151. 富岳の Top500 3連覇と MN-3 の2度目の Green500 1位から、ポストエクサスケールを考える(2021/7/4)
2021年6月の Top500 は大きな動きはなく、富岳が 2020年6月、11月に続き3連
覇となりました。関係者の皆様おめでとうございます。一応牧野もこれの開発
プロジェクトの副プロジェクトリーダーだったので関係者ではあります。
富岳の1位が長く続いたのは、エクサスケールプロジェクトをもっている米中
どちらも開発が遅れている、ということの現れです。米国は当初は2018年予定
だった Aurora が(この時にはサブエクサでしたが)、Intel KNH のキャンセル
をうけて2021年の予定だったのがさらに Xe が遅れて 2022年以降になる見込
みです。中国はいつまでにといっていませんが、2014年頃には 2018年にも、
という話だったのがとりあえずそうなってはいません。
米中が遅れている理由は色々あると思いますが、技術と運用コストの関係から
みると明らかなのは、電力性能がエクサ超えを実現できるところまできていな
い、ということです。富岳は最大 40MW 近い巨大な電力供給を実現したことで、
15GF/W の電力性能ながらピーク性能 500PF超えを実現しました。しかし、
現行の米中の最大規模のシステムの消費電力はせいぜい15MW であり、1EF
マシンでも30MW を想定はしていないようです。例えば 25MW と
しても、1EFの実現には 40GF/W を達成しなければなりません。
では実際にどの程度の電力性能が実現されているのかは、Green 500 のほうを
みればわかるわけです。2020年6月からの3期、PFN の MN-Core と NVIDIA
A100 が鍔迫り合いを繰り広げていて、2020年6月は MN-Core, 11 月は A100、
今回2021年6月は僅差で MN-Core となりました。
この3回の電力性能は、21.1, 26.2, 29.7 GF/W で、ハードウェアが変わっ
てないのに随分上がっているのでこれからまだもうちょっと上がるかもしれな
いですが、まあ 30GF/W としましょう。そうすると、これらのプロセッサで
そのまま1エクサフロップスのマシン作ったとしても、富岳並みの33MW が必要
ということになります。 25MW に抑えるにはもっと高い電力性能が必要です。
A100 は TSMC の N7 プロセスを使っていて、例えばアップルの M1 プロセッ
サはその次の世代の N5 を使っているわけで、N5 を使えばおそらく A100 の
設計から大きく変えないで 40GF/W が実現できると考えられます。実際に
そうなるかどうかは別にして、リーゾナブルな電力消費で1EFを実
現するにはN5世代が最低線ということです。
まあその、MN-Core はPFNの発表資料にあるように N7 ではなくてその1世代前
の 12FFC なので、N5 までいくと2倍以上電力性能をあげることができる計算
です。また、色々な制約があってHPLの実行効率はまだ低く、こちらでも改善
の余地はあります。ちょっと楽観的かもしれないですが、N5で頑張って設計す
れば HPL で 80GF/W 程度はいけると思います。
とはいえ、80GF/W になったところで 1EF が 2EF になるだけです。富岳完成
から8年後の2028年に、10年で100倍なら富岳の40倍、 20EFを
実現したいわけですが、そんなことは可能でしょうか?
極めて楽観的に、半導体があと3世代変わって、1世代毎に消費電力が 30% 下
がるとします。これはもうCMOS スケーリングからでてくるものではなく、
主に電源電圧を下げることの効果です。そうすると、電力性能は3倍になって、
MN-Core なら 240GF/W、A100延長でも120GF/W までいきます。
それでも、 3-6EF です。
トップ500のページ を見ると、例えば合計性能の上昇が 2013/6 で明らかに折れ曲がってい
て、2013/6 に229PF、2021/6に2.8EF、7年間に12倍で、これは10年間に36倍、
8年なら17.5倍です。それでも8EF は欲しいところで、MN-Core の延長でも
まだちょっと不足です。300GF/W が必要だからです。
日本のコミュニティの活動である NGACI の予測では GPU ベースで 50MW で
18EF で、25MWだと 9EFです。これはピーク性能と思いますが少し楽観的かも
しれません。A100 の延長からさらに3倍電力性能をあげる仕掛けが必要です。
一つの方向は、倍精度演算ではなくて単精度演算の性能で十分高いものを目標
にすることです。単精度なので目標2倍とすると、単精度 600GF/W が目標に
なります。これは実は MN-Core アーキテクチャでは実現可能域で、というの
は半精度の電力性能はMN-Core でも A100 でも倍精度の16倍あり、同様な
回路設計で単精度なら4倍が実現できるはずだからです。つまり、2028年に
単精度なら MN-Core 960GF/W、A100 480GF/Wです。概ね 1TF/W, 500GF/Wです
ね。一方、富岳の 40倍、単精度 40EF を実現するには 1.6TF/W が必要で、
MN-Core アーキテクチャでもまだ 1.6倍不足です。A100 だと3倍です。
クロック速度を犠牲にすれば、コア電圧を極限まで下げることでこの程度の電
力消費の低減は実現可能性範囲にはいってくるものと思われます。 TSMC N12e
は正式に 0.4V をサポートします。N7 で典型的と思われる 0.7V に比べると
