つっても、非公開のを別につけているわけではない。
Copyright 1999- Jun Makino
2022/05 2022/04 2022/03 2022/02 2022/01 もっと昔国立天文台のリリース M87銀河の中心の電波観測データを独立に再解析
こっちはもちろん研究者の個人名がでている。
世界初のブラックホール画像に異論 国立天文台、別チームが再解析 -- 画像が SgrA* だ。そっちの話は(まだ)してないってば。
画像が本物かどうかはだいぶ違う話、、、
もちろん、H/S/DGEMM だけ加速したとしてそれであらゆるアプリケーションが速くなるわけではないけど、あらゆることに深層学習が使えるならそれでもいいわけで。
まあそんなに深層学習が万能かというとそうでもないとは思う。なので構造格子、非構造格子、粒子法の全部を行列乗算ないしそれと共用できる演算パイプラインでなんとかできれば大抵の数値シミュレーションは速くなる。
構造でも非構造でも行列乗算的回路でわりとなんとかできそうで、駄目な のは粒子な気がする。遠方のクーロン力とか重力ならどうせツリーとかでよく てすごい精度はいらないので、GRAPE-5のパイプラインくらいのを集積でもい い気がする。
座標48ビット、積算64ビット、途中の仮数10ビットとして adder 400bit,6000ゲートくらい。10ビット乗算器が6個で6000ゲート、あと色々なあ わせても15kゲートくらいであろう。これでまあ30演算とする。倍精度乗算器1 つは3万ゲートくらいなので、ゲート数同じなら30倍の性能になる。
逆にいうと演算器ロジックの10%追加すれば性能4倍、というかこっちのパ イプラインは加減算の数がとかの問題なくてカーネル効率1000%なので 5-6倍になる。
まあクーロン力だけでは通らないよね、、、あと DPとか?DPは基本的に 加算/比較なのでクーロン力パイプラインの積算部分とかとは共用できなくな いことはないかもしれない。
引用:「太陽電池がエネルギー源にならない」という主張は、実際の使用材料やエネルギー消費量を調べ上げた科学的(*2)な調査結果と矛盾しており、またそれ以上の信頼性があるとも言えません。
引用:誤った前提・手法による計算や、「疑似科学」(ニセ科学)と呼ばれる手法を用いて科学的事実に見せかけている例が見られますので、ご注意下さい。
まあ現在のシリコンで作るやつがでは sustainable かというとそうじゃないと思うけど。
配送エラーメイルがいった皆様すみません。
連星とか衝突に近い軌道とかで軌道積分ちゃんとできてない気がするが、、、
というようなことを某発表原稿をみながら考えた。まあ注意深くやらないと失敗するしデータが不足だと注意深くやっても失敗するということであろう。
まあ実際S269 だって水沢的には H07は間違ってないことに今でもなってるよね。VLBAの結果はそれとは矛盾するけど、VERAカタログにはH07の結果が今でものってる。
これは まあ Science in action はそういうものだ、という話で個々の研究者が科学的かどうかというような話じゃない、という面はある。
というわけでちょっと放心状態。メイル遅延中+別の書類遅延中、、、
岡山大学のプレスリリースは 6/6付。
毎日は「関係者の話」。朝日も「関係者への取材」としつつ「独自」とも。まあもちろん単に嘘ついてる可能性もあるが岡山大学のプレスリリースではないソースを使っていると読める。
まあ今のところ朝日、毎日の実際のソースは不明なので悪いほうに想像して攻撃する人はいるだろうというところか。
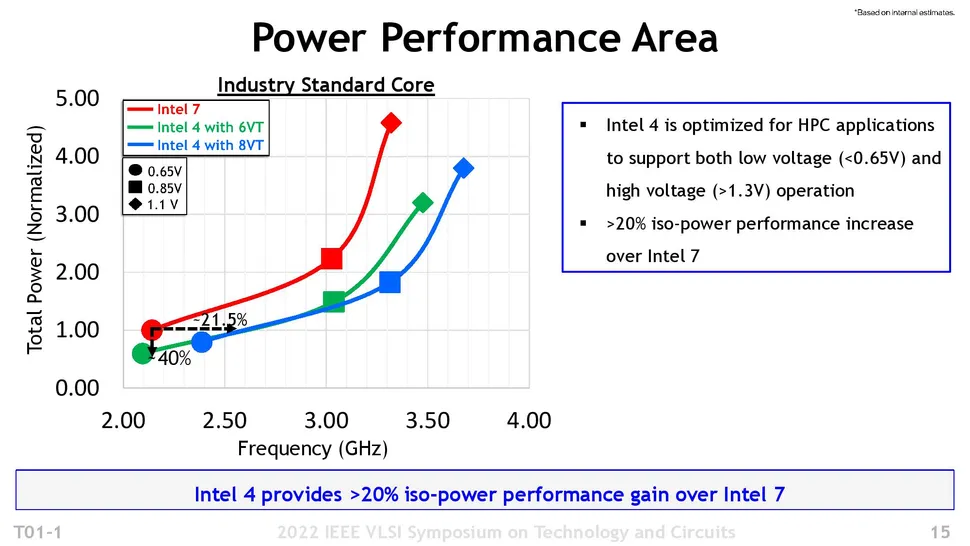
