京速計算機プロジェクト(最近は次世代スーパーコンピュータープロジェクト
というようですが)は相変わらず方向性が定まらず、9月にあった官製シンポジ
ウムに合わせてNEC・日立連合と富士通がそれぞれ概念設計をし、その結果を
みて2006年度末に設計を決定すると発表されました。元々は3月に出させた提
案を7月に評価して8月には決める、という話だったのを、先送りにしたようで
す。それでも、総合科学技術会議の評価では、これは大変重要なものだからと
いうことで S評価(最高ランク)がつき、来年度の予算 87億円はほぼ通るもの
と思われます。
まともな設計をするのには半年という期間はいかにも中途半端で、延ばすこと
にどういう意味があるのかは理解しかねます。NEC が SX 後継以外の提案をす
ぐにするはずはないし、富士通は VPP5000 系を今更復活させるはずもないの
で SPARC でのスカラで提案するわけですから、時間をかけてたから良い提案
になる、ということがあるとすれば完成年度を遅らせたのでムーアの法則に従っ
て性能があがる、というくらいの理由しかありません。
まあ、どこかがひそかに ClearSpeed を買収してそういう提案をするとか、
あるいは BlueGene 的な提案をするとかがあればまた話は違いますが、上の2
者が残っているということは既にそういう提案はあったとしても採用されなかっ
たということを意味しています。
そういうわけで、日本の、しかも政治的なプロジェクトがどうこうという話を
みているとスーパーコンピューティングの将来はどっか別のところに落ちてい
るのかなあ、という気がしてきます。
ごくごく普通に x86 系は 2011 年あたりにどんなものになっているかを現在
の数字から外挿してみましょう。 2006年 10 月現在で、まあ普通のチップと
いうのは Core2Duo 3GHz というところでしょう。浮動小数点演算は 2コア4演
算づつなのでクロック当り 8 演算で、 24 Gflops です。5年前の 2001 年だ
と、 Pentium 4 が発表されて1年ほどたったところで、クロックは 2GHz、2演
算で 4 Gflops ですから、大体 8 倍になっています。ソケット 478 になった
ころですね。さらに5年前は Pentium Pro が Pentium II になるころで、クロッ
ク 200MHz 1演算 200Mflops ですから、この5年間は 10 倍です。まあ、この
頃だと Alpha とかのほうが速かったですが値段もそれなりだったので、ここ
では考えないことにします。
というわけで、 2011 年には 24Gflops のさらに 8 倍、 200Gflops になって
いると想像されます。これは、例えば現在2コアのものを 16 コアにする、あ
るいは 8 コアで演算数、クロックを少しづつ上げる、ヘテロジニアスマルチ
コアにして簡単なものを沢山入れると色々な実現方法がありますが、プロセス
は少なくとも 32nm、場合によってはその先になるわけですからトランジスタ
数は十分です。
メモリバンド幅がどうなっているかとかは全然不明ですが、グラフィックカー
ドでは現在 90GB/s 程度ができているのですから、デスクトップ用で 50GB/s
程度を想定するのはそれほど無理ではないでしょう。まあ、現在見えている
DDR3 1333 程度では2本でも 20GB/s ですが、 FM-DIMM みたいな余計なことを
しないで速くするのは XDR 直結にしてしまえばできるわけで容量が少ないと
いうのを別にすれば問題はありません。デスクトップでは容量はそれほど重要
な要因ではなくなってきていますから、そういうので 50GB/s くらいを実現す
るのはありえないことではないでしょう。
FB-DIMM の何が余計かというと、結局現在の Intel Xeon では CPU-North
Bridge-AMB-Memory とCPUとメモリの間に2段チップがはさまっていて、チップ
の I/O としては1つのアクセスで3回チップ間を渡るので、ピン数も 3 倍だし
消費電力も少なくともI/Oに関係する部分は 3 倍増するということです。正直
なところとても理解できない方針です。
話がそれましたが、大雑把にいってメモリバンド幅で現在の NEC SX-8R のちょっ
と下、演算性能で8倍程度の機械が、デスクトップ PC としてなら 10-20 万円
程度になります。 Crat XT3/XT4 のようにネットワークとかが高くて1ソケッ
トあたり 100万円程度になったとして、1億円で 20Tflops、1000億で
20Pflops です。頑張ってノード 50万なら 1000億で 40Pflops にもなってし
