69. GRAPE-DR の HPL 実効性能 (2009/5/9書きかけ)
GRAPE-DR も予算は今年3月でおわって、色々性能の数字とかもでてないといけ
ないのですが諸般の事情でまだでていません。というか、現在まだ「調整中」
というところです。
ピーク性能が GRAPE-6 に比べてそんな上がってるわけではないので、天文シミュ
レーションで理論ピーク(というか、重力計算ループの性能)の例えば半分程度
の性能を出すのはそれほど難しいわけではなくて、実際にボード単体ではでて
いるのですが、折角 HPC Linpack を実行できるように作ったのでこれについ
てまあまあの数字をだそう、という作業をしています。
(というわけで、 2009/5/7の段階ではまだ実効性能の数字はこの文書を最後まで読んでもでてきません。数字はもうちょっとお待ちを)
6月の Top 500 の発表に間に合うかどうかは厳しいところですが、それはとも
かく今月中には一応動いた、という数字は出せると思っています。
で、今回の数字については、結構 Top500 の歴史に残るほど「効率」は低いも
のになる見込みです。これは、
来年くらいには 4GB DDR3 のモジュールも安くなると思うので、なんらかの形
で 24GB とか48GB まで増強すれば効率はかなり上がることになります。
HPC Linpack の性能は、基本的には以下のように書けます。
現在動作している GRAPE-DR のクロック 380MHz でも、カードを2枚つけた時
演算速度は 1.5Tflops にもなり、ホストの Core i7 920 の 40倍近くになり
ます。メモリバンド幅は連続アクセスで 16GB/s 程度、つまり2G語/秒程度で
すから、演算速度とはほぼ 1000倍の差が連続アクセスでもあるわけです。と
ころが、HPL の場合、メモリアクセスは連続にはなりません。というのは、
並列版になると、これらは通信にもなるのでもうちょっと面倒ですが、本質的
には議論は変わりません。まず、計算量やメモリアクセス量の比は、1ノード当
りの行列サイズで決まる、というのは落ち着いて計算すればわかります。
現在の通常の HPL の実装・実行では、行列は列方向が連続になるようにメモリ
に格納します。この結果、ピボット探索を高速化し、行交換は速度が落ちても
やむをえない、としているわけです。1ノードの場合には、これはそんなに悪い
選択ではありません。1列毎に入れ替えをする形のループにすることで、ある程
度までメモリアクセスの局所性を保つことができるからです。但し、並列版で
は普通に書くと行方向のアクセスになるので大きな間隔でのストライドアクセ
スになって性能がかなり低下します。
現代の計算機でのストライドアクセスの性能低下の理由は、キャッシュライン
の一部しか使われないことと、 TLB ミスです。 TLB ミスは 2MB とか 4MB の
いわゆる Huge TLB を使うことで抑えることができますが、キャッシュライン
の一部しか使われない、というのはメモリ格納オーダーを変えるしかありませ
ん。最近の機械はラインサイズが 64バイトになっていて結構大きいので、TLB
ミスがなくても不連続アクセスの速度は 1/8 まで落ちることになります。
格納オーダーを変えるのは色々考え方があって、一つはペアノ曲線やモートン
オーダーを使った再帰的な配置にすることです。ペアノ曲線の場合には大雑把
にいって、縦方向のアクセスでも横方向のアクセスでも、半分が隣接、1/4 が
2倍離れ、、、、というような感じになるので、どちら方向でも性能低下か 3
倍程度に抑えられるはずです。実際にこのようなアクセス方式で Level 3
BLAS を自動チューニングする、といった研究もあります。
しかし、そうはいってもペアノ曲線とかではデータがどこにあるのかすぐには
わからない(HPL 専用プロセッサを作るならアドレス変換をハードウェアでや
るといった可能性もあります。これはビットシャッフルだけなので本当は時間
かからないので)ので、もうちょっと単純な方式を使いたいところです。例え
ば、サイズ2とか4の短いベクトル単位で行方向に格納し、それを列方向に格納
する、といった形の行列を考えてみます。
この場合には、サイズを m とすると最大値探索の速度は単純な列方向格納の場
合の 1/m になり、行交換の速度は m 倍になります。列パネル変形は微妙で、
上手く書けばあまり変わらないはずです。最大値探索と行交換のどっちが元々
大変か、というと、最大値探索は行列全体の半分を read するだけですが、行
交換はやはり半分について、交換なので 2回 read, 2 回 store となり形式的
には4倍のアクセスになります。実際にはキャッシュヒットがどれだけか、とい
うのがあるので4倍にはならないですが、それなりに多いはずです。
と思うと、元々行方向に格納しておけばよいのではないかという気もします。
が、 HPL のコードは入力行列については必ず列方向格納をする (分解後の L,
U については選択できる)ので、これは HPL を全部書き直さないと実験できま
せん。
何故 HPL のコードが列方向格納になっているかというと、これはおそらく歴史
