さて、計算機開発は失敗するのが普通か?という問題です。
私の考えは、基本的に 1 チップマイクロプロセッサが完全にパイプライン化
した乗算器を持ち、それまでより高速だったベクトルプロセッサよりも高いク
ロック、演算速度を実現した時点で、計算機開発で成功することは極めて困難
になった、というものです。
これは要するに、 COTS クラスタに価格性能比で勝つのは難しい、というだけ
のことです。Intel のマイクロプロセッサの累計生産数は 20億に到達しよう
としています。これは、年に2-3億個ということです。それだけの生産量を背
景に、他の(IBMとAMD以外の)半導体メーカーにはとても不可能な高クロックで
動作する、膨大な開発費がかかっている製品を、恐ろしく安い価格で売ってい
るわけです。
この状況のために、Intel のマイクロプロセッサ単体の性能よりも高い性能が
必要な領域では、Intel の(まあ AMD でも大して変わらないですが)マイクロ
プロセッサを大量に並列に使う、というアプローチに比べて価格性能比を上げ
ることは困難になっています。性能が低くていいほうでは、もっと簡単なプロ
セッサを作ることで、性能に比例しては値段が下がらなくても安くなればいい
わけなので、現状では例えば携帯電話に x86 という話にはまだなっていませ
ん。
GRAPE の話をすると、1993 年に GRAPE-4 のプロセッサチップを泰地君が作っ
た時には、初期コストが 2500万円で量産コストが(ダイだけですが)1チップ1
万を切ってました。チップは 14mm角で 10万ゲートで、まあ、そこそこ先端技
術です。クロックは設計最悪値が33MHz で、典型的には 40MHz くらいで動作
しました。これは、当時のマイクロプロセッサに比べてそんなに悪い値ではあ
りません。最小の Pentium は 66MHz でしたし、当時の RISC プロセッサも
既に 200MHz に近かった DEC Alpha を例外として、他はその程度でした。
その後、 GRAPE では概ねいわゆる CMOS スケーリング則にそって動作速度を
あげてきました。つまり、プロセスルールにほぼ比例してサイクルタイムが短
くなってきました。 GRAPE-6 は GRAPE-4 に比べてプロセスルールが 1/4 に
なったのにクロックは 3 倍弱ですが、これは電源周りの設計ミスもあっての
話です。 GRAPE-DR では GRAPE-4 に比べてるとプロセスルールが 1/11、クロッ
ク周波数が 15倍となっています。
ところが、 Intel マイクロプロセッサのクロック速度の上昇は、
CMOS スケーリング則にあっていません。 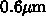 の Pentium で
90MHz程度だったのに、 90nm の Pentium 4 や Xeon で 3.8GHz となっていま
す。プロセスルールが 1/7 にしかなっていないのに、クロックは 40倍以上に
なったわけです。 もちろん、そうはいっても
の Pentium で
90MHz程度だったのに、 90nm の Pentium 4 や Xeon で 3.8GHz となっていま
す。プロセスルールが 1/7 にしかなっていないのに、クロックは 40倍以上に
なったわけです。 もちろん、そうはいっても 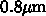 で200MHz
を達成していた Alpha に比べるなら、 1/9 で 18倍となってまあそんなにず
れてはいません。
で200MHz
を達成していた Alpha に比べるなら、 1/9 で 18倍となってまあそんなにず
れてはいません。
これは、 Intel はアーキテクチャをいじりまわして高いクロックで動作可能
なものにすることで、CMOS スケーリング則以上の動作速度向上を実現した、
ということです。IBM、Sun 等の、汎用計算機用プロセッサを作っているとこ
ろも、同様な努力をしてクロックをあげてきています。これは、論理設計から
プロセスチューニングまでの、全レベルで努力をすることで成り立っています。
もっとも、 Intel が Pentium より後の世代で高いクロック周波数を実現でき
た要因はもう1つあって、それは Pentium Pro 以降は x86 命令を実行時(命令
フェッチの後)に RISC 的命令に変換して、その変換したものをスケジュール、
実行するアーキテクチャに切換えたことです。このアーキテクチャ自身は
Intel の発明ではなかったようですが、ともかくこの方法によって x86 プロ
セッサは同時期の RISC プロセッサに対して性能的に優位に立てるようになり
ました。R4000 や SPARC のような、元々の RISC のアイディアそのままの
プロセッサは、バイナリ互換性を保とうとすると CMOS スケーリング以上に性
能を上げる余地があまりありません。まあ、それでも Out-of-order 実行をと
か色々するわけですが、なかなか大変です。
IBM や Sun がどうやってるかはともかくとして、大学や国の研究所でどうか?