まいます。
普通の x86 系でこんなものなので、例えば IBM Power 系でも同様でしょう。
これはベースラインの、なにも技術革新も新アーキテクチャもなかった場合の
推測ですから、ちょっと何かあれば価格当りの性能は2倍程度にはすぐになり
ます。
例えば、 Los Alamos は 9 月に CELL ベースのスーパーコンピューターの納
入をアナウンスしました。 2008 年までに 4 ソケットの Opteron マザーボー
ドに4枚 CELLがそれぞれ2個づつ載ったカードを 1GB/s の IB でつないだもの
全体を2階層の IB でつないだものを作る、というものです。CELL は倍精度を
強化したとして 100Gflops 程度のようで、 2008年に 100Gflops なら x86 で
もいいのではないか、という気もしますが、アメリカではそういう新しい試み
に投資している、ということがここでは重要です。
つまり、一人の研究者とかいったレベルでは、どれかのアプローチに一点賭け
(少なくとも数年とかいったタイムスケールでは)して、当りを引けばラッキー、
でもいいのですし、その時にはちょっと考えて上手くいきそうにないものでも
実は上手くいくかもしれないから、そういうのに賭けるというのはありえる選
択でしょう。
しかし、国の計画という時に、目標自体が技術のトレンドを見た最低線のさら
に下に設定され、しかもそのための開発をシングルアーキテクチャに絞るとい
うのは印象としては不可解というしかありません。
また、 Cray は MTA の後継である XMT をアナウンスしましたが、ここでは
AMD の Torrenza イニシアティブに乗ることで Opteron ソケットにはめられ
るプロセッサにする、つまりネットワーク部分その他は XT4 と完全に共通化
することで開発費を削減しています。それでも、 Cray の発表資料を見てもそ
もそもどこにもピーク性能が書いてない辺りが Cray のこの製品に対する姿勢
を表していて、それは要するに義理で作ったけど売れるとは思ってません、と
いうものだと想像されます。
他方、注目すべきものは nVidia 8800 GPU です。これは 90nm、
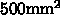 にも及ぶと言われる巨大なチップにそれぞれキャッシュと
かもっていて nVidia の説明では「スカラ方式」であるプロセッサが 128個載っ
たものです。動作クロックは 1.35GHz で、単精度ですが乗算と加減算のペア
と、もう一つ乗算の3演算をし理論ピークは 518 Gflops ということになりま
す。メモリは 384ビット幅の GDDR3 メモリで 90GB/s 程度の理論転送速度を
持ちます。つまり、単精度ですが上に述べた 2010 年頃の x86 マイクロプロ
セッサ以上の性能を 2006年時点で実現しているわけです。
にも及ぶと言われる巨大なチップにそれぞれキャッシュと
かもっていて nVidia の説明では「スカラ方式」であるプロセッサが 128個載っ
たものです。動作クロックは 1.35GHz で、単精度ですが乗算と加減算のペア
と、もう一つ乗算の3演算をし理論ピークは 518 Gflops ということになりま
す。メモリは 384ビット幅の GDDR3 メモリで 90GB/s 程度の理論転送速度を
持ちます。つまり、単精度ですが上に述べた 2010 年頃の x86 マイクロプロ
セッサ以上の性能を 2006年時点で実現しているわけです。
まあ、 GPU がこの程度の性能なのはしばらく前からであまり驚くような話で
はありませんが、これは少なくとも話としては汎用に近い、 C で書いたプロ
グラムが動くというものなのでそういう意味でのインパクトはあります。せっ
かく単精度乗算器が2つもあるなら、ちょっと工夫した回路設計にすれば 2 サ
イクル毎に乗算1つくらいはできるわけで、加算器もなんとかすれば倍精度
170 Gflops と 2006年時点としては極めて高い性能を実現できたわけですが、
そういうことはしていません。しかし、 CELL がそうしたように、こちらも次
の世代で倍精度演算をサポートしてくる可能性はでてきています。現在のダイ
サイズ、消費電力とも巨大なのでそんなにどんどんは性能が上がらないとは思
いますが、5年で5倍くらいはありえるでしょう。
そうなってくると、ピーク性能としては 1Tflops 近く、一応プログラムを書
くことも可能なものが数年後にはデスクトップ PC に載るわけです。 8800 は