的な理由ではないかと思います。つまり、 Linpack benchmark というと
100x100 とか 1000x1000 であった時代、つまり、シングルプロセッサのスカラ
機やベクトル機がベンチマークの対象であった時代には、使われていたアルゴ
リズムもせいぜい縦ブロックガウス消去法くらいなので、基本的に演算量の多
い操作ではベクトル化の方向が縦(列)方向になります。なので、列方向格納で
ないと性能的には全く話にならないわけです。
しかし、現代的なアルゴリズムでは、そもそも演算量の多いところは殆ど全て
行列乗算に置き換わっているので、演算ではないピボット操作とか行入れ替え
が究極的には問題になるはずです。なので、これらの時間を最小化するような
データ配置が望ましいです。もちろん、実際には、そんなところが問題になる
ところまで行列乗算の性能を引き上げてしまったのはアクセラレータ付きシス
テムの中でも GRAPE-DR が初めてであり、このために従来のシステムでは全く
問題にならなかったところの実行時間が問題になってきているわけです。
ずっと上で述べたように、このようなところの実行時間が問題になるもう
ひとつの理由は単純にホスト計算機のメインメモリ容量が不足していることで
すが、やはり、根本的な問題はこれまでの他のシステムでの経験の蓄積がない
ところまで行列乗算を高速化した、ということ自体にあり、このために
従来なされてきたのとは違う部分の高速化が必要になっているわけです。
というわけで、現在のところ DGEMM 本体についてはピーク性能の 75%以上が
でるところまでチューニングできていますが、 HPC Linpack についてはもう
ちょっとお待ちを、、、という状況です。
DGEMM 以外のもの、としてピボット探索と行交換をあげましたが、実際にはこ
れらが全てではもちろんありません。一つのポイントは、 GRAPE-DR では(実は、
ClearSpeed 等のアクセラレータや、また GPU を使う場合でも事情は同じです
が)、 DGEMM が速くなるための条件があるのです。それは、行列の幅が大きい
ことです。行列乗算を式で書くと
例えば ClearSpeed CSX600 の場合、
CSXL User Guide for 3.1によれば性能が、大体
LINPACK ででてくる DGEMM では、 M, N の値はホスト主記憶にはいる行列の大
きさできまるのですが、 K は実行時に指定できるパラメータです。従って、
アクセラレータで性能を出すには K を可能な限り大きくすることが望ましい
わけです。CSX600 の推奨値は 1152 であり、GRAPE-DR の場合は 2048 で
す。しかし、ここまで K を大きくすると、
ClearSpeed のようにホストに比べてそもそも速くないとか、あるいは
RoadRunner のように計算全体を実は「アクセラレータ」側でするのでなく、
非常に速いアクセラレータを細いバンド幅で PC につなぎ、さらにメモリも小
さい(N と K の比を大きくできない)、時にこの部分は問題になります。現在
の GRAPE-DR のホストでは、カード2枚つけると速度比が40程度、2を底とする
対数は5 です。これに対して N/K は 15 前後なので、結構大きな影響がある
ことになります。メモリが 32GB もあればこの影響は半分になります。
さらに、まだ DGEMM で表現できていない部分があります。これは DTRSM と呼
ばれる、3角行列を解くのを多数の入力について行う、というもので、行列で
書くと
さて、アクセラレータの場合には、なるべく行列サイズを大きくしたいわけで
すが、その観点からすると単純なブロック化は好ましくありません。元々の
DTRSM に渡された行列が大きくても、ブロック化アルゴリズムで指定した小さ
なサイズの行列が DGEMM に渡ることになるからです。
ここで、真っ当な方法で可能な限り行列サイズを大きくするには、再帰的な処
理をすることになります。つまり、まず下半分を処理してからそれを上半分に
適用する、という形にして、さらに下半分と上半分をそれぞれまた半分に分け
て同じことを繰り返すわけです。このやり方は、上に述べたパネル分解への再
帰的な DGEMM 適用と同じで、計算時間が GRAPE-DR の速度とホスト計算機の速
度の比の対数で増えてしまう、という問題があります。初めから DGEMM を使う
ほうは、ピボット交換が関係するのであまり他に良い方法がないのですが、
DTRSM のほうは単純に3角行列の処理で、別に面倒なことはないのでもっとよい
方法があります。それは、 A の逆行列を作ってからそれを B に掛けることで、
一気にX を求める、という方法です。
この方法では、DGEMM に渡る行列サイズは元の行列と同じなので、もっとも高
い効率がでます。しかし、3角行列の逆行列にして、それをなにも考えずに
DGEMM ルーチンに渡すので計算量が2倍になるのが問題です。まあ、3角行列の
逆行列はやはり3角行列なので、それ向けの DGEMM を作ればよいわけですが、
GRAPE-DR の場合にはどうせ通信リミットなのでがんばって演算量を減らしても
あまり意味はありません。この方法の場合、再帰の場合にでてくる 5 とかのファ
