76. 濱田君・似鳥君 Gordon Bell C/P 賞 (2009/11/29)
タイミングが絶妙だったこともあり、新聞・ネットでは濱田君・似鳥君 Gordon Bell C/P 賞受賞が大きな話題になりました。SC09のサイトにある論文 は今年4月くらいの構成で、新聞等にでたのは11月に入って動くようになった 最新のデータなので数字が違います。11月の時点での構成は、 濱田君の神戸での発表資料にあるように Core i7 920 190 台の1台毎に GTX295 を2枚づつつけて、GT200チップとして760までもっていったという代物 で、295はカードあたり単精度 1.2Tflops(ckock 1242MHz だとして)、倍精度 100Gflops のはずなのでシステムトータルとしては単精度 912 Tflops、倍精 度76 Tflops ということになります。
やった計算は宇宙論的 N 体計算で、重力計算は直接計算ではなくて
計算量が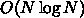 になる Barnes-Hut のツリー法です。なので、特に
GPU とホスト間の通信はかなり多く、 NVIDIA がデモで見せているような意味
がない計算というわけではありません。
になる Barnes-Hut のツリー法です。なので、特に
GPU とホスト間の通信はかなり多く、 NVIDIA がデモで見せているような意味
がない計算というわけではありません。
実現した速度もかなり impressive なもので、石山君(現在D3) が天文台の Cray XT4 用に実装した並列ツリーコードでは1コア・1秒当り 43k 粒子くらい を時間積分できるのに対して 1 ノードで 230万粒子と、えーと、コアとノー ドで比べると50倍、Cray XT4 の1ノードは4コアなのでノード同士で比べると 10倍強、となります。
まあ、GPU 4 チップも使ってるわけで、それを何と比べるべきかは良くわから ないです。価格としては1ノード20万円程度で構成したわけですから、GPU つ けなければ4コアのCPU使ったノードが10万以下で構成できることを考慮する と、、、というようなところもなくはありません。が、まあ、それでも、同じ 価格で3-5倍程度の性能を実現しているわけです。XT4 は 2.2GHz の Barcelona K10 なので、今なら安い 3GHz 程度の Phenom や Core i7 920 を 3 GHz くらいまで OC すると1.5倍くらい速くなって、値段当り 3-5倍が 2-3倍 になるとかそういう話もなくはありません。
と、それはともかく、GPU での、実用に使えるような重力多体計算スキーム、 具体的には独立時間刻みやツリー法で性能を出す、という話は前にも書いたよ うに世界中で色々な人がやっていますが、濱田君や似鳥君が世界をリードして いるといっても間違いではなく、特に似鳥君はケンブリッジ大学やアムステル ダム大学を始めとして世界のトップレベルの研究グループにコードやノウハウ を提供しています。つまり、リード、というのが、単に先に進んでいる、とい う意味だけではなく、実際に指導的位置にあるわけです。
濱田君、似鳥君ともに私の研究室出身でして、「出藍の誉れ」、という言葉は こういう時に使うものですね。
さて、上の濱田君の発表資料を見ると、GPU が動いている時間がそんなに大き くはないこと、特に、通信がかなりの時間を食っていることがわかります。発 表では、 Delegeted Allgatherv というものが言葉だけふれられていて、これ は Allgatherv でやっている通信が、ある程度以上のノード数では止まるので、 1ノードで動いている4プロセスのうち1つだけがノード間通信をするように変更 する、というものです。彼らが使った MSI X58 Pro-E の NIC がRealtek 8111C なので、まあ、あまり TCP セッションが多いと落ちるとかそういう問題 かもしれません。それはともかくとして、GbE を使っているわりにはまだ通信 時間がかかりすぎで、使っているスイッチに問題があるかもしれません。
ただ、このようなアクセラレータを使う計算や、そうでなくてもノード数が非 常に大きな並列計算の場合、通信のところはどうしても無視できなくなってき ます。この時に一般的に有効な手法は、可能なら計算と通信を並行に行うこと です。
例えば、 HPL の場合にも、ある程度これは行われていて、横方向の通信は メインな行列乗算をするのと並行にやる、というふうになっています。 HPL の場合には縦の通信もありますが、横が隠蔽できるので縦が速く終わるよ うに領域分割のトポロジを変えることができ、結構大きな効果があります。
ツリーコードの場合、特に宇宙論的計算では、通信量の大半が、自分がもって いる粒子への力を計算するのに必要な情報を他からもらってくる、というもの になります。濱田君・似鳥のコードでは非周期境界用のアルゴリズムを使って いて、全ノードが他の全ノードの情報を(遠くのほうは圧縮された情報になり ますが)必要としますが、石山君のコードでは TreePM という、遠距離成分は FFT を使う方法を使っています。この場合は、物理的にある程度以上離れたと ころとは通信の必要がありません。ただ、いずれにしても情報の殆どは近くの ノードからくるものであり、さらにその情報は境界近くの粒子への力の 計算以外では殆ど使いません。
ということで、今書きながら思いついたのは、この情報転送をプログレッシブ にやる、という方法です。これが正気の沙汰かどうかはともかく、プログレッ シブに、と書いただけで意味がわかる人にはわかるでしょう。要するに、表面 近くの粒子を別にすれば、そんなに細かい情報はいらないはずなので、まず 粗い情報を送ってもらってそれで十分な範囲の計算を進め、それと並行して 残りの情報を送ってもらい、それがきたら表面近くの粒子の処理をする、とい うふうにしよう、ということです。これによって、例えば通信の 90% 近く を後回しにするのは不可能ではないと思います。
このような、アルゴリズムに手を加えることで通信と計算の並行実行を実現す る、という手法は今後ますます重要になります。こういった手法の難しいとこ ろは、アプリケーション・アルゴリズム・ハードウェアをやる人が分離してい てはなかなか思い付けない、ということで、どうすればそういう研究者が育つ のか、というのが大きな課題です。