PPAの図が大変興味深い。 Intel 7 では 0.65V, 0.85V, 1.1V でクロック2.15GHz, 3.05, 3.3, 電力は 1, 2.2, 4.6くらい。電力は fV^2 で綺麗にあう。
なので、電力性能最大はもうちょっと電圧下げたところ、 0.45-0.5Vくらいだと思うけど、それで1GHz動作とかでは厳しい、ということであろう。
で、Intel 4 6VTではほぼ同じクロックと電圧でさらに40%電力下がると。 とはいえ「当社比」なのであんまり意味がない。N3との比較の表はあるけどこ れなんか数字変でよくわからないがIntel の主張としてはN3より悪くない、であろう。
引用: 「今朝、以下の論文(タイトルを記載)が回って来ました。タイトルから先生の論文と思い、引き受けました。簡単なコメントを頂けたら、参考にさせて頂きます」
レフェリーになった人が著者に直接なんか聞いちゃったということ? 「タイトルから」とあるから、著者名消してレフェリー依頼する業界なのね。だとすると逆に
「タイトルから先生の論文と思い」と書いてなければ単に専門家の意見を聞いただけになる?なんかややこしいケースだ。「先生の専門分野なので」とか。 まあでも実際には著者わかるよね、、、
引用:昨日6日、JAXAを通じまして、分析の結果、生命の起源に結びつきますアミノ酸が存在することが判明をしたとの報告を受けております。
これ見る限り、6/6 の時点でJAXA はオープンにしてよいという判断だったのかな?それとも抜かれたから出した?
On the origin and evolution of the asteroid Ryugu: A comprehensive geochemical perspectiveProc. Jpn. Acad., Ser. B 98 (2022) (Received Jan. 31, 2022; accepted May 6, 2022)
アクセプトされたらプレスやっていい、が普通だよね。ApJはそう(というのを先月聞いたし前にやった時もそうだった)
つーか、アクセプトされたなら arxive にだしてくれればいいのに、、、
岡山のプレスリリース これは 6/6付けだけど朝日の記事は 6/6 早朝なので、記事にある通り「関係者への取材」ということか。もちろん、このリリースがあるという情報で、ということだろうけど。
プレスリリースがなんだろうが「関係者への取材」できちゃったなら記事にする、というメディア側の論理はありえるし、それは「関係者」の脇が、、、という気も、、、
まあ少なくとも Science の論文(東工大横山さん他)と Proc. Jpn. Acad., Ser. B の論文(岡山大中村さん他)は全然別の内容なので、 Science のエンバーゴが云々というのはピント外れであろう。
しかし微量分析は相変わらず岡山なのねというのがなんかすごい。
サンプル分割する時に、分割先をあらかじめサイズきめてとってあるんだけど、ソートされてるとと行き先が全部同じになって溢れていた。溢れそうになったら分割先のサイズの割り当てを変えるようにして一応解決。
FDPS にいれて富岳ではちゃんと速くなること確認した。
取材申し込みは(もちろん私じゃなくて三好さんに)きてて、国立天文台から記者会見するから、ということで待ってもらってる。論文はでてるからそれで中身わかるなら記事にすればいいしそれくらいは科学ジャーナリストならできて欲しいが、まあ。
N5:N7, N3:N5 で電力はそれぞれ 30%, 25-30%減少と。でもこれ速度同じで電圧さげて、なんだよね、、、 面積は 0.55x, 0.58x. N7:16FF+ だと電力 -60%。対12FFCだとこれが -20%として半分までいくかしら?
