lu2 を実際に GRAPE-DR で動かしてみてもらったところ、結構良い性能がでま
した。そうすると、もっと抜本的な改善の方法はないかというのが問題です。
というわけで、 GDR でのテストをしてくれた小池君と色々議論ひたら、いく
つかよさそうなアイディアがでてきました。以下は、そういうわけで私のオリ
ジナルアイディアというわけではなくて、議論の中ででてきたものです。
これまでみてきたところでは、
という式で物事を考えてきました。そうすると、計算時間の内訳はこんな感じ
です。
GDR DGEMM 時間
計算時間
計算時間に隠蔽できない通信時間
K=2048 の時の時間
K<=1024 の時の時間
GDR DGEMM 以外
ホストでの DGEMM
ホストでの、行交換、ピボット探索等
Core i7 で 12GB のメモリの時に、 GDR DGEMM 時間は GDR の枚数、速度によります
が 20 から 50 秒になります。これに対して、ホストでの DGEMM は k をどこ
までするかに依存しますが 5-10秒、それ以外の残りが 5-7秒なので、例えば
GDR での計算時間が 20秒になっても、残りで 20秒近くかかっては効率が半分
で、たとえ全体が 40秒なら実効 700Gflops 程度となり、逆に実行 1 Tflops
にするためには全体を 28秒にする必要があり、 DGEMM のところを10秒程度、
つまり 3TF 程度必要、ということになってしまいます。
しかし、 GRAPE での伝統的なチューニングでは、ここまできた時の定石があり
ます。それは、「ホストでの計算と GRAPE での計算をオーバーラップさせる」
というものです。上の場合では、DGEMM の計算をしている間に他の処理を、と
いうわけです。
ブロック化したアルゴリズムでは
縦ブロック変形 (PUPDATE)
残り部分の行交換 (SWAP)
右上の変形 (DTRSM)
残り全体の変形 (UPDATE)
という順番で計算が進むのですが、次の縦ブロック変形は別に UPDATE 全部が
終わるまで待つ必要はなくて、縦ブロックの変形をするのに必要なところまで
UPDATE が終わっていればよいつまり、ブロックの行数分がおわっていれば十分
です。さらにいえば、縦ブロックの変形自体が左から進んでいくので、これが
UPDATE 処理を追い越してしまわなければよいわけで原理的には DGEMM が 1 行
終われば PUPDATE を開始できます。
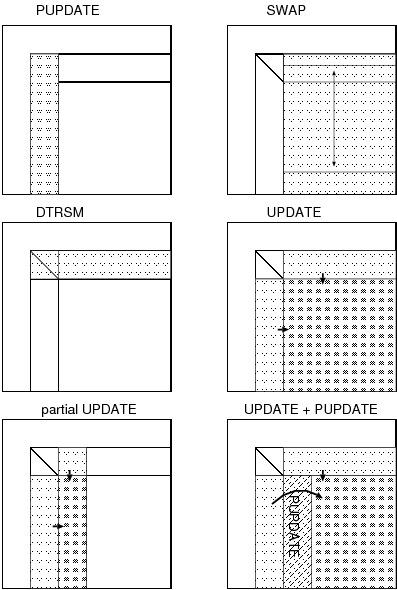
Figure 1: 普通の UPDATE と、 PUPDATE と UPDATE の並列実行
GDR での DGEMM の場合には、 GRAPE の通常の処理と違って計算中にずーっと
通信もしており、そのために CPU コアも使っています。これは、 DMA read
よりも write combined 領域への PIO write のほうがずっと高速だから、と
いう分と、行列の引き算自体に CPU を使うというのがあります。
Core i7 の場合カード1枚なら 2 コア使えば性能は十分なので、
残りの2コアは使えます。これでは、 DGEMM のピーク性能は半分になりますが、
基本的に k が非常に小さいところの話なのでそもそも DGEMM の性能があまり
高くないところが時間の大半を占めており、2コアになることによる時間の増
加はあるにしてもそれほど大きなものではありません。
もっと問題なのは、主記憶のアクセス競合ですが、これはやってみないとわか
りません。アクセス競合については原理的には column-major のほうが有利で
すが、ブロックサイズが 2048 もあれば row-major でもそれほど問題にならな
いといいなあ、という感じです。
スレッドで書くとこれは大変そうですが、 omp parallel sections での並行
実行が有効に使えそうです。
原理的には、この方法によりGRAPE-DR を使わないホストでの計算は全て
GRAPE-DR を使う計算と並行に行うことができます。なので、理想的には
時間の内訳は以下のようになります。
GDR DGEMM 時間
計算時間
計算時間に隠蔽できない通信時間
K=2048 の時の時間
K<=1024 の時の時間
K=2048 の時の隠蔽できない通信は、行列の下半分を送るものであり N=34k な
ら 5GB 分です。もっと小さい場合は、 K=1024 で 1.25GB、 K=512 で
1.875GB、 K=256 で 2.1875 で、合計 10GB です。ちょっと楽観的ですが通信
に 2GB/s でるなら5秒ですから、例えば 1Tflops の実行性能をだすには計算
が23秒でよいことになり、DGEMM の性能が 1.2Tflops あればよい、というこ
とになります。
このように、ホストでの計算を隠蔽できることにはもうひとつ大きな意味があ
り、それは複数カードでも性能がでる可能性がある、ということです。ホスト
が計算していて GDR が休んでいる時間がたとえ15秒あれば、 GDR の計算が
30秒から速度が倍の 15 秒になっても、全体の計算速度は 1.5 倍にしかなり
ません。しかし、GDR が休んでいる時間がなければ、これはもともと 30秒だっ
たものがそのまま半分の 15秒になります。
普通は、通信速度がリミットになってそういううまい話はないのですが、
GRAPE-DR の場合には通信速度をリミットしているのは GDR カードの PICe イ
ンターフェース自体であり、そのためにカードが2枚あると通信は基本的に2倍
速くなります。隠蔽できない通信の部分も、ほとんどが2倍高速化されます。
このため、大きな性能向上が期待できます。
