25. スパコンの歴史 (2006/7/25)
(2010/7/14 追記)
以下、主に FACOM 230-75AP について、間違いを修正しています。
(2010/7/14 追記終わり)
(2013/5/13 追記)
いくつか誤字を訂正しました。
(2013/5/13 追記終わり)
というわけで、スパコンが過去どう発展してきたか、という話です。
スパコン、あるいはスーパーコンピューターという言葉がいつごろ生まれたの
かというのははっきりしません。定義も色々あります。ただ、最も単純で実際
的な定義は、
「その時代で最も速い汎用計算機」
というものでしょう。以下、単にそういう意味に使うことにします。
そうすると、定義から最初の汎用計算機はスーパーコンピューターであるとい
うことになります。
最初の汎用計算機が何であったかはなかなか議論があるところで、それだけを
扱った本が何冊もあります。また、裁判とかもあったようです。が、現在の計
算機の発展に直接つながったものとしてはペンシルベニア大学の ENIAC が重
要であることは疑いないでしょう。これは、真空管 18,000 本で各種演算器や
記憶装置を実現したものです。
但し、ENIAC は私達が普通に考える「プログラムが走る」計算機ではなかった
ようです。具体的にどうやったかは詳しく書いてある資料がなかなか見つから
ないですが、「配線」を変更することで解く方程式を変えた、ということのよ
うです。
まあ、科学技術計算用計算機、という観点からすると、プログラムをどうやる
か、というのは計算機科学が専門の人が色々いうほど大きな問題ではなくて、
自分が解きたい問題を解かせることができるかどうかが問題です。それは、
多くの場合に計算速度、計算精度、メモリ容量といったことで決まります。
そういう観点からは、 ENIAC は十進数 10桁の数を 20個記憶でき、1秒に
5000回加算、14回乗算を行うことができた機械、ということになります。
今の計算機ではクロックにあたる、パルス周期は 100 KHz であったとのこと
なので結構速く、その割には乗算速度は遅いですが、当時いくつかあったリレー
を使った計算機では乗算に数秒かかっていたのに比べるとほぼ 100倍の速度で
あり、スーパーコンピューターというにふさわしいものであったでしょう。
この後のスーパーコンピューターの発展史は、大雑把に以下の時期にわけられ
ます。
この時代は、要するにまだ計算機を作る方法の基本的なところがまだ良くわかっ
ていなかった時代、といっていいと思います。 ENIAC は普通の意味でプログ
ラム可能ではなかったわけですが、それが改良されてペンシルベニア大学の
EDVAC、 マンチェスター大学の Mark-I、 ケンブリッジ大学の EDSAC、プリン
ストン高等研究所の IAS コンピュータとその親戚である MANIAC、ORDVAC 等
につながりました。 さらに、商業ベースで計算機を作ろうという話がでてき
て、 ENIAC, EDVAC の主要人物であったエッカートとモークリーの UNIVAC を
始めとする沢山の計算機会社ができます。
計算機の設計手法も急速に進歩し、さらに真空管からトランジスタへ、という
構成要素の変化も始まりました。また、水銀遅延線やブラウン管メモリから磁
気コアメモリへ、磁気テープからドラム、ディスクへ、といった記憶装置の変
化、紙テープからパンチカードへ、といった変化も多くはこの時期に始まりま
す。
IBM は元々計算機メーカーではなく、パンチカードを使ったデータ処理のため
の機械を始めとする事務処理のための機械(タイプライターといったものも含
む)の会社でした。
リレー式の計算機をハーバード大学と共同で作るなど、早い時期から計算機に
は関心があったようですが、真空管を使った完全電子式の計算機に参入するの
はレミントン・ランド等の他の事務機メーカーに比べても早くはありませんで
した。事務機で確固とした地位を築いていたためもあるでしょう。
しかし、 IBM 701, 702/705, 704/709 といった真空管式計算機、さらには
7090, 7094 といったトランジスタ計算機で、あっというまに IBM が計算機の
代名詞になるところまで到達し、計算機の業界を支配します。
スーパーコンピューターの歴史、という観点からは重要なのは "Stretch"、
あるいは IBM 7030 でしょう。
これは、1960年代初めにおける IBM のフラグシップマシンであっただけでな
く、スーパーコンピューターの歴史上数え切れないほどある失敗の一例として
も重要です。1956 年に開発が始まった Stretch は IBM 704 の 100 倍の性能
を目指していたそうです。実際に実現した性能は目標の半分で、 IBM はその
分値段を割引いたそうで、結果として作るだけ赤字になった、という話です。
7030 の第1号機は Los Alamos Scientific Laboratories に、第2号機はNSA
に納入されています。これらの研究所は現在にいたるまでスーパーコンピュー
ターの重要な顧客でありつづけています。 Los Alamos は核兵器等まで扱う軍
