マトリックス型の超並列プロセッサを開発
− 200MHz動作で40GOPSの処理性能を実現した低消費電力プロセッサ −

 | マトリックス・アーキテクチャ・ プロセッサ チップ写真
|
|
2006年2月9日
株式会社ルネサス テクノロジ
株式会社ルネサス テクノロジ (本社:
東京都千代田区、社長&CEO 伊藤 達)は、このたび、画像や音声のマルチメディアデータ処理に適したマトリックス型の超並列プロセッサを開発しました。
新構造のプロセッサは、2048個の演算器と1MビットのSRAMを密結合した超並列のプログラマブルデバイス(注1)で、200MHz動作で40GOPS (Giga Operations Per Second)の処理性能を実現することを確認しました。
本成果は、2月5日から米国サンフランシスコで開催される国際固体素子回路会議「2006 IEEE International Solid-State Circuits Conference (ISSCC)」において発表致しました。
<背景>
デ
ジタル家電機器等においては、画像や音声等のマルチメディアデータ処理が必須であり、これらのデータ処理は、高速フーリエ変換や畳み込み、差分絶対値和等
の複雑な演算の組み合わせで行なっています。これまで、これらの演算処理は、専用論理回路やデジタル信号処理に特化したDSP(Digital
Signal
Processor)を用いることが一般的でした。しかし、近年のマルチメディアアプリケーションの進化は著しく、例えば、画像アプリケーションにおける
画素数は急激に増大しており、マルチメディアデータの飛躍的な処理性能の向上が求められています。さらに、多様なマルチメディアデータの規格への対応を容
易にするためにプログラマブルデバイスで実現することへの要求も高いものがあります。
一
方、処理性能向上の方法の1つとして、半導体プロセスの微細化による動作周波数の高速化があります。しかし、今後は、微細化による手段だけでは、高速化と
低消費電力化を両立しながら飛躍的に性能向上することは難しく、従来のDSP等のアーキテクチャでは、求められる性能の実現が困難になることが考えられま
す。また、処理性能を高めるアーキテクチャとして、粗粒度MIMD(Multiple Instruction Multiple
Data)型のプロセッサも発表されていますが、小面積化や低消費電力化が課題になっています。
<技術の内容>
このような背景から、当社は、専用論理回路並みの処理性能をもつプログラマブルデバイスを目標として、DSPやMIMD型プロセッサとは異なるメモリ技術をベースにしたマトリックス型プロセッサを開発しました。
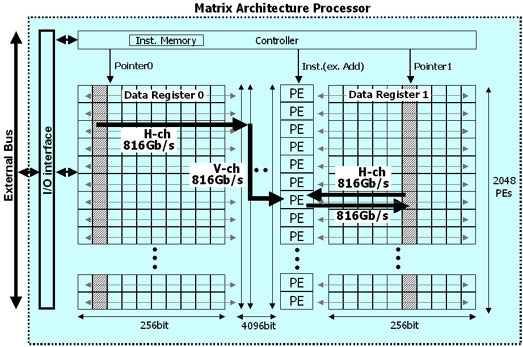
新構造のプロセッサは、細粒度SIMD (Single Instruction Multiple Data)型の超並列プログラマブルデバイスで、構造概略は下記のとおりです。
- 基本構成: 2ビットの演算器(PE: Processing Elements)とデータレジスタとして割り当てる512ビットのSRAM
- 2048個のPEと合計1MビットのSRAM、並びにPE間のそれぞれを密結合
本プロセッサの高性能化は、各々の演算器をいかに効率よく動作させることにあり、また、省面積化や低消費電力化を図る上では演算器とデータレジスタの配置、接続が重要です。
これらの課題は、以下の技術により実現しました。
-
(1) データレジスタとPE間、およびPE相互間の接続技術
-
- PE間を接続するHチャネル (Horizontal Channel)
演算器とデータレジスタ間でデータ転送を行うための接続経路で、演算の基本経路となります。データ転送は相互に干渉することなく1クロックで行われます。
- PE相互間を接続するVチャネル (Vertical Channel)
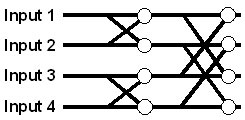
PEとPEの間でデータ転送するための接続経路です。Vチャネルは、一定の距離にあるPE間を並列にデータ転送することが可能であり、本転送経路によりデジタル信号処理演算では必須のバタフライ演算(注2)を効率よく処理できます。
- Hチャネル、Vチャネルともに、200MHz動作時で816Gbps(giga bit per second)の転送速度を実現しています。
-
(2) PEの回路構成
- 一
般的なSIMD型プロセッサは条件ジャンプができないという問題があります。本プロセッサでは、2ビットのPEの回路構成に工夫を施しました。各PEにV
フラグ(Valid
Flag)という1ビットのレジスタを設け、Hチャネル、Vチャネルのデータ転送、或いはPEの演算そのものを実行するか否かを選択します。これにより、
クロックサイクルごとの条件ジャンプが可能となり、バタフライ演算の高速化等に大きく寄与しています。
-
(3) 2バンク構成、Read-Modify-Write動作のSRAM回路
- PEの基本は2入力1出力です。このため、PEを連続的に動作させるためには3ポートのデータレジスタが必要になりますが、これを面積の小さなシングルポートSRAMで実現するため、以下の構成としました。
-
- SRAMのエリアを2バンクに分割します。2つの入力データを、この2つのバンクの各々から読み込みます。
- 同時に、出力データは読み込みに使ったデータへの上書きとし、この上書きをメモリのRead-Modify-Write動作で行います。
- この結果、読み出しから演算、さらに書き込みに至るまでを1クロック内で完了させることができ、小面積のデータレジスタを実現しました。
<効果>
以上の技術により、90nm CMOSプロセスにてプロセッサを試作した結果、200MHz動作で40GOPSの処理性能を、コア面積3.1mm2、消費電力250mWで実現しました。これは当社の既存DSPと比較し、単位面積比で約70倍、単位電力比で約13倍の性能向上となります。
今回開発した技術は、マルチメディアデータの処理を司るSoC(system-on-a-chip)の処理性能を飛躍的に向上させるものとして、今後期待できるものです。
■ 注記
- (注 1)
- プログラマブルデバイス: 回路構成を変更できるプロセッサの総称。
- (注 2)
- バタフライ演算: 高速フーリエ変換等で使用される演算方法。演算の入力がたすき掛けになっており、図(補足図2)で表すと蝶のように見えることからこのように呼ばれている。
■ 問合せ先
株式会社ルネサス テクノロジ 経営企画統括部 広報・宣伝部 [担当: 佐藤]
〒100-6334 東京都千代田区丸の内二丁目4番1号(丸ビル)
TEL 03(6250)5554 (ダイヤルイン)
[
Webでの問合せ ]
以 上
<補足図1: 構成概要>
<補足図2: バタフライ演算の図>
*** このニュースリリースに掲載されている情報は、発表日現在の情報です。 ***
*** 発表日以降に変更される場合もありますので、あらかじめご了承ください。 ***
|