ということを考えてみます。 15年前までなら、1000万円もあれば結構大きな
マイクロプロセッサを作ってみることができました。もちろん、これはその当
時の最高速のベクトルプロセッサにはクロックサイクルでは及ばないものでし
たが、同じく1チップのマイクロプロセッサとはそれほど差がありませんでし
た。そのようなわけで Stanford MIPS プロジェクトや Berkeley RISC プロジェ
クトのような大学の研究で高速な RISC プロセッサを作ることができたわけで
す。
もちろん、これは現在になって過去を振り返るからいえることで、25年前に前
にを作ろうという時に、8086 プロセッサをみて同じようなものを作ろうとし
ていたのでは駄目です。しかし、この時には CDC 6600 や 7600 といったお手
本があったのも確かです。 しかし、それ以前の問題として、普通のゲートア
レイやセルベースの LSI で実現できる動作速度が、商用の大量生産されてい
たマイクロプロセッサの動作速度とあまり変わらなかった、少なくとも桁では
変わらなかった、という状況がありました。このため、アーキテクチャで例え
ば2倍とか、あるいは 50% とかでも性能を改善できたものは少なくとも研究レ
ベルとして「成功」とみなすことができました。
ところが、現在はもしも頑張って大学でプロセッサを作ったとして、億単位の
お金をなんとかして予算獲得してそこそこ新しいプロセスでフルカスタムの
LSI を作ったとしても、 x86 プロセッサの 1/10 くらいのクロックで回るも
のしか作れません。 従って、クロック当りの性能が 10倍以上のものでないと
それ、 x86 より遅くて高いけど、どういう意味があるの?
という話になるわけです。それでも数年前ならx86 プロセッサはクロック当り
1-2 演算だったので、20演算もできるアーキテクチャを考えればよかったので
すが、最近は x86 でもチップで見ると16演算とかになってますから 200演算
とかしないと話になりません。
しかも、多くの、というか普通に書いて特殊なチューニングをしていないアプ
リケーションでは、必ずメモリバンド幅が性能をリミットします。 x86 プロ
セッサはメモリバンド幅も結構快調に上げてきていて、2007年現在で
12.8GB/s とかそれ以上になっているわけです。これを大きく超えるものでな
いと、普通のプログラムで性能がでることにはなりません。
まあ、普通のプログラムで性能がでなくてもかまわないと私は思いますが、
それにしても 200 演算もするようなものを作らないといけないといわれたら
まともなアーキテクチャ屋さんならやってられないでしょう。
つまり、現状では、インテル以外のメーカーにしても、大学や研究所でのプロ
ジェクトにしても、あるいはインテル自身にしてさえ、 x86 以上の価格性能
比をもつプロセッサを作ることは非常に困難になっているわけです。実際、
Intelは x86 プロセッサを置き換えるべく様々な努力をしてきたわけですが、
現在のところ全て失敗におわっています。まあ、 Itanic、ではなくてItanium
はまだ開発を続けていますが、 Opteron や Xeon に比べて絶対性能でもメリッ
トがなくなってきています。
Intel 自身でさえできないことを他のところにできるか?というわけです。非
常に明らかなことは、同じようなアプローチでは駄目、ということです。例え
ばの話、まともにはやってられなくてもなんでも 200演算するチップを作らな
いといけないわけです。