89. GPU と GRAPE-DR での行列乗算 (2010/11/14)
会津大学の中里さんが、GPU での DGEMM (倍精度行列乗算)の実装と性能評価 についての大変興味深い 論文を発表しました。これは、AMD の Cypress (HD58xx) GPU で、 倍精度行列乗算カーネルで理論ピークの 87% を達成した、という論文です。
GPGPU で倍精度計算、というと NVIDIA Fermi が本命と普通には思うわけです が、Fermi での DGEMM 実装は今のところドンガラ先生のグループが実現した 58%が公式 に発表があった中ではベストな性能(東工大のグループが 70% とか某氏が 80% とかの噂は流れていますが)なので、効率で 50%、性能では (Cypress のほうが 若干ピーク性能が高いので)さらに高いものになっています。
この2つの論文を比較してみると、行列乗算の実装の考え方は殆ど同じです。 どちらも

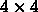 の行列を明示的に割り当てますが、
Fermi 用のコードでは演算カーネルは1要素に対する内積積算になって、
多数のスレッドを発行するという形で実質的に1つの物理プロセッサに
複数の行列要素を割り当てます。で、(私は良くわかってませんが多分)
スレッドのジオメトリの宣言をなんか上手くやると実効的にブロック化が
できるものと思われます。
の行列を明示的に割り当てますが、
Fermi 用のコードでは演算カーネルは1要素に対する内積積算になって、
多数のスレッドを発行するという形で実質的に1つの物理プロセッサに
複数の行列要素を割り当てます。で、(私は良くわかってませんが多分)
スレッドのジオメトリの宣言をなんか上手くやると実効的にブロック化が
できるものと思われます。
考え方が同じなので、動作のしかたや、性能のボトルネックになるところも原 理的には殆ど同じです。ボードの主記憶から一旦共有メモリに A, B の一部を ロードし、各プロセッサが共有メモリからそれぞれ必要なデータをロードする わけですが、共有メモリとプロセッサの間が十分ではないようです。
中里さんの論文によると、Cypress では単精度で 8x8 のブロッキングだと若 干不足、倍精度で 4x4 だとほぼぴったり、となります。Fermi の場合にも倍精度で 4x4 のブロッキングをすればバンド幅は足りるように思われるのですが、 上の Nath et al. ではスレッドブロック内のスレッド数が 256 となっていて、 物理プロセッサの数は32だと思われるので、実効的に 2x4 のブロッキングに なっているようです。このブロッキングサイズでは、Fermi の共有メモリバン ド幅が 1TB/s だとすると上限性能が 341Gflops となり、実際にでている性能 は 300 Gflops ちょっとなので大体そんなものかな?と思います。
ブロッキングサイズを 4x4 とか 4x8 にすればちゃんと性能がでそうな気がし ますが、レジスタ数とかキャッシュサイズや共有メモリサイズの制限で無理な のかもしれません。Fermi はまだでてきて日が浅いので、単純に実装が最適化 されてないだけという可能性もあります。
GRAPE-DR のアーキテクチャは見かけ上 GPU ととても良く似ていて、 特に Fermi と比べると、32個のプロセッサからなるブロックが16個(まあ、 GF100 だと14個ですが)ある、という具体的な数字まで同じです。が、 DGEMM 実装の考え方は全く違います。Fermi や Cypress の場合には、C の部 分行列をプロセッサレジスタにおいて、 A, B をボードのメモリから読み込み ながら計算する、という方式をとっていますが、GRAPE-DR では B をレジスタ (実際にはGRAPE-DR では「ローカルメモリ」といっている、プロセッサ毎に 256語あるメモリ)に格納します。格納した B のサイズはチップ全体では 512x256 です。実際の計算ループでは、長さ512のAを2行ロードし、計算して、 長さ256のCを2行出力します。B 行列の分割は、 512x256 を 32x256 の16個の ブロックに分割し、そのそれぞれを1つのプロセッサブロックが担当する、さ らに 32x256 を 32x8 の32個に分割し、それぞれをプロセッサ1つが担当、と なります。
なお、 GPU での DGEMM 実装はいわゆる内積型であり、それに対して GRAPE-DR での実装はいわゆる外積型に類似のものになっています。 GRAPE-DR の場合に外積型にしている理由は簡単で、内積型では性能がでないからです。 外積型では A をロードして C をだすのがメモリバンド幅を食うところですが、 内積型では A, B の両方をロードするのでロードのバンド幅が2倍必要です(そ のかわり、ストアにはバンド幅不要)。GPU の場合は主記憶のバンド幅は余っ ているので主記憶レベルではどちらでも多分大差ない(共有メモリのレベルで はどっちがいいか良くわかりません)わけですが、 GRAPE-DR の場合には、 メモリからの読み出しが 4GB/s しかなくて外積型でなければ性能がでません。 これは、Cray-1 のような、ロードパイプ1本、ストアパイプ1本のベクトル機で、 DAXPY 型のオペレーションでないとピーク性能がでなかったのと同じ事情です。
