42. GRAPE-DR の次 (2007/1/3)
GRAPE-DR の開発は今までのところ意外に順調に進んでいます。大体私がチッ
プを作ると結構びっくりするようなポカをしていてあれ?ということがあるの
ですが、GRAPE-DR では今のところそういうものは見つかっていません。
これは、今回チップの物理設計をやってくれた Alchip のエンジニアが経験豊
富で優秀であったことも大きいと思います。もちろん、チップ設計・試作の初
期コストが上がったので、より慎重に色々シミュレーションしてから作るよう
になった、という面もあります。もちろん、そのために開発コストがかさんで
いるというところもあるのですが。
とはいえ、チップができて、ボード量産をしよう、という段階になってくると、
このチップではどういうところで失敗していたか、というのが大体わかってき
ます。もちろん、アプリケーションがまだ色々あるわけではないので、特に応
用範囲については難しいのですが、それ以前の、性能とか製造コストとかいっ
たところについては現在頭を悩ましているところであり、次をやるならこうす
るべきだった、というのは色々でてきます。
これは、 GRAPE-DR の設計段階でこうしておくべきだった、という反省、とい
うわけでは必ずしもありません。 GRAPE-DR は、我々のグループが初めて作る
ソフトウェアでプログラム可能な計算機であり、 1 チップ超並列というコン
セプトの実証、という意味合いが大きいものだからです。このため、多少量産
コストが膨らむことになっても開発が容易になることを優先しました。
具体的には、
とはいえ、もしも次があるなら、同じものを作るわけではないのは当然です。
順番にみていきましょう。
まず、演算性能です。 GRAPE-DR の PE は 500MHz 動作、乗算器は 25x50 ビッ
ト、加減算器は倍精度(仮数 60ビット)です。このため、倍精度乗算には乗算
器と加算器の両方を使って、2サイクルに1演算しかできません。乗算のために
は加算器は2サイクルに1度しか使わないので、あいた時間に普通の演算ができ
ますか。このため、倍精度だとピーク性能が1クロック1演算になっています。
作ってみたら乗算器は結構小さかったので、これを倍にして倍精度乗算が1サイク
ル1演算できるようにするのはそれほど難しいことではありません。
もっとも、アプリケーションでの必要性という観点からは、倍精度乗算の性能
がそんなに重要かという問題はあります。例えば GRAPE では相互作用計算は
最初の座標の引き算と最後の積算以外は単精度ですましてきたわけで、それで
殆どの場合に精度が問題になることはありませんでした。従って、 GRAPE で
やってきたような粒子系の応用を考えるなら、倍精度演算を速くするより単精
度演算を速くするほうが、必要なハードウェア量がずっと少ないので効果的で
す。
もっとも、単精度演算と倍精度演算を両方使って効果的に性能を出すためには、
両方の演算器が同一のレジスタセットにアクセスできることが望ましいですし、
そもそも同じ演算器がハードウェアをあまり肥大化させないで両方の演算がで
きることが望ましいです。単精度の演算器と倍精度の演算器を別にもつと、両
方の演算数がちょうど両方の演算器の速度比と釣り合っていなければどちらか
の演算器は遊んでいることになり、全く無駄だからです。
様々なアプリケーションでの実効性能を最も高くする、という観点からは、お
そらく望ましいのは現在の 25x50ビットの乗算器を 25x25ビットの乗算器2つ
にして、単精度乗算2個を並列にできるようにし、さらに単精度の加減算器を
追加して1クロック当り単精度4演算にすることでしょう。これによる PE の面
積増加は数パーセント程度のはずですが、テクノロジーが変わらないとして
単精度での性能を 1 Tflops まで上げることができます。但し、倍精度の性能
はあがりません。当面 LINPACK 性能とかも大事だとすると、やはり乗算器は
倍精度1サイクルができるところまで強化するのが妥当でしょう。この場合面
積は 15パーセント程度増加しますが、倍精度 512 Gflops となってかなり余
裕ができます。
上の数字は、現在の GRAPE-DR と同じ 90nm プロセスで作った場合の話です。
これから作るならもちろん最悪でも 65nm になりますから、ほぼ倍のトランジ
スタが使えます。 従って、全くクロックが上がらなかったとしても倍精度
1Tflops、単精度 2 Tflops に到達できることになります。