クターが2になるので、かなり効果的です。この方法は演算量が増えるので
普通の計算機ではおそらく使われないのか、文献では報告がない方法ですので、
一応新しいアルゴリズム、ということになります。
但し、最初に逆行列を求める必要があり、これが新たなオーバーヘッドになり
ます。この部分は、入力行列が単位行列なので計算しなくてもよいところを減
らすと計算量が単純にDTRSM を使う場合の 1/3 になり、さらにその形の処理
に対して再帰的アルゴリズムを使うことで殆どを DGEMM に置き換えることが
できます。ブロックサイズが小さいのであまり速度はでないですが、そもそも
計算量が非常に減っているのであまり問題ではありません。
結局、並列化によってでてくる通信を別にしても、GRAPE-DR で HPL を実行す
ると、普通の計算機や、遅いアクセラレータでは問題にならなかった
ホストにお金をもうちょっと使えて、32GB とか 48GB のメモリをつければそ
れだけで効率が 70% 程度にはあがるのですが、、、
と、こういった文章をだらだら書くのは、自分の頭の中を整理するためでもあ
るというかそれが主なのですが、書いていると実際によりましなやり方を色々
思いつくわけです。
ピボット探索と行交換の速度を両立させ、な
おかつ BLAS 等の普通のライブラリとの親和性を犠牲にしない方法としては以
下のようなものが考えられます。
最初に書いたように現在の HPL は列優先の格納しかできないので、このため
にプログラムを全部書き直して実験する必要があります。これは 6月の Top
500 には間に合わないので、次回に御期待を、となってしまいます。
という3つの理由があります。元々の設計思想というのは、GRAPE-DR の場合天
文アプリケーションを含む様々な応用プログラムで高い実効性能を出す、とい
うのが目的で、これは必要な性能要求が比較的演算能力に偏っていてホストの
メモリ量やネットワークのバンド幅への依存が小さいものです。現在の
GRAPE-DR のホスト計算機の構成は、Core i7 (920) に 12GB メモリ、ネット
ワークは x4 DDR IB というものですが、HPL を十分に高い効率で動かすには
が若干不足します。元々大雑把なみつもりでは 20Gb/s のネットワークだと
32GB 程度のメモリが必要なのですが、メモリの値段はともかくそんな量のメモ
リをつけられるマザーボードやそれにつく CPU はやたら高い、というのが問題
です。開発を始めた5年前には、10GbE がもうちょっと安く、少なくとも IB よ
りも安くなって、主記憶もデスクトップマザーで 16GB、2ソケットのサーバー
用なら 32GB は安価につくと期待したのですが、それが2008年度内に、という
のは少しみつもりが甘かったと思います。まあ、その、実はNehalem EP で
Dual Tylersburg の SuperMicro X8DAH+ だと値段的にもぎりぎりで、性能も問
題ないのですが、これは 2008年度の予算で買うのは不可能だったのが問題です。
AMD だと Shanghai での DP マザーではどうか、となりますが、これは DDR2
で、800 までなのでメモリバンド幅がちょっと厳しいところです。例えば
Thunder n6650W や ASUS KFN32-D SLI のような nForce 3600+3050 なものだと
PCIe Gen1 で我慢するならこちらの要求仕様を満たさないわけでもないのです
が、できれば Gen2 16 レーンが2枚使えるマザーが欲しかった、ということも
あります。ということで、今回使ったマザーは P6T6 WS Revolution で、DDR3
で4GB のメモリはまだ買える値段ではないので 2GB x 6 で 12GB となっていま
す。この、 12GB しかないことが今回は大きく性能をリミットしています。
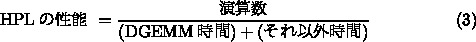
が基本的に同じ量あるので、配列の格納をどっち順にしてもどちらかは不連続
アクセスになるからです。普通の計算機では、DGEMM の速度とメモリアクセス
の速度の差はせいぜい20倍なので、行列サイズが 1000 から 10000 あれば、
不連続アクセスで速度がさらに 1/10 -1/100 程度まで落ちてもこれらの速度
は問題にならないのですが、GRAPE-DR の場合にはこれが問題になるわけです。
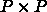 のプロセスグリッドを考えると、行列サイズは
のプロセスグリッドを考えると、行列サイズは 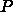 倍、DGEMM
の速度は
倍、DGEMM
の速度は 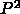 倍、ピボット探索や行交換の速度は
倍、ピボット探索や行交換の速度は 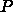 倍だからです。
倍だからです。

for(j=0;j<N;j++){
for(i=0;i<M;i++){
C[j][i]=0;