nVidia ですが、 AMD に吸収された ATI が同様なものを作るなら CPU と統合
する可能性もあります。とすると、それは結局 x86 系のコアが複数とグラフィッ
ク用の単純なコアを沢山いれた、今の CELL をもっと性能をあげたようなもの
になるわけです。こういうものができてきたとすると倍精度での性能は少なく
とも 500 Gflops 前後になるでしょう。 x86 で単純にコア数を増やすのより
速くなければ意味がないからです。
つまり、グラフィックカードとしてか CPU に統合されてかは別として、デス
クトップの PC に 500Gflops から 1 Tflops 程度の演算速度がつく可能性は
かなり高い、ということです。そうなると、1000台で 1 Pflopsで、 1万台に
すれば、価格としては高いほうに見積もっても 100億で 10Pflops になってし
まいます。それ以前の問題として、安価に構成すれば15万円程度で1台作れる
わけで、1500万円で 100Tflops となります。もちろん、この機械の弱点はメ
モリサイズで、1TB がせいぜいでしょう。しかし、それはスーパーコンピュー
ターの応用の相当広い部分で十分以上なメモリサイズでもあります。つまり、
例えば1日で終わる計算を考えると、 100Tflops では大体 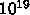 演算、
ピークの 10%しかでなかったとすれば
演算、
ピークの 10%しかでなかったとすれば 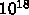 演算しかしません。1TB
のメモリは倍精度としても
演算しかしません。1TB
のメモリは倍精度としても 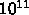 変数ですから、変数当り
変数ですから、変数当り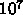 演
算にしかならないわけです。これはシミュレーションでは変数当りの計算量も
ステップ数も少ない部類です。
演
算にしかならないわけです。これはシミュレーションでは変数当りの計算量も
ステップ数も少ない部類です。
これから数年のスーパーコンピューター技術、というものを考えると、結局
x86 CPU や GPU のような、おそらくはコンシューマ市場に存在しているであ
ろうものをただ買ってくるのに比べて利点があるかどうか、というのがまず検
討されるべきことです。「日経エレクトロニクス」の 2006/10/23 号に「ペタ
コン技術が家電を磨く」という特集記事がありましたが、中身を読んで見ると
まさに Cell のような家電用の技術がスーパーコンピューターに使われる、と
いう方向性のものでした。
非常に大雑把な話として、計算機の性能は
-
演算性能
-
メモリバンド幅、レイテンシ
-
ネットワークバンド幅、レイテンシ
で決まります。もちろん、これらが高くても実際には性能がでない阿呆なシス
テムというのはありえますが、それは基本的に作りかたが間抜けなせいです。
なんらかの方法で実際のマシンで演算性能やメモリバンド幅を実現できるなら、
プログラムの工夫で実際のアプリケーションでの性能がこれらのどれかで
リミットされるところまでチューニングできるはずです。
さらに、基本的にはアプリケーションとアルゴリズムを決めると演算性能に対
してどれだけメモリバンド幅が必要か、またネットワークバンド幅やレイテン
シに対する要求がどういうものかも決まります。従って、どういう計算機にす
るべきかは自動的に決まるわけです。
もちろん、これは、専用化すれば性能があがる、というのとほぼ同じことです。
あるアプリケーションにかぎっても、開発費がでるならそれでいい
わけですが、例えば天文シミュレーション用の GRAPE で問題になったのは
LSI の開発費が大きくなりすぎたということでした。
ここで技術的に正しい解決策は LSI の開発費を下げるようなら研究開発をす
ることですが、私がそんなことをいっても誰かが聞いてくれるわけではないの
でもうちょっと汎用にする方向を考えてみましょう。
汎用といっても、本当に何に使われるのか全くわかりませんでは設計のしよ
うがないので、なんか適当に考えるしかありません。一つの方法は、定量的ア
プローチと称するものです。この考えは現在計算機アーキテクチャの標準的な
教科書であるいわゆるヘネパタ本、"Computer Architecture: A Quantitative
Approach" のタイトルにもなっているわけですが、ここでの考え方は実際に使
われているアプリケーションを分析して、それが速く実行できるように計算機