の研究所であり、 NSA は国家安全保証局で、ここでは暗号関係の計算に使わ
れているものと想像されます。
7030 の後、 IBM は 360/91、中止された ACS プロジェクト、 360/195 等の
スーパーコンピューターというべき規模の計算機を開発しますが、常に
Seymour Cray を擁する Control Data の 6600, 7600 に性能では遅れをとり
つづけることになりました。
以下は、 Control Data が 1963年に CDC 6600 をアナウンスした時に当時の
IBM の社長が社内に回したと言われる有名なメモです
6600 はトランジスタを使った計算機で、まだ集積回路ではありません。7600
も同様です。 Crayが集積回路を使うのは 1976 年に出荷された Cray-1 が最
初になります。
6600 にしても 7600 にしても、そのために高速のトランジスタを開発したわ
けではなく、その高速性は主に論理設計、回路設計とパッケージングによるも
のだったということができます。パッケージングは特に重要で、大規模な回路
を小さな範囲に高い密度で詰め込むことで配線を短くし、高速な動作を可能に
しています。 7600 では 30 ns (33MHz) までクロックを上げています。但し、
6600 から 7600 への性能向上はそれほど大きなものではなく、また 7600 は
アーキテクチャ上使いにくい面もあり、 7600 は 6600 ほどは売れなかったよ
うです。
そのあと、 Cray は 8600 の開発を始めます。これはクロック 125 MHz で、
さらに 4 CPU がメモリを共有する機械であったと言われています。ここでも
Cray は集積回路を使わず、トランジスタで回路設計をしていたと言われてい
ます。
このプロジェクトはしかし様々な理由から Control Data の中ではサポートさ
れず、結局 1972 年に Cray は Control Data を去り、 Cray Research を設
立します。1925 年生まれですから、この時既に 47歳です。そこからわずか4
年で有名な Cray-1 を発表するところまできます。 Cray-1 は CDC で Cray
が設計した一連のマシン、特に 8600 とは大きく異なる、極めてシンプルなマ
シンでした。
その特徴は、なんといってもベクトルプロセッサのアーキテクチャにあります。
ベクトルプロセッサ自体は、考え方としては既に新しいものではありませんで
した。 CDC が Cray の 8600 を開発中止にした理由の一つは、同時期に開発
していたベクトルプロセッサ STAR-100 を完成させるための資金が必要だった
からです。
STAR-100 は memory-to-memory アーキテクチャをもつベクトルプロセッサで
した。つまり、例えば
今から考えると、そんなことは作る前からわかりきっている、と思うわけです
が、これは少なくとも CDC の STAR-100 に関わっていたデザイナーや、 TIで
やはり同様なベクトルプロセッサ (TI ASC) を開発していた人達には見えてい
なかった、ということになります。 Cray はもちろん CDC にいた頃から
STAR-100 には批判的であったわけですが、 8600 の開発が難航していたのも
確かでありそれが公平な判断とは他の人には思えなかったことでしょう。
それでも、当時の技術ではベクトルプロセッサは有効な方向であることは明ら
かでした。これについては既に第 3 回で述べた通りです。
Cray は、 Cray-1 においてベクトル命令を採用しますが、memory-to-memory
ではなくベクトルレジスタというものを導入しました。普通のスカラ計算機で
はレジスタというのは昔からあったわけです。これは、要するに非常に小規模
で高速のメモリであるわけで、例えば 8 語とか 32 語といった語数である代
わりに主記憶よりずっと高速なものです。非常に初期の計算機では、
レジスタは演算結果をしまうもの(アキュムレータ、 Aレジスタ)とアドレスを
しまうもの(Aレジスタに対してBレジスタと言われたりした)しかなかったりし
ました。この時には、命令セットは演算命令でもメモリアドレスを1つ、ある
いは2つ指定するものが多かった。 1 つでどうやって例えば a=b+c を実現す
るか、というのが気になると思いますが、
しかし、半導体技術が進歩し、トランジスタが高速、小型になった結果、演算
は速くなりましたがメモリアクセスはそれほどは速くなりませんでした。一つ
の理由は、1970年代初めまではメモリは磁気コアで、書き込み、読出しにマイ
クロ秒単位の時間がかかっていたからです。
Cray は、CDC 6600 で、メモリアクセス命令と演算命令を分離することでこの
問題をある程度解決していました。つまり、演算結果やオペランドを格納する
レジスタを1つから 8 個に増やし、演算はレジスタ間で行うようにしたのです。
そうすると、先程の a=b+c は
この発想は、 1980 年前後になって RISC という新しい名前で呼ばれることに
なります。
話がそれました。 Cray は、 CDC 6600 で導入した汎用レジスタの概念を、ベ