クロックを50% 上げることができたら倍精度 1.5Tflops、単精度 3 Tflops と
いう辺りが、現在利用可能な技術で実現できる数字ということになります。
演算器を頑張ってパイプライン段数を増やすとかで動作クロックを上げること
も可能かもしれませんが、消費電力当りの性能を上げるためにはクロックを上
げても意味はないのであまりクロックはあげないですませたいところです。ま
た、レジスタやメモリがあまり高速動作できるものは半導体メーカー側で用意
していないかもしれないので、あまり動作クロックを上げようと頑張るのは見
返りが少ない話になります。
量産コスト、という観点から GRAPE-DR で問題なのは、1チップにつける他の
部品が多いことです。現在の GRAPE-DR チップは
メモリバンド幅がどの程度必要かはアプリケーションによりますが、例えば
LINPACK で性能を出すためには GRAPE-DR のチップ1つ当り 4GB/s 程度です。
現在の Intel プロセッサ用のノースブリッジチップは 12.8GB/s といったメ
モリ転送速度を持つものものあり、カスタムチップを作るならこの程度の I/O
能力をもたせることは不可能ではありません。この場合はノースブリッジ1つ
に対して GRAPE-DR チップが複数接続する構成もありえます。しかし、
GRAPE-DR の場合はこの部分を FPGA ですることが必須です。これは、もう1つ
チップを作るための予算も人手もないからです。
FPGA も最新のものを使うと十分な速度の DRAMインターフェースをもたせた上
で GRAPE-DRチップに必要な信号を出すのは可能ですが、結構高価なものにな
り、しかも GRAPE-DR チップ1つに FPGA 1つが必須、という感じになります。
FPGA は x86 マイクロプロセッサ以上に競争が厳しいところで、現在は
Xilinx と Altera の 2 社が 65nm プロセスを使った製品の出荷を始めたとこ
ろです。どちらもファブレスメーカーで、 Altera は TSMC を使っていますが
Xilinx は UMC と東芝を使っています。 FPGA は最先端プロセスで大きなチッ
プだと 100万円以上とかのありえない値段がつきますが、同じ製造プロセスで
も量産向けの少し速度や機能が低いものはかなり安価に供給する、という戦略
を両社ともにとっており、 Altera では Stratix と Cyclone、 Xilinx では
Virtex と Spartan となっていますが、どちらも高いほうは 65nm の出荷が始
まりましたが安いほうはまだ、という状況です。高いほうを使えばボード作れ
るけど、量産コストが、、、という状況になっています。
コストの面で大きいのが、メモリインターフェースです。 GRAPE-DR では、
4GB/s のデータレートで外付けメモリからデータがくるアーキテクチャになっ
ています。この部分の動作速度は 500MHz (250MHz DDR) で、現在の PC のメ
モリインターフェースとほぼ同等の速度です。メモリインターフェースを
FPGA にやらせると、 FPGA にはメモリとの間で 4GB/s、 GRAPE-DR チップと
の間で 4GB/s の合計 8GB/s もの速度がいるわけで、結構大変になります。
もしも、メモリが GRAPE-DR チップに直結できるように作っていたら、 FPGA
のこの部分はまったく不要になるわけで、量産コストはかなり下げることがで
きます。さらにもっと安くする方法は、メモリ内蔵にすることです。
GRAPE-DR を設計して、色々なアプリケーションでの性能を予備評価してみて
結構発見だったのは、
例えば重力のような粒子間相互作用計算の場合には、メモリ量の2乗に比例し
た計算をすることになりますのである程度大きい必要がありますが、この場合
のある程度というのは MB 程度のオーダーです。行列乗算だとメモリ量の 1.5
乗でしか計算量が増えないので、もう少し必要ですがせいぜい 64MB とかです。
これに対して、メッシュで流体計算とかの場合にはメモリ量と計算量が比例し
ます。しかし、この時には結局通信時間と計算時間の比がメモリ量に無関係に
なってしまうので、大きなメモリがあっても役に立ちません。
流体計算を加速ボード側で行って有効に加速するのはそういうわけで困難です。
全計算を加速ボード側で行うことにすればいいですが、この場合には結局オン
ボードメモリと GRAPE-DR チップとの転送バンド幅が問題になります。これを