全部合わせてても12FFCからN3までで電力 1/4にしかならない。面積は1/10以下だけど、、、
N2がTSMC 公式スケジュールでも2025。そうするとN3がもう製造にはいるわけでその先は本当にスローダウンする。
引用:インテル® DDIO テクノロジーを適切に活用することで、L3 キャッシュのみでコアと I/O デバイス間の相互作用に対応して、DRAM へのアクセスを完全に排除することができ、以下の利点が得られます。
分岐予測の実装とかは進化させるの無理か?実装選択するとか?
サンプルプログラムはコンパイル言語で与えて命令セット自体を機械学習 でというのも命令セットの空間を定義できればできる?
いやそのCPU設計ってものすごく個人依存で、この設計チームがこれ作っ たみたいな話しかないわけだけどいつまでそうなんだろうみたいな。
引用:アーキテクチャ研究者に言わせると、「1秒動けば論文が書ける」そうだが、物理学など実用の計算機はそうはいかない。1日24時間、年365日動かないと仕事にならない。これは、手作りに毛の生えたようなコンピュータにとっては過酷な要求であった。
「アーキテクチャ研究者」が固有名詞な気がするがそれはともかく、エラーが起こったかどうかがわかるなら数時間に一回エラーおきてもかまわない、というのが古くからの知恵であろう。分からないと駄目だけど。
そういうわけで Cray-1 にもメモリパリティがついたみたいな。
で、まあ、今回もそうなるんだけど、まあ、それはそういうものだということで。
するんだけど、これ確率論なりベイズ推定なりでちゃんと示せるのかしら?そもそも正しいのか、ということでもあるけど。
直観的には、そもそも正解は知らない単語である確率が高いわけだから、 当然そっちを選ぶべき、となるような気がする。
でも、問題はここで2語が残っていることで、残った2語についてはどちら も 1/n の確率で正解であるわけだから、どっちが正しいかは 1:1 だ、と議論 できる気もする。
一方、2語残った時に、実際にどっちになるか、というと、試行を多数回 やった時に知らない単語のほうが多くならないとおかしい気もする。
なんかよくわからないのは、「2語まで候補を絞る」というプロセスが 上手く表現できてないからか。例えば、候補が2語になるのがなぜか正解 が知っている単語であるときだけなら、知っている単語が正解であるのは自明 である。
例えば、2語選ぶのが、「正解は必ず通す、もう1語ランダムに選ばれた何 かも通しちゃう」というフィルタで2語選ぶことだとする。
これだと、正解ともう一方は対称的なので、正解を知っていてもう一方を 知らない、という事象とその逆は同じ確率で起こるので、正解が知っている単 語である確率は 1/2 になるような気がするが、これは直観に反する。
あれれ?みたいな。
弱形式の導出自体が元の関数が2回微分可能と仮定してて、収束条件も「2回微分可能なら」なんだけど、構成された近似解は2回微分可能では別にない。でも実際上はちゃんと高次になる、ということ?
つまり、CIPなんかだと格子点で一階微分の値は1つで、なので一回微分可能なスプライン的な関数が近似関数の空間なんだけど、p法だとその制限は外れているけどちゃんと高次になるの?
なるような気がするけど1次元で書いてみないと分からないかこれ。
{kind=link}