クトルプロセッサにも適用したのです。ベクトル命令は、一般には長さがわか
らないのでレジスタをどう作ればいいかもわからなかったわけですが、それを
「長さは 64」と決めてしまいました。これは、ハードウェアとしてはそれく
らい長さがあれば、レジスタ間命令では理論ピークに近い性能がでること、ま
た、半導体メモリになってメモリも高速化したので、 STAR-100 に比べてメモ
リアクセス命令でも短いベクトル長で性能がでるようになったこと、によって
いると思います。ベクトルレジスタは結構大きなハードウェアになるので、語
数は性能がでる範囲でなるべく小さくするべきものでした。64語8本という
Cray-1 のベクタレジスタは、Cray-1 で使った半導体技術では浮動小数点乗算
器と同等のハードウェア量であったはずであり、設計の観点がそういうもので
あったことが伺われます。
ちなみに、1チップに集積することを考えると、64語8本のベクトルレジスタは
乗算器よりはるかに大きくなります。それにもかかわらずこの程度、あるいは
ずっと大きなベクトルレジスタをつけた設計になっている多くのベクトル計算
機は、 Cray の設計の真似はしていてもその設計の精神を理解できてはいない、
と私は思います。
Cray-1 では、サイクルタイムも CDC 8600 の計画の 8ns には及ばないものの
7600 の 30ns よりも大幅に短い 12.5ns まで短縮したこともあり、
CDC は STAR-100 をベースにメモリを半導体メモリにし、全体設計もやり直し、
大規模なゲートアレイを使って高速化を目指した Cyber 205 の開発を始めま
すが、これは当初の目標であったサイクルタイム 10ns から 20ns に落として
1980年代初めにようやく完成します。これは理論ピーク 400Mflops (加算、乗
算4演算並列) のものまで存在しましたが、出荷されたものは殆ど 200Mflops
のもので、 Cray-1 や、Cyber-205 とほぼ同時期に出荷が始まった Cray-XMP
とは競争しようがないものでした。
Cray 本人は、 Cray-1 の後 Cray-2 の開発に進みます。最初はガリウム砒素
(GaAs) デバイスを使って高速化するつもりだったようですが、結局シリコン
に戻ります。そういったこともあって開発は遅れ、出荷できたのは 1985 年と
Cray-1 からほぼ 10年が過ぎていました。ピーク性能はわずか 12倍の 2
Gflops であり、10年間の進歩としては十分ではありませんでした。
Cray Research 内部では、 Cray-2 の遅れもあり Cray-1 ベースで改良したマ
シンの設計が進みます。これが 1982 年に出荷が始まった Cray-XMP です。サ
イクルタイムは最終型で 9.5 ns と、Cray-1 からさほど改善されていません
が、メモリバンド幅が大幅に強化され、一定幅や間接アドレスでのメモリアク
セスも高速化し、さらに 4 CPU までのマルチプロセッサが可能になったこと
で、多くのアプリケーションで性能を大きく改善しました。
この後、殆ど命令セット、アーキテクチャの変更をすることなく、Cray
Research では YMP, C-90, T-90 と XMP の後継機がつくられていきます。
これに対して、 Cray 本人は Cray-3 の開発にかかりますが、 Cray Research
から離れて Cray Computer Corp. を設立します。しかし、GaAs を使って 2ns
のサイクルタイムを実現した Cray-3 は 1993 年にはほぼ完成したものの1台
も売れることはなく、 1ns のサイクルタイムを目指して Cray-4 の開発中に
Cray Computer は倒産することになります。
その後も Cray は SRC を設立して新たな並列計算機の開発に挑みますが、
1996 年に交通事故で亡くなりました。
前節で見たように、 Cray-1 の完成後、アメリカでのスーパーコンピューター
の開発は停滞します。Cray 本人は Cray-2 を完成させるのに手間どり、 Cray
Research はなにも新しいことができず、 CDC は Cray-1 に追いつくのに 5
年を要していたからです。この間に IBM やら他の会社が何かできなかったも
のか?とも思いますが、そうもなっていません。
これは、日本の計算機メーカーには大きなチャンスでした。1970年代末に日立は
付加アレイプロセッサ、富士通の場合には
本格的なベクトルプロセッサである FACOM 230-75AP を開発していますが、
Cray のマシンに対抗する、あるいは上回る性能を発揮するベクトルプロセッサは 1982
年の富士通 VP-200、1983年の日立 S-810、 1985年の NEC SX-2 を待つことに
なります。
これらはいずれも 1 Gflops 前後の速度を 1 プロセッサ(同時加算、乗算 4
演算づつ) 程度で実現し、ベクタレジスタをもつ Cray 的な設計と、複数
のパイプライン演算ユニットを並列に動かす STAR-100/Cyber205 的な設計の