GRAPE-DR の方式の場合、PE1つは 32x8 のB を持ち、 2x32 のA と掛けて 8x2 のCをだしますが、実はこの C は部分和で、16個のプロセッサブロックにまた がって総和をとる必要があります。GRAPE-DR はそのようなプロセッサブロッ クにまたがった総和等の縮約演算のための専用ネットワークをチップ内部に もっていて、チップから外にデータを出力する時にはこのネットワークを通し ます。このため、レイテンシは若干ありますが、スループットには影響を与え ることなく総和演算が行えます。これは、ブロック間の総和には一旦メモリに 書き出すしかない GPU とは大きな違いで、バンド幅やレイテンシを無駄に増 やすことなくプロセッサブロック間でのタスク分割ができるわけです。
Fermi の場合、共有の2次キャッシュがあるので、原理的には類似のことができ なくもないはずです。例えば、全体で 256x256 (以下面倒なので、プロセッサ ブロックは 14 ではなくて16あるものとします。で、600MHz のクロックで2 演 算して614Gflops の性能があるとします)のB行列を持つと、A, C 1データ当り 512 演算するので、それぞれの入出力に必要なバンド幅は 9.6GB/s となりま す。16個のブロックからのデータの総和は多分この16倍くらいの場合幅があれ ばいいはずで、 160GB/s くらい、バンド幅としては主記憶でも何とかならな くもないくらいです。
GRAPE-DR の場合には総和を専用ネットワークで行ない、さらに求まった C を ボードの主記憶に書き戻すことなく直接に DMA でホストメモリに戻します。 また、そもそも C をホストから転送しないで、元々の C との加減算処理はホ スト側で行ないます。これにより、GRAPE-DR 側の主記憶の必要バンド幅、 PCIe の必要なバンド幅の双方を減らしています。
これについては、GPU 側に転送するべきかどうかは ホストの主記憶の速度と PCIe を通したDMA の実効的なスループットの比によっ て決まります。ホストが加減算する場合には結局 C については、カードから 入ってくる、ホストCPUがカードから入ってきたものと元々あったものを読み 出す、それらを加算して書き込む、と4語アクセスですが、GPU に転送する場 合には2語アクセスですむからです。Intel Core 2 で X38 チップセットとか の場合だと、GPU に転送したほうが有利だったと思われます。 Core i7 で X58 となると、CPU 側にメモリがあり、チップセット、PCIe を通したバンド 幅はメモリ自体のバンド幅よりもかなり低いため、 C を GPU に転送しないほ うが有利です。
また、 A については1つのプロセッサブロック内の32プロセッサで同一のもの を使いますが、これは共有メモリからブロードキャストすることができます。 このため、共有メモリ自体のバンド幅は高い必要がなく、500MHz 動作の場合 で共有メモリ1つのバンド幅は 4GB/s(デュアルポートなので実効的にはその倍) ですがこれで十分です。GPU の共有メモリは1つで 100GB/s 近いバンド幅があ りますが、行列乗算に関する限り本来そんな高いバンド幅は不要です。
GRAPE-DR の行列乗算カーネルの効率は、C の DMA による回収もいれた実際の DGEMM 関数で 90.3%、漸近性能では 94% となっており、Fermi はいうまでも なく、Cypress に比べても高くなっています。まあ、なっており、とえらそう に書いてますが、Top500, Green500 向けのチューニングを色々やってやっと 実現できたものではありますが。でも、チューニングは、殆ど GRAPE-DR 側で はなくて、ホスト側のプログラム等を修正して DMA で性能がでないところを 直す、とかいった性格のものです。
このように、 GRAPE-DR チップでは、プロセッサブロック間の縮約や、プロセッ サブロック内の放送をハードウェアで実現することで、 GPU に比べて桁で小 さいメモリバンド幅で高い実行効率を実現しています。が、これらのハードウェ アは別に行列乗算用につけたものでは全くなく、粒子間相互作用に代表される ような相互作用型の計算、つまり


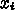 について並列に計算する、というもので、 i が違うもの
同士の相互作用や総和という概念がないため、実際のハードウェアではそれら
の実現はシリコンの面積からも消費電力からも非常にコストが高いものになっ
ているだけでなく、実行効率を落とす要因にもなっているわけです。
について並列に計算する、というもので、 i が違うもの
同士の相互作用や総和という概念がないため、実際のハードウェアではそれら
の実現はシリコンの面積からも消費電力からも非常にコストが高いものになっ
ているだけでなく、実行効率を落とす要因にもなっているわけです。