を作る、というものです。そのために、命令セット、コンパイラを組にして開
発します。アプリケーションは C とかのコンパイル言語で書かれたものをそ
のままもってきます。
この方法は、計算機設計に定量的な考え方を導入したものとして高く評価さ
れているらしいです。つまりは、それ以前には定量的な考え方はあまりなかっ
たということかもしれません。
さて、この方法がスーパーコンピューター開発に適当でしょうか?ここでは、
結局アプリケーションを選んだところでそれら専用の機械になりますし、さらに
そのアプリケーションがあるアルゴリズムを実装したものであったとして、
さらにそのアルゴリズムを特定の言語で特定の誰かが実装したもので、変数の
メモリ配置とかその他無限に細かいレベルで書かれかたが決まっています。
しかも、普通のプログラムは現在使っている計算機で速く動くように色々チュー
ニングされていますから、このような「定量的」アプローチを無自覚に採用す
ると現在の主流のアーキテクチャを自動的に継続することになり、計算機アー
キテクチャは進化の袋小路に陥ることになります。まあ、現在の商用マイクロ
プロセッサは基本的にそういう状態にあるわけです。この方向で性能を上げる
には膨大な開発費を投入して半導体の性能やデコーダやスケジューラの機能を
増やすくらいしかありません。
「定量的」と称するアプローチはそういうわけで駄目だとすると、どう
すればいいでしょうか?アーキテクチャ設計はアートであってエンジニアリン
グではない、とか芸術家をきどる方法もありえますが、それで予算をとるのは
難しいしそれ以前にそんなので成功するかというと、そういう人が一杯いてい
ろんなことをすれば誰かは成功するかもしれませんが、特定の一人を見た時に
成功する可能性は低いでしょう。そういうのに比べると定量的な方法のほうが
ましに決まってます。
いうまでもありませんが、定量的に設計を最適化しようとすること自体が問題
なわけではありません。問題は、何を前提にするか、何を最適化するか、といっ
た設定にあります。つまり、ヘネパタ本的な考え方では、結局、今あるプログ
ラムに最適な設計を考えようとするので、それらのプログラムが今あるプロセッ
サで効率的に実行されるように出来ていると、それらに対して最適なプロセッ
サ設計は今あるプロセッサに近いものになるわけです。
自分の例をもってくるのは自慢話みたいでみっともないですが、例えば GRAPE
の場合には、全体的なアーキテクチャは毎回くるくる変わっています。「粒子
の座標を受け取って相互作用を計算して返す」という概念は GRAPE-6まで変え
ていませんが、逆にいえば変わってないのはそれくらいで、プロセッサのアー
キテクチャは浮動小数点フォーマットといった低レベルのところから始まって
ネットワーク構成にいたるまでなにもかもを変えています。変えることによっ
て半導体技術の進歩を有効に使ってきたわけです。 GRAPE では、基本的には
独立時間刻み、直接計算のアルゴリズムに対してどういう並列化をし、どうい
う実装をし、ハードウェアをどんなふうに作るか、というのを、設計者が考え
つく範囲で色々な可能性を検討してきています。
これに似ていなくもないのはグラフィックカードで、OpenGL とか DirectX の
ような API が規定されていて、それをどう実現するかは全く GPU メーカーま
かせなわけです。このために、数年のタイムスケールで見るとハードウェアアー
キテクチャは結構くるくる変わってきています。
これはつまり、最適化を考えるにはレベルがある、ということです。天文シミュ
レーションを例にするなら、例えば星団のシミュレーションでは
-
モデル化の方法。流体近似、フォッカープランク近似、それ以外の連続体近
似、多体計算
-
多体計算を使うとしてその基本的計算スキーム。独立時間刻み、数値積分公式(古
典的線形多段階法、エルミート法、その他) 、直接計算、ネイバースキーム、
ツリー法、高速多重極法、それ以外の多重極展開法、
-
例えば独立時間刻みとエルミート法の組み合わせにしたとしてその実装方法。
並列化の手法、並列計算機向けのアルゴリズム
-
言語の選択
-
プロセッサアーキテクチャ向けの最適化。ベクトル化とか SIMD ユニットの
利用とか
というところで、ある言語で書かれたプログラムに対してそれで最も性能がで
るようなプロセッサを作る、というのは 1-5 を全部固定して、それでもでき
ることだけをする、という方針になるわけです。これに対して、 GRAPE の場
合には 1 は固定した上でアーキテクチャを考えていますが、それ以外は結構
動かしています。 QCD 用の計算機でも事情はあまり変わらなくて、格子 QCD