それだけで 3 倍の電力性能で、0.35までいけば4倍です。もちろん、
シュリンク自体がある程度の電圧低下を想定しているので、
これが全部余計に使えるわけではないですが、1.5倍程度は可能でしょう。
あとは、プロセッサコアのアーキテクチャでどれだけ稼ぐことができるかです。
ここはまだ、演算器だけの電力に比べるとMN-Core でも多分3倍程度なので、
演算器以外を演算の半分程度に減らしたアーキテクチャではさらに2倍で、単
精度 2TF/W が実現できます。
ここまでの議論をまとめると、MN-Core や A100 の延長で考えて、プロセッサ
コアアーキテクチャの改良も考慮すれば、2028年の半導体技術で単精度で
1-2TF/W は実現可能あり、25MW でも 25-50EF、50MW 使うなら 100EF が視野
にはいる、というところになります。
ここで、演算よりデータ移動のほうに電気使うんだからこんなことを考えても
どうにもならないんじゃないか?という意見を検討します。
まず、データ移動のほうに電気が使われる、というのは全くその通りです。
配線1cm のキャパシタンスはオーダーとして 1pF で、これは微細化しても、
線幅とグラウンドプレーンと配線の距離の比が変わらなければ変わりません。
なので、 0.6V で 1cm の線の電位を反転させるのに必要なエネルギーは
なお、実際には、微細化すると配線長当りの抵抗が大きくなるので、RC遅延が
どんどん大きくなります。これを多少とも改善するためには中継ドライバをい
れるわけですがこれにも限界があり、パイプラインレジスタをいれて遅延も電
力消費もどんどん大きくなることになります。これはアプリケーショ
ンの性能にも電力性能にも大きなインパクトがあります。
このことが何を意味するかというと、 HBM にしても GDDRx にしても、いわゆ
る 2.5次元配線、つまり、プロセッサチップとメモリチップを横に並べて、
その間を配線でつなぐアプローチには限界があるし、さらにいうとそもそも
大きなプロセッサチップの中で演算器とキャッシュメモリの間に物理的に
距離があるような設計も無理になってきている、ということです。
3次元実装でメモリとプロセッサの距離を短くするなら、現在の HBM のように
プロセッサチップの端からシグナルをだすのでは駄目で、プロセッサチップの
上にメモリをのせて、チップ全域にシグナルを分散させることでプロセッサチッ
プ内の横方向のデータ移動を減らす必要があります。これはつまり、
オンチップのメモリはプロセッサコア毎のローカルメモリにならざるを
得ない、ということでもあります。
階層的なキャッシュでは絶対に駄目か、というと難しいですが、少なくとも
現在の典型的なプロセッサで見られるような L1-L2-LLC と下にいくほど
容量が大きくなるものでは電力性能をある程度以上あげるのは困難
です。どうしても LLC に多くのアクセスが発生するからです。
キャッシュを使うとすれば、発想を逆転させた、L1 に主要なデータ
をすべておいて、Stanford DASH やそれに基づいた SGI の分散共有メモリマシ
ンのようなアプローチでコヒーレンシを実現する必要があるでしょう。
実際問題としてはこれも困難で、Sunway SW26010 でとっているような、
あるいは Sony PS3 でとったような、主記憶とは別のアドレス空間
にローカルメモリをもつアプローチが電力性能の観点からは
現実的ということになります。
これは例えば行列乗算を例にしても明らかで、コア間の放送や総和をサポート
することで、階層キャッシュアーキテクチャに比べて長距離のデータ移動を
劇的に減らすことができます。
もちろん、既存のアプリケーションが
そのままでは性能がでない、という問題はあるものの、
SW26010 ではコアグループに1つはキャッシュをもつプロセッサとすることで、
段階的なアプリケーションの移行を可能にしています。
一般論として、演算よりデータ移動のほうに電気が使われるのならば、ソフト
ウェアやアルゴリズムの開発としては演算量を増やしてでもデータ移動を減ら
す方向の開発が重要になります。実際に多くの分野でもう数十年に渡ってその
ような方向の研究開発が進んでいます。これはかなり上手くいっており、その
結果、演算の電力性能が問題になるわけで、演算よりデータ移動のほうに電気
が使われるからこそ、演算の電力性能が今後ますます重要になるのです。
すなわち、これからの方向として、ソフトウェア・アルゴリズムは
演算を増やしてでもデータ移動を減らす方向の研究開発が重要になり、
プロセッサアーキテクチャ、特にメモリ階層アーキテクチャは
それを可能な限りサポートするものにならなければいけません。
その辺の原理的な検討をせずに、現在のアーキテクチャの延長に
将来がある、と考えるのは極めて危険なことです。
原理的には、単精度主体として 2028年には 1-2 TF/W は実現可能であり、
50MW を許すなら 100EFはありえる、ということになるでしょう。倍精度だと
25EF程度ですが、2028年に富岳の50倍ならば素晴らしい性能といえるのでは
ないでしょうか。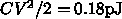 、64ビット2語読んで1語書くのに 96ビット
反転するとすれば17pJ ですから、これだけで 60GF/W に相当する
電力が使われてしまいます。
、64ビット2語読んで1語書くのに 96ビット
反転するとすれば17pJ ですから、これだけで 60GF/W に相当する
電力が使われてしまいます。