for(p=0;p<K;p++){
C[j][i]+= A[p][i]*B[j][p];
}
}
}
この形で実行したのでは性能がでないので色々するわけですが、アクセラレー
タの場合には計算するには基本的に行列 A,B をホスト計算機が I/O バス経
由でアクセラレータボードに送り、アクセラレータボードが計算して、計算結
果を返す、という手順が発生します。
行列サイズ 速度 (Gflops)
1000 8
2000 28
3000 42
4000 52
5000 56
という感じです。行列サイズが 2000 の時には、演算数が全部で 16G になり
ますから、 0.6秒くらいで計算がおわっています。データ転送の総量は
96MB ですから、この時に計算と通信がほぼ半々だったとすると、データ転送
の実効速度は 300MB/s 程度と推測されます。 PCI-X を使ってる割には遅い気
がします、、、と、それはともかく、通信量に比べて演算量が多い必要がある、
ということです。
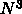 ではない処理、といって
いたところが馬鹿にならなくなります。それは、実はその部分の処理の中に
計算量が
ではない処理、といって
いたところが馬鹿にならなくなります。それは、実はその部分の処理の中に
計算量が 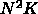 に比例するところがあるからです。これは、パネル分解と
呼ばれる、ブロックサイズまでのガウス消去をするところです。もっとも、その部分に
ついても再帰的にブロックサイズを小さくしていくことで、殆どの計算量を
DGEMM に回す方法が知られていますが、この場合にはもちろん K が小さくな
るので性能は落ちます。とはいえ、この部分は大したことはない、というのが
理論的にはわかります。 GRAPE-DR のように性能が K に単純に比例するシス
テムの場合、
に比例するところがあるからです。これは、パネル分解と
呼ばれる、ブロックサイズまでのガウス消去をするところです。もっとも、その部分に
ついても再帰的にブロックサイズを小さくしていくことで、殆どの計算量を
DGEMM に回す方法が知られていますが、この場合にはもちろん K が小さくな
るので性能は落ちます。とはいえ、この部分は大したことはない、というのが
理論的にはわかります。 GRAPE-DR のように性能が K に単純に比例するシス
テムの場合、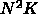 の部分の時間に再帰の深さに比例する係数がつくこと
になります。このため、再帰が無限に深いと計算時間が発散しますが、実際に
はホスト CPU で計算したほうが速くなるところで再帰を止めるので、ここの
部分の係数はホスト計算機と GRAPE-DR の速度比の2を底とする対数程度に
なるわけです。
の部分の時間に再帰の深さに比例する係数がつくこと
になります。このため、再帰が無限に深いと計算時間が発散しますが、実際に
はホスト CPU で計算したほうが速くなるところで再帰を止めるので、ここの
部分の係数はホスト計算機と GRAPE-DR の速度比の2を底とする対数程度に
なるわけです。

for(j=0;j<M;j++){
for(i=K-1;i>=0;i--){
for(p=K-1;p>i;p--){
B[j][i] -= A[p][i]*B[j][p];
}
}
}
というような感じのことをするわけです。普通の計算機でも、この形のままで
性能を出すのは面倒なので、最近は GEMM-BASED と言われる、なるべく行列乗
算の形の演算を括り出してそこには最適化された DGEMM ルーチンを使う、と
いうやり方が多いようです。これは、上のコードでいうとまず j のループと
i のループの順番を入れ替えて、全部の列をまとめて処理するようにします。
さらに、i, p のループをブロック化して、何行か処理したら、それの上のほ
うへの影響の処理はまとめて、という形にするとそれが行列乗算になっている
ので DGEMM を使う形に書き換えるわけです。
が問題になるわけです。上にみたように、 DTRSM についてはあまり問題にな
らないところまで(といっても、計算量が2倍になっているので K/2N の程度、
つまり3-5% 程度の効率低下にはなります)下げることができますが、パネル分
解はその数倍、ピボット探索や行交換もそれなりに、、、となります。総合的
には、現在のホストでは、単一ノードの HPL で効率 50% は結構大変、という
ところです。
ブロックサイズがキャッシュラインの幅程度あり、さらに TLB ミスがあまり
起きないような large page が使われていれば、転置のオペレーション自体に
もほぼメモリバンド幅のピークがでます。特に、列方向に格納する行列は小さ
いので、L3 にははいることになり、この部分の変形の速度はメモリアクセス
速度でリミットされなくなり、ほぼ無視できる計算になります。そうすると、
キャッシュラインサイズ単位での読み出しや書き込みになる転置と、連続アク
セスになる行交換だけが速度を決めることになり、結構大きな速度改善が可能
なはずです。