桁で上げることができなければ、普通の PC のほうがメモリバンド幅あたりの
値段は安いからです。
とはいえ、メモリバンド幅を画期的に上げる方法がないわけではありません。
1つの方法は、メモリをプロセッサと同じチップに集積してしまうことです。
例えば BG/L では 130nm プロセスで 4MB のメモリを結構小さいチップに集積し、
22GB/s のバンド幅を実現しています。これは内蔵 DRAM を使っており、 CMOS
ロジックとの混載は結構面倒で初期コストもあがるものですが、
同じようなキャパシタによるメモリでありながら標準 CMOS プロセスで実現で
きる 1T-SRAMや
Z-RAM
のような技術もあります。特に 1T-SRAM は任天堂の GameCube や Wii でも使
われており、十分確立した技術です。90nm プロセスで 1.8Mbits/mmsq 程度の
密度を実現していますから、 65nm なら 3.5Mbits/mmsq となり例えば 128
Mbits (16MB) ですますなら 40 mmsq ですみます。これはもちろん小さくはな
いですが、例えば 15mm角のチップが 16.2mm角になる程度です。
チップサイズとコストの関係についても少し議論しておきましょう。一般に大
きなチップは高くなりますが、これは2つの要因があります。
一つは、単純に1枚のウェーハからとれるチップの数が面積に反比例して減る
ことです。これはしかし、あまり大きな要因では実はありません。はるかに大
きな要因は、良品率です。1枚のウェーハから沢山チップができますが、製造
時の色々な欠陥のために動かないチップがでてきます。欠陥がランダムにウェー
ハの上に分布するとすれば、チップサイズが大きい極限では良品率がチップサ
イズの指数関数で小さくなります。これは、以下のような考えれば納得できま
す。
あるサイズのチップを作った時に、欠陥がない確率が
もちろん、元々の
しかし、上の議論は、チップに1箇所でも欠陥があれば使えない、ということ
を想定しています。メモリマクロは普通冗長性があるように設計するので、欠
陥があっても予備を振り替えて使うことができるのでメモリで面積を増やして
も必ずしも良品率は下がりません。
なお、 GRAPE-DR のような超並列チップの場合には、プロセッサにも同様な冗
長性をもたせる、つまり予備をいれておいて不良があれば切換える、というこ
とが原理的には可能です。設計やテストのツールがそういうのに対応してくれ
るか、という問題はありますが、このために原理的にはチップサイズと良品率
は殆ど無関係になり、巨大なチップでも有効に使うことが可能です。
もちろん、外付 DRAM に比べて内蔵 DRAM や 1T-SRAM のビット単価は非常に
高価です。普通の DRAM なら 1GB が数千円であるのに、 1T-SRAM は数万円の
チップに 32MB がせいぜいですから 100倍以上高価なわけです。しかし、
プロセッサ部分のほうがもっと高価であるとか、チップからメモリインターフェー
スを出す配線コストも無視できないとか、そもそも 1GB も必要ではないといっ
た要因を考えると、ビット単価が安いことはあまりメリットにはなりません。
逆に、バンド幅あたりでは内蔵メモリのほうが安価になります。
GRAPE-DR でメモリインターフェースをつけなかった大きな理由は、つないで
動くかどうか自信がなかったからです。 FPGA は、高速インターフェースのた
めの I/O セルでタイミング調整とか色々する仕掛けがあるので、こちらで作
るチップが適当でも FPGA のほうで調整が効きます。メモリはそんな余裕はな
いので、こちらで調整しないといけないわけです。
が、内蔵にしてしまえばそんな面倒な話もなくなります。
メモリインターフェースを無くしてしまうと、あと残るのは
1チップでボード1枚の、グラフィックカードのようなシステムだけを作ること
を考えるなら、 PCI-Express まで集積というのは魅力的な話です。ボード価
格を極限まで下げることができるからです。しかし、多数チップを使って大規
模なシステムを作ることを考えると、 PCI-Express カードにチップ1つだけ、
というのは実装密度や消費電力から不利です。1台のホスト PC にせいぜい 2
枚しか PCI-Express カードはつかないので、電力の半分くらい、スペースの
殆どをホスト PCに使われてしまうからです。複数チップがのるカード
を作るなら、それらとホストの間を中継する何かはどうしても必要になります。
