50. 次世代スーパーコンピュータ概念設計評価報告書(2007/6/27- 2007/7/9追記)
次世代スーパーコンピュータ概念設計評価作業部会の報告書が 6/13 にでました。
安藤さ んのところ、 マイコミジャーナルのはこっちに概要の紹介と解釈がありますが、 要するに、評価報告はあるけど評価されるものがなんだかわからないので良く わからない、という話です。
まあ、とはいえ、行間を読んで見るとなかなか面白いレポートで、例えば p13 に
従来のベクトル型の課題を解決する新規のアーキテクチャによる CPU を搭 載するベクトル部なる記述があります。これは、つまり、地球シミュレータの
- 2演算に対して1語 (Byte/flops で 4) の高いメモリバンド幅
- 8プロセッサ程度での共有メモリ
-
単段(かどうか知らないけど)クロスバー
特に光インタコネクト技術は、少なくともシステムワイドなネットワーク
技術として発展する可能性が高い
という評価がでています。素直にシステムワイドネットワークに光を使うシス
テムならこんな妙な表現にはならないので、これは少なくとも評価のためにで
てきた案ではシステムワイドでないところに光が使われていたという意味にな
るでしょう。つまり、メモリ-プロセッサ間は光であるということです。とい
うことは、複数プロセッサでのメモリ共有は従来の通りであり、おそらく他の
2つ、つまり高いメモリバンド幅とクロスバーは断念した設計になっているの
でしょう。
ネットワークはまあ大した問題ではなくて、問題はどこまでメモリバンド幅を 落としたかです。 SX-8R で SX-8 や地球シミュレータの半分に落としてきた わけですから、新規アーキテクチャという以上もっと落としたと思われます。 つまり、
SX-8 1語/2演算 (4 B/f) SX-8R 1語/4演算 (2 B/f) 次世代 1語/8演算以下 (1 B/f 以下)となるわけです。この、 1 B/f というのはかなりすさまじい数字で、 最初の Pentium 4 は 3.4Gflops (1.7GHzのもので) に対して3.2GB/s ものメ モリバンド幅がありましたから、これとほぼ同じです。つまり、 Pentium 4 並のものに「ベクトル」という名前をつけてるわけです。まあ、例えば STREAM で SX は 64GB/s と本当にこのバンド幅がでますが Pentium 4 あたり だとせいぜい 6 割なので、倍くらいは違う、と思うべきかもしれません。
ちなみに Cray Blackwidow では load は 2B/f、 store が 1B/f 程度のよう ですから、実は SX-8R と大差ありません。
なお、48 でも書いたように、ピーク性能に対する実効性 能が高いことは良いことである、という、私の考えでは誤解である考え方があ るわけですが、そのような考え方の問題点が明確に現われているグラフが たるさんのパソコ ンフィールドにありました。興味深いものなのですみませんが紹介させ ていただきます。
図は「ベクトルとスカラのクロスポイント」というもので、要するに価格性能 比はメモリバンド幅要求が低いところでは PC が有利、高いところでは地球シ ミュレータのようなベクトル機が有利、というものです。
実際に数字をいれてみればすぐにわかりますが、この 図は定性的に正 しくありません。地球シミュレータは 32GB/s のメモリバンド幅が 1200万円、 つまり 1GB/s が 38万円だったわけです。これを PC と比べると、2002年なの でまだ Pentium 4 ですが、これは実効 2GB/s のものが20万円で買うことがで きましたから、1GB/s が 10万、つまり
メモリバンド幅が性能を決めるアプリケーションでも P4 のほうが ES の 4倍価格性能比が良いのです。まあ、これが Cray XT3 のような並列機になると1ソケット100万程度 ですから、メモリバンド幅あたりの値段は当時 XT3 があったとすれば ES と 同等です。現時点では Opteron のソケット当りのメモリバンド幅は P4 のほぼ 4倍 になっています。SX-8R は ES の2倍しかないので、相対的には悪くなってい て、アプリケーションの B/f がどんな数字でも SX-8R のほうが XT3 より価 格性能比が悪い、という状態です。
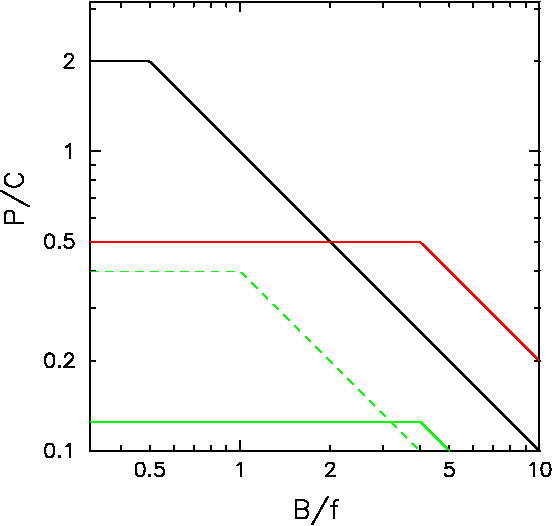
Figure 1: アプリケーションの要求するバイト/フロップス値 (B/f、横軸)と価格性能比 (P/C、 縦軸)の関係。黒は普通の PC を1ノード100万で買った時の値。赤はメモリバンド幅当りの価格が PC より安い、現実には存在しないベクトルプロセッサ、緑は現実のベクトル プロセッサ。
{kind=link}