長所を合わせたバランスのとれたデザインになっています。さらに、 Cray と
は違って半導体製造からやる垂直統合型の企業であり、スーパーコンピューター
と大型メインフレームで開発費を分散させることができたこともあって同時期
の Cray のシステムにまさる(Cray-2 には負けますが)サイクルタイムと単体
性能を実現しました。
スカラー部分の命令セットは、日立、富士通の場合には IBM 互換のままであ
り、 Cray 並の高速化は難しいものでしたが、ベクトル性能は高く、またコン
パイラも Cray CFT77 が 80 年代後半にでてくるまでは日本メーカーの製品の
ほうがはるかに優れていました。 このため、アメリカ以外では富士通、NEC
の製品は大きなマーケットをもつようになります。
アメリカでは、色々不可解な貿易障壁が設定されたためもあり、日本のメーカー
はこの時期殆ど商売することができませんでした。
この後、日立は 1987 年にほぼ性能を 3 倍にした S-820 を、富士通は1988年に
VP-2600 を投入します。これらは、性能的には NEC が 1989 年に投入した、
4CPU 共有メモリで理論ピーク性能 22 Gflops の SX-3 に対抗するべくもない
ものでしたが、若干先行したこと、また日本のマーケットでは性能だけが問題ではない、ということも
ありある程度は売れています。その次の世代では、日立は SX-3 とほぼ同じ構
成ですが 1.5 倍程度速い S-3800 を 1993年になってやっと出荷したのに対し
て、富士通は革命的な VPP-500 を 1992 年に発表、その原型を航技研数値
風洞として製造、1993年に納入します。 これは当初 140 プロセッサ、 238Gflops という驚異的
な性能を実現し、共有メモリベクトル並列計算機の時代に終止符を打ちました。
日立はこの時点でベクトルプロセッサから撤退し、筑波大学の CP-PACS プロ
ジェクトで開発された疑似ベクトル機能をもったスカラー並列機をスーパーコ
ンピューターとして販売することになります。これは SR-2201, SR-8000 と続
きますが、その次の SR-11000 は基本的には IBM Regatta そのものでプロセッ
サの機能付加はしていません。これは、 Regatta そのものがほぼ疑似ベクト
ルと同等の機能を実現できるハードウェアプリフェッチ機構を備えたものであっ
たからでもあります。
VPP-500 はバイポーラ半導体(BiCMOS, GaAS も)を使っていましたが、クロッ
クは 100MHz(NWT では 105MHz) とそれ
までのベクトル並列機から下げることで消費電力とサイズを小さくしています。
166 台(設計最大は 222台)もの並列動作を可能にしたのは、それまでのベクトル
並列計算機が共有メモリ構成だったのに対して、プロセッサ毎にローカルメモ
リにしてそれらをクロスバーネットワークでつなぐ分散メモリアーキテクチャ
にしたためです。これは、富士通 230-75AP の時代からユーザーとして日本の
スーパーコンピューター開発を指導し、地球シミュレータの開発をも指揮した
航技研の三好氏と富士通の共同開発の成果です。
VPP シリーズは CMOS 化した VPP-300、それを高速化し、接続台数を増やした
VPP-700, VPP-5000 と発展していきますが、 VPP-5000 の後継機は開発されま
せんでした。ここに、富士通の輝かしいベクトル計算機開発の歴史は幕を閉じる
ことになります。
一方、 NEC はいち早く CMOS 化して 32 プロセッサまで共有メモリとし、さ
らにそれらを高速ネットワーク接続することで 512 プロセッサまで構成可能
という SX-4 を投入します。富士通 VPP に比べて価格性能比では劣るものの、
共有メモリ構成による使いやすさもあり一定のシェアを確保します。さらに、
地球シミュレータの契約を取り付けたことで 8プロセッサまで共有メモリの
SX-6 を開発し、それを 32プロセッサまで共有に拡張した SX-7、ノード性能
を2倍にひき上げた SX-8 と続き、現在もその後継の開発が続いています。
簡単に特徴をまとめてみましょう。大体こんな感じです。
以下、もう少し詳しく各時代を解説してみます。
25.1. パイオニアの時代 1950 年代半ばまで
25.2. IBM の時代 1960年代半ばまで
25.3. Seymour Cray の時代 1980年代前半まで
MEMORANDUMAugust 28, 1963
Memorandum To: Messrs. A. L. Williams
T. V. Learson
H. W. Miller, Jr.
E. R. Piore
O. M. Scott
M. B. Smith
A. K. Watson
Last week CDC had a press conference during which they officially
announced their 6600 system. I understand that in the laboratory
developing this system there are only 34 people, "including the
