137. 演算器率 (2017/5/1)
某作文をしていて、ふと「テクノロジーで規格化した、1チップあたりの演算
器の数」というのが重要な指標ではないかと思ったので計算してみました。
テクノロジーでの規格化は、以下のように計算します。
Figure 5: 規格化した浮動小数点演算器数の推移、Intel (黒、mainstream Xeon)、富士通
(赤、FX1,K,10,100)、NVIDIA (緑、Fermi, Kepler, Pascal)、
PEZY-SC,SC2,SC3, SW26010(青)について、規格化した浮動小数点演算器数を
1000でわったものをしめす。
チップあたりの倍精度演算器の数(FMAは2個と数える)*(デザインルール)^2
Intel、富士通、NVDIA、PEZY、Sunway で計算してみました。
Intel Xeon の進化
アーキテクチャ Nehalem SB IB HW BW SL
年 2009 2012 2014 2014 2016 2018?
デザインルール 45 32 22 22 14 14?
最大コア数 4 8 12 18 22 28?
コアあたり演算数 4 8 8 16 16 32?
演算器数 16 64 96 288 352 896
演算器率 32K 66K 46K 139K 68K 175K
表2 富士通メニーコアの進化
アーキテクチャ FX1 京/FX10 FX100 ポスト京
年 2008 2011 2015 ?
デザインルール 65 45/40 20 ?
コア数 4 8/16 32 ?
コアあたり演算数 4 8 16 ?
演算器数 16 64/128 512 ?
演算器率 68K 130K/200K 200K ?
表3 NVIDIA GPGPU の進化
アーキテクチャ Fermi Kepler Pascal Volta
年 2009 2012 2016 2018?
デザインルール 40 28 16 10/12?
1コア数 512 2496 1792 ?
コアあたり演算数 1 (2/3) 2 ?
演算器数 512 1664 3584 ?
演算器率 819K 1.3M 918K ?
表3 ヘテロジニアスメニーコア
アーキテクチャ PEZY-SC SW26010 SC2 SC3
年 2014 2016 2017 2019?
デザインルール 28 28? 16 7?
コア数 1024 256 2048 8192?
コアあたり演算数 2 8 2 2
演算器数 2048 2048 4096 16384?
演算器率 1.6M 1.6M 1.0M 800K?
もちろんダイサイズは同じではないのですが、まあ大体どれも 400-600mmsq
のレンジなのでその寄与は小さいです。
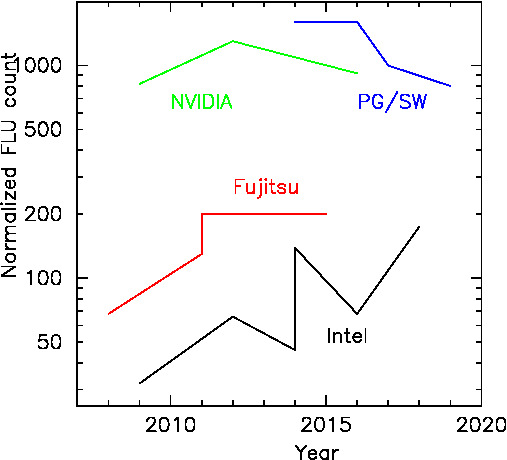
この、規格化した演算器の数が直接電力性能やピーク性能の差になってくるわ けで、GPU やヘテロジニアスメニーコアの優位性がどこかからくるか、という とここからであるわけです。これらに対して競争力をもつためのもっとも 正攻法なアプローチは、演算器率をさらにあげることであることがわかります。 とはいえ、これは容易なことではありません。
もっとも、ピーク性能はさておき、電力性能に限ると、NVIDIA と PEZY/Sunway の間にはテクノロジーが同等ならかなりの差があります。とはい え、非常に大きな差ともいいがたいかもしれません。追うものは圧倒的な優位 が必要なので、難しいところでです。汎用性を犠牲にしてでもこの演算器率をさら にあげる、というのがその方向のアプローチとしては可能なものであり、それ は我々が進めているものであるわけですが。