1 colum dec right time= 1.80899e+09 ops/cycle= 4.87207
Proc:0 lbl:1 colum dec left time= 3.37718e+07 ops/cycle= 0.0611274
Proc:0 lbl:1 rowtocol time= 1.00115e+08 ops/cycle= 0.335487
Proc:0 lbl:1 column dec in trans time= 6.01137e+08 ops/cycle= 0.446983
Proc:0 lbl:1 coltorow time= 1.02631e+08 ops/cycle= 0.327263
Proc:0 lbl:1 dgemm8 time= 7.53245e+07 ops/cycle= 3.56372
Proc:0 lbl:1 dgemm16 time= 7.24839e+07 ops/cycle= 7.40677
Proc:0 lbl:1 dgemm32 time= 9.64436e+07 ops/cycle= 11.1334
Proc:0 lbl:1 dgemm64 time= 1.65372e+08 ops/cycle= 12.9858
Proc:0 lbl:1 dgemm128 time= 3.0028e+08 ops/cycle= 14.3032
Proc:0 lbl:1 main dgemm time= 8.13805e+10 ops/cycle= 4.10254
Proc:0 lbl:1 col trsm time= 2.48988e+08 ops/cycle= 3.11377
Proc:0 lbl:1 col update time= 1.52578e+09 ops/cycle= 0.469041
Proc:0 lbl:1 col r dgemm time= 1.28862e+09 ops/cycle= 13.1237
Proc:0 lbl:1 col right misc time= 2.36579e+08 ops/cycle= 0.425495
Proc:0 lbl:1 backsub time= 1.43123e+08 ops/cycle= 0.468891
Proc:0 lbl:1 col dec total time= 2.64994e+09 ops/cycle= 0.0133548
Proc:0 lbl:1 DGEMM2k time= 0 ops/cycle= nan
Proc:0 lbl:1 DGEMM1k time= 0 ops/cycle= nan
Proc:0 lbl:1 DGEMM512 time= 8.36238e+10 ops/cycle= 4.37779
Proc:0 lbl:1 DGEMMrest time= 1.55536e+09 ops/cycle= 12.3686
Proc:0 lbl:1 TRSM U time= 3.36808e+08 ops/cycle= 7.43839
Proc:0 lbl:1 col r swap/scale time= 3.36903e+07 ops/cycle= 0.122551
Proc:0 lbl:1 rfact ex coldec time= 4.92652e+09 ops/cycle= 0
Proc:0 lbl:1 ld_phase1 time= 81844 ops/cycle= 51.2475
Proc:0 lbl:1 rfact misc1 time= 3.39962e+08 ops/cycle= 0
Proc:0 lbl:1 rfact misc2 time= 2.20707e+09 ops/cycle= 0
Proc:0 lbl:1 rfact misc3 time= 2.11657e+08 ops/cycle= 0
Proc:0 lbl:1 rfact misc4 time= 2.16784e+09 ops/cycle= 0
Proc:0 lbl:1 copysubmats time= 2.58996e+08 ops/cycle= 0.427002
4851 3:24 cd singlibMC_tb4
4852 3:24 ls
4853 3:24 ls pll*
4854 3:25 pllconf 22
4855 3:25 ./pllconf 22
4856 3:25 ls -tlra pllconf
4857 3:25 cd pllconf
4858 3:25 ls
4859 3:25 ./pllconf 22
4860 3:25 cd ~/src/linsol/lib*2*tst
4851 3:24 cd singlibMC_tb4
4852 3:24 ls
4853 3:24 ls pll*
4854 3:25 pllconf 22
4855 3:25 ./pllconf 22
4856 3:25 ls -tlra pllconf
4857 3:25 cd pllconf
4858 3:25 ls
4859 3:25 ./pllconf 22
4860 3:25 cd ~/src/linsol/lib*2*tst
setcounter(c, 0x1, 0x0, mcnt); //m=24 for 400MHz , m=23 for 383MHz , m=22 fo
r 366MHz ,m=21 for 350MHz , m=20 for 333Mhz
3ff8b2597704b7c0
3fe9a2fa4eeb6f80
0001 0001
j を単位行列にすると:
err = 0.000000e+00 2.609343e-04
maxerr = 2.609343e-04 nerrors=17
hib[4] closed.
hib[5] closed.
hib[6] closed.
hib[7] closed.
backsendamat_mtwork(&amatdata);
backcalcmatc_mtwork(&cmatdata);
とシリアルに動作させた時。
copytomata_em_1024_tb4_dg(LDA, NOTA, a, i+DIM1, ichip, DIMK, aem);
1024語づつ送っている: PE あたり 64 語
Previous
ToC
Next