設計コストを考えると、やはりこの辺まで1チップというのは現実的ではあり
ません。
ここまでの話をまとめると、仮に 65nm プロセスで GRAPE-DR を作り直すなら
まあ、この話の要点は何かというと、現在の GRAPE-DR の設計はかなり改善の
余地が多いものなので、製造プロセスがあまり変わらないとしても色々やって
性能当りの量産コストを 1/3-1/4 程度にするのはそんなに難しいことではな
い、ということです。
といった辺りが、開発期間の短縮と開発コストの削減のためにとった戦略になっ
ています。実際、今回はそれでも開発コストと量産コスト(システム全体の)は
あまり変わらない状態ですので、決して最適から遠い選択ではなかったと考え
ています。
といったものを必要とします。普通に作ると、これは DRAM と、その DRAM を
制御するチップです。大雑把にいって、現在の Intel プロセッサではノース
ブリッジといっているようなものが必要になるわけです。
オンボードで大きなメモリをつけてもあまり役に立たない
ということです。メモリがどれくらいいるかは加速ボードとしての使い方によ
るわけですが、加速ボードの基本的な使い方は、ある程度の量のデータをまと
めてホストから送って、それに対してなにか計算させて結果を回収する、と
いうものです。この場合は、全体のデータはホスト側にあることになります。
そうすると、ボード側にいるメモリの量は、アプリケーションによりますが
そこでのデータ量と計算量の関係で決まることになります。
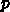 だったとしましょ
う。これの2倍の面積のチップをつくると、欠陥がない確率は、元々の大きさ
で2つならんだチップで両方とも動く確率と同じですから、
だったとしましょ
う。これの2倍の面積のチップをつくると、欠陥がない確率は、元々の大きさ
で2つならんだチップで両方とも動く確率と同じですから、 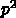 になりま
す。3倍になれば
になりま
す。3倍になれば 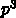 です。例えば
です。例えば 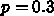 だったとすると、
だったとすると、 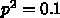 、
、
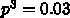 ですから、面積を3倍にすると良品率が 1/10 になり、1枚のウェー
ハからとれるチップの数は 1/30 になる、つまり製造コストが 30 倍になるわ
けです。
ですから、面積を3倍にすると良品率が 1/10 になり、1枚のウェー
ハからとれるチップの数は 1/30 になる、つまり製造コストが 30 倍になるわ
けです。
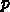 が 1 に近いならこんな急激なコスト上昇は起きないの
ですが、原理的に最先端プロセスは商業的に使えるか使えないかのぎりぎりの
ところで作りますから
が 1 に近いならこんな急激なコスト上昇は起きないの
ですが、原理的に最先端プロセスは商業的に使えるか使えないかのぎりぎりの
ところで作りますから 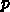 は 0.5 よりもずっと小さいのが普通です。
は 0.5 よりもずっと小さいのが普通です。
ですが、例えば PCI-Express のインターフェース自体を内蔵して完全に1チッ
プだけで動くようにするのでない限りこの辺は必要です。完全に1チップで動
くのがいいかどうか、という問題を少し考えてみましょう。
といったものになるでしょう。チップの消費電力は現在の GRAPE-DR とあまり
変わらないと期待されます。 4チップが載ったカードを作ると、 300W とかい
うアレな消費電力にはなりますが、実現不可能な値ではありません。製造原価
はハイエンドのグラフィックカード並なのですが、量が少ないので数倍の値段
になってしまいます。まあ、 50-100 万円ですね。1チップのシステムなら
20-30万にできるかもしれません。タイムスケールは、 65nm なら 2008-9年に
はできるかなあ?というところです。もう 1-2年後で 45 nm になれば性能の
数字はほぼ倍になるでしょう。