janitor." Of these, 14 are engineers and 4 are programmers, and
only one person has a PhD., a relatively junior programmer. To
the outsider, the laboratory appeared to be cost conscious, hard
working, and highly motivated.
Contrasting this modest effort with our own vast development
activities, I fail to understand why we have lost our industry
leadership by letting someone else offer the world's most
powerful computer. At Jenny Lake, I think top priority should
be given to a discussion as to what we are doing wrong and how we
should go about changing it immediately.
T. J. Watson, Jr.
TJW,Jr:jmc
cc: Mr. W. B. McWhirter
Reproduced in A Few Good Men from Univac.
当時既に Cray は ERA (後に Remington Rand に買収され、Eckert と Mauchly
の ECC とともに UNIVAC の一部になる)で 1103、Control Data で 1604 を開
発し、天才的なエンジニアとして知られていました。 1604 は比較的小規模な
システムでしたが、6600 は最大級の計算機であり当時として驚異的な 100ns
のサイクルタイム (10MHz クロック)で 3Mflops 程度の性能を実現しました。
do i=1,n
a(i) = b(i)+c(i)
enddo
という DO ループが、アセンブラ1命令に翻訳され、直接実行されるのです。
これはこれで悪くないアーキテクチャなのですが、当時のアプリケーションの
大きさ、コンパイラの状況を考えると大きな問題がありました。命令の実行が
始まって、最初の結果がメモリに届くまでに 100サイクル以上の時間がかかっ
たのです。1サイクルに 2 演算とか4 演算までできる設計でしたから、これは
1つのベクトル命令で 400演算してやっとピーク性能の半分、800 しても 2/3
しか出ない、ということを意味します。 しかし、当時は 2次元の流体計算で
も 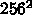 メッシュで大きいほう、 3 次元なら1方向 100 は無理、という
頃ですから、これは、現実に扱える程度の問題サイズでは性能がでない、とい
うことを意味します。
メッシュで大きいほう、 3 次元なら1方向 100 は無理、という
頃ですから、これは、現実に扱える程度の問題サイズでは性能がでない、とい
うことを意味します。
変数b(に対応するメモリアドレスの中身) を A レジスタにロード
変数c と A レジスタの中身を加算して結果を A レジスタに格納
A レジスタの中身を変数 a に格納
というような手順になります。こんなややこしいことをしていては遅くならな
いか?と思うわけですが、初期の計算機では問題になりませんでした。実際の
演算に、メモリから読んでくるとか結果をメモリにしまうとかに比べてずっと
長い時間がかかったからです。
b をレジスタ0(例えば)にロード
c をレジスタ1にロード
レジスタ 0 とレジスタ1 を加算して結果をレジスタ 2 に格納
レジスタ 2 の値を a に格納
となります。さっきのメモリから演算するのに比べてもっと命令数が増えて何
もいいことはないのでは?と思うかもしれませんが、そうではありません。
というのは、色々並列に実行できる可能性が増えるからです。例えば
a=b+c
d=e+f
だと、 b, c をレジスタにいれた(load した)あとで、演算を始めるのと同時に
e, f のロードを始めることができます。もっとややこしい計算だと、もっと
いろんな並列に実行できる命令をを実行時に検出して並列実行できます。
1つの A レジスタが常に演算に関係していると、そんなことは不可能だったわ
けです。複数のレジスタをもつ計算機は CDC 6600 以前にもありましたが、演
算をレジスタ間だけにすることでハードウェアの単純化と高速化を同時に実現
したのは Cray が最初でした。
ということになりました。少し前の 1974 に完成した STAR-100 はサイクルタ
イムが 7600 よりも遅い 40ns となり、既に述べたようにベクトル命令でもな
かなか性能がでなかった上にスカラー命令はもっと遅い、という代物であった
ために全く売れませでした。
25.4. 日本の時代 1990年代前半まで