72. Stream Processing モデルと GRAPE-DR モデル (2009/8/4)
日経BPの英語版に nVidia の Bill Dally の講演概要がでてます。 日本語記事はユーザー登録がいるのかな?
ここで強調されているのは要するに Stream Computing で、 Dally 先生がま だ Stanford の教授だったころにやっていた Merrimac です。これはどういう 話かというと、数式っぽく書くなら要するに

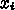 について並列に計算する、というものです。
まあ、ベクトルレジスタが大きなベクトルプロセッサと全く同じですが、
それに何か違うものであるかのような名前をつけて人を騙しているわけですね。
ベクトルプロセッサの場合には、そうはいってもレジスタ数があまり多くなく、
またプログラミングスタイルの問題もあってあまりレジスタがメモリバンド幅
要求を小さくすることに貢献できていないというのは既に何度も議論した通り
ですが、 Stream Computing のモデルの場合にはベクトルプロセッサ並のメ
モリバンド幅は諦めて、例えばメモリアクセス1語につき100演算くらいはして
欲しいな、とするわけです。これにより、ベクトルプロセッサや、あるいはメ
インストリームのマイクロプロセッサに比べても、 B/F を落としています。
例えば Merrimac の設計が書いてある論文では、 128Gflops に対して 20GB/s
のメモリバンド幅です。まあ、最近の普通の GPU と同程度です。
について並列に計算する、というものです。
まあ、ベクトルレジスタが大きなベクトルプロセッサと全く同じですが、
それに何か違うものであるかのような名前をつけて人を騙しているわけですね。
ベクトルプロセッサの場合には、そうはいってもレジスタ数があまり多くなく、
またプログラミングスタイルの問題もあってあまりレジスタがメモリバンド幅
要求を小さくすることに貢献できていないというのは既に何度も議論した通り
ですが、 Stream Computing のモデルの場合にはベクトルプロセッサ並のメ
モリバンド幅は諦めて、例えばメモリアクセス1語につき100演算くらいはして
欲しいな、とするわけです。これにより、ベクトルプロセッサや、あるいはメ
インストリームのマイクロプロセッサに比べても、 B/F を落としています。
例えば Merrimac の設計が書いてある論文では、 128Gflops に対して 20GB/s
のメモリバンド幅です。まあ、最近の普通の GPU と同程度です。
問題は、この程度の B/F (0.1 程度)でも、 GPU をみればわかるように実現す るのは容易ではない、ということです。例えば GRAPE-DR の場合には 256Gflops に対して 4GB/s と、 Merrimac に比べるとさらに1桁 B/F を落とし ていますが、それでもボード設計は容易ではありませんし DRAM のコストも馬 鹿になりません。2003年の Merrimac の論文を見ると 20GB/s を1つ1ドルの DRAM チップ 16 個で実現するとかいうおちゃらけたことが書いてありますが、 そんなことは今でも難しいわけです。
しかし、この Stream computing のモデルを 2015 年まで外挿した結果、 Dally 先生は 11nm プロセスになってもピーク性能(単精度?) 20Tflops に対 してメモリバンド幅は 1.2TB/s と、Merrimac とあまり変わらない B/F を想 定しています。貫通電極でも使えば実現できますが、GDDR のような技術、あ るいは XDR のようなシリアル技術をつかってもピン数、消費電力的には無理 な気がします。
AMD から分社した GlobalFoundries では 22nm からDRAM 接続用に TSV (貫通 電極)を、という話もありますが、これは汎用 DRAM ではなく IBM のプロセス での SOI 基板用 eDRAM との接続です。そうすると、 GPU といえどもメイン メモリ全部に使うのは無理で、スクラッチエリア的な小サイズ高速メモリに、 となります。そうすると、 GPU のレジスタ-ローカルメモリ-オンボードメモ リの3階層にもう一つ加わるわけで、 Stream computing 的なモデルでは上手 く使うことは困難です。
GRAPE-DR では、そういう観点からすると計算モデルが実は違います。 GRAPE-DR でのモデルは

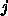 についての和、という概念がはいってきます。
そうすると、
についての和、という概念がはいってきます。
そうすると、 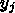 の数に反比例してメモリバンド幅を減らすことが可能に
なるわけです。和の演算をハードウェアで実現するためにチップ内のプロセッ
サ配置を階層化し、reduction tree とかももたせています。上のモデルは
計算量が
の数に反比例してメモリバンド幅を減らすことが可能に
なるわけです。和の演算をハードウェアで実現するためにチップ内のプロセッ
サ配置を階層化し、reduction tree とかももたせています。上のモデルは
計算量が 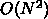 になるものにしか適用できないようにみえますが、
実際には
になるものにしか適用できないようにみえますが、
実際には 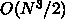 である行列乗算とか、
である行列乗算とか、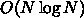 になるよう
な様々なアルゴリズムにも上手く適用でき、 Stream computing のモデルに比
べて大きくメモリバンド幅要求を下げることができます。我々の見積もりでは、
結構多くのアプリケーションについて、次世代以降のチップではシリコンの
1/4 から 1/2 程度を eDRAM に当てることで、オンボードメモリを省略してホ
スト計算機の主記憶に頼ることで十分なバンド幅を得ることができます。
になるよう
な様々なアルゴリズムにも上手く適用でき、 Stream computing のモデルに比
べて大きくメモリバンド幅要求を下げることができます。我々の見積もりでは、
結構多くのアプリケーションについて、次世代以降のチップではシリコンの
1/4 から 1/2 程度を eDRAM に当てることで、オンボードメモリを省略してホ
スト計算機の主記憶に頼ることで十分なバンド幅を得ることができます。
このような、基本的な思想の違いのために、同じメニーコア的プロセッサといっ ても GPGPU と GRAPE-DR ではトランジスタ利用効率や電力あたり性能が大き く違い、GRAPE-DR は 90nm デザインでも 40nm の GPU と同等の性能、となっているわけ です。まあ、同等では商売にならない、というのは問題で、次世代の開発も必 要ですが。完全に専用化した GRAPE-6 の場合には、250nm のプロセスのチッ プで電力性能比では 45nm の x86 や GPGPU よりまだよい、という状態なわけ で、もうちょっとそっちに近付けるような、効率の向上が重要です。