という定式化は上でいうと 1 のレベルで、そこから下は色々変えています。
1-5 を全部固定してしまうアプローチの良いところは、固定した中身はもう与
えられたものなのでそのよしあしについて考える必要がない、つまり思考停止
できることです。これを少し違う言い方をするとか、アプリケーションにしば
られない一般化、抽象化した計算機アーキテクチャを純粋に研究できる、とい
うことになります。実際、「計算機アーキテクチャの研究」というものをそれ
自体として、つまりアプリケーションに対する知識を前提としないで研究分野
として成立させるためにはそのような分離が必要になってきます。
そういう研究には意味がないかというと決してそんなことはなくて、そういっ
た分離をすることで新しいアプローチが可能になるという良い面もあることは
もちろんです。実際、 Intel や AMD の x86 系プロセッサは、このようなア
プローチで色々な専用計算機を含めた他の様々な計算機アーキテクチャを蹴散
らしてきたわけです。
それはそれで悪いことではないのですが、同じことをやっていたのでは少なく
とも同じだけ努力をしないと勝負にならないわけで、大変です。もうちょっと
楽になんかできる方法はないか?というと、結局上の 1-5 のなるべく上のほ
うまで制約を外してしまって、設計の自由度を広くすることが重要になってき
ます。
QCD 用計算機や GRAPE の場合には、アプリケーションを1つに絞り込むことで
1 はおいておいたとしてそれ以外の全てのレベルで最適化を考えることが少な
くとも原理的には可能になりました。汎用計算機でもそういうことはできない
ものでしょうか?原理的にはそういうことは考えられるはずで、ベンチマーク
で使っているようなアプリケーションセットが実際の応用を代表しているなら、
それらを与えられたプログラムとしてみるのではなくなるべくアルゴリズム、
数値スキーム、モデル化の方法といったレベルで解析することでどのような
ハードウェアを作ってどのような数値計算法を使いそれをどのように実装する
のが最適かを決めることはできるはずです。
もっとも、原理的には可能であっても現実的に可能か、というと難しいところ
かもしれません。 GRAPE の場合は、ハードウェア設計にかかわった人は基本
的に上の 1-5 の全部のレベルを一人でカバーするわけです。まあ、それぞれ
のところで一流というところまではいかなくて三流かもしれませんが、しかし
一人でカバーする、というところが重要であるような気がします。というのは、
結局どこにどういう自由度があるかはそこで何がやられているかがわからない
とわからないからです。その意味では、時々言われる計算機科学者と応用分野
の科学者の共同研究なんてものは殆ど意味がありません。
しかし、これを複数のアプリケーションでやろうとするなら、結局対象とする
アプリケーション全部について一人の人がそこでのモデル化から具体的なプロ
グラムの構造まで全部わかってないといけない、という話になり、レオナルド・
ダ・ビンチ的な超人が必要というような話でなかなか無理な話という気もしま
す。もっとも、私の大学院の時の指導教官だった杉本によると、自然科学とい
うのは1つの分野でちゃんとわかれば他の分野のことは全部わかるように出来
ていて、例えば流体力学、電磁気学、量子力学は全部同じである、とのことで
した。私は不肖の弟子なのでそういう境地には達していないのですが、本来そ
ういうものなのかもしれません。
しかし、落ち着いて考えてみると、アプリケーションに最適化というのは「汎
用計算機」というのとは原理的に矛盾しています。汎用というのは本来はどん
なアプリケーションでも高い性能がでるということであると思われますが、
いくつかのアプリケーションを選んでそれに最適なアーキテクチャにしたとい
うことは、結局それら専用に作っているわけです。
そういう作り方をするなら、それぞれのアプリケーション専用のハードウェア
を作って高速化してはなぜいけないのか?という疑問がわいてきます。もちろ
ん、これに対する教科書的な回答は、そういうのは全然見当違いの考え方であっ
て、そもそも汎用でプログラム可能な計算機の総合的な性能を測るために複数
のアプリケーションという多次元的な尺度を構成した、その尺度は、それで性
能が出ればそれからある程度外れた中間的なアプリケーションでも性能がでる
ように作った、ということになります。そういうわけなので、尺度毎に別の計
算機を作ったのでは全然意味がないということになります。
さて、そういう「万能な」計算機を1種類作る、という前提の上で、どう設計
するのが本当は良いのでしょうか?