117. HPC用プロセッサの近未来(2013/7/13)
過去40年間のマイクロプロセッサの進化が、基本的にはハイエンドのメインフ レームやスーパーコンピューターの進化を後追いするものであったことは 26 で述べました。大雑把にいって、 1993年の Intel Pentium (ないしは、1989年の Intel 80860) で、完全にパイプライン化された浮動小 数点演算器を実現していて、これが 1976 年の Cray-1 に相当します。但し、 90年代初期から 26 を書いた2006年までのほぼ15年間の進化は、 ベクトルマシンの1976 年からの15年間の進化とは大きく違った、ということ も述べました。ベクトル機のクロック速度は15年間に数倍にしかならなかった のに対して、マイクロプロセッサのクロックは 75 倍にもなったからです。
大雑把にいって、この間にトランジスタ数は 500倍、演算器の数は4倍、性能 は300倍、というところでした。
ベクトル機はこの15年間にどうなったかというと、共有メモリベクトル機では 16プロセッサのC-90, 4 プロセッサ、4パイプラインの NEC SX-3 や Hitach S-3800 辺りの演算器32個で頭打ちになりました。これは、結局、多数の演算器 が共有メモリに並列アクセスするものを作るのは、メモリと演算器間のネット ワークに莫大なコストがかかるからです。もちろん、NEC はSX-3 のあと、 2008年の SX-9 までさらに15年間共有メモリマシンの開発をつづけてきました が、コア数としては 16 程度、演算器数で512にとどまる上に、価格競争力があ るとはいいがたいものでした。
マイクロプロセッサでは、同じ15年間を、CMOS スケーリングと深いパイプラ イン化でクロックをあげる、ということに費やした、ということになります。 実際には、2003年頃にこの方向の限界がきて、動作クロックをあげられなくな り、演算器を増やす方向に舵を切ったわけです。
2013年の現在を見ると、サーバーや HPC 向けではまだでていない IvyBridge-EP が先端として、10コア、8演算で80演算を実行するようになりま した。7年間に10倍以上並列度はあがったわけで、90年代はじめの共有メモリ ベクトル機よりも多数の演算器を集積しています。
何故ここまで演算器を増やすことができたか、というと、一つには、キャッシュ に頼ることでオフチップのメモリバンド幅を相対的に落としてきたこと、もう 一つは、実際問題として実用アプリケーションのほとんどでは有効に使えてい なくても、それにかまわずに演算器とカタログピーク性能をあげてきたことだ と思います。
とはいえ、その方向で今後もなんとかなるのか、というと、それが極めて難し いことを示しているのが Xeon Phi (Knights Corner) でしょう。16演算のコ アを60個程度集積し、約 1000演算を並列実行するのですが、行列乗算のよう な規則的な処理以外で良い性能がでたという話はなかなか聞こえてきません。
実際問題として Xeon Phi の問題点はプロセス間の同期機構やキャッシュコヒー レンシの維持メカニズムにあり、必ずしもオフチップメモリバンド幅が最大の 問題というわけではないのですが、コア数を増やせなくなった、というのは明 らかです。
GPU ではコア数増やしているではないか、という意見はもちろんあるかと思い ますが、やはり、良い性能がでたという話はなかなか聞こえてきません。
そうすると、この方向でそれでも力任せにコア数を増やすのですが、実際のア プリケーションでの性能は下がり、プログラミングはますます困難になり、と いうのが続くことになりそうです。
さて、ベクトル計算機では、93年に革命が起こったことは 4 で述べた通りです。ここでの革命は、共有メモリを諦め、分散メモリにしつつ も強力なネットワークをつけることで、プログラマーから見ると共有アレイが あるのに近く明示的に通信を書く必要のない VPP-Fortran でのプログラミン グで高い実効性能を出すことを可能にしたことでした。
NEC のベクトル機も早期に共有メモリを諦めるべきだった、というのは 20 に書いたのですが、来年度出荷のマシンでそれに近い 方向になるようです。しかし、10年近くたってやっと、では既に最適解からは 遠いでしょう。
話を戻します。マイクロプロセッサがどうなるべきかです。NWT/VPP500 の方 向を目指すにあたっての問題点は、既にオフチップメモリバンド幅が決定的に 不足していて、さらにピンネックなので、チップの中で NWT のように共有メ モリをやめたとしても、オフチップメモリバンド幅は上がらないのであまり解 決にならない、ということでした。
これはかなり深刻な問題で、ある意味マルチコアプロセッサの限界を意味して いるのですが、半導体技術がさらに進むと違う解がでてきます。それは、 オフチップメモリ自体を諦める、ということです。
半導体製造プロセスが 10nm といったところにくると、SRAM のセルサイズは
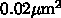 あたりになり、計算上は 1平方ミリあたり 50Mビット、
160平方ミリで 1GB となります。これくらいになれば、もう外付けメモリなん
ていらないのではないか?ということです。
あたりになり、計算上は 1平方ミリあたり 50Mビット、
160平方ミリで 1GB となります。これくらいになれば、もう外付けメモリなん
ていらないのではないか?ということです。
(2013/7/14 追記:富士通の安島さんから、この数字の根拠は?と聞かれたので VLSI Technology 2011 / VLSI Circuits 2011 をリンクしておきます。 IBM が 22nm で 0.08, 10nm で 0.021 um^2/cell を試作レベルですが実現し た、という 2011 年の記事です)
で、もうちょっと追記です。周辺回路も入れるとか、IBM のは試作レベルで 製造プロセスとは違うかも、といったことを考慮すると、 半導体製造プロセスが 10nm でも 1平方ミリあたり 15-20Mビット、1Gバイトには 400平方ミリくらいが現実的なところなようです。というわけで、以下、当初のもの とは若干数字が変わっています。
そもそも、キャパシタンスを必要とする DRAM は微細化の限界にきており、 20nm はみえていますが 10nm まで製造可能かどうかわからないですし、コス トも下がるかどうかわからない、という状況です。元々 SRAM と DRAM の面積 効比は10倍程度以下だったわけで、それがもうあまり大きくならないわけです。
もちろん、規格品を大量生産する DRAM はそれでもおそらく安価ですが、転送 バンド幅や消費電力を考えた時にはかえって不利です。特に、バンド幅では、 オンチップでプロセッサの近くにおけるSRAMは、チップ内部でも分散メモリに するなら事実上無制限のメモリバンド幅が得られます。
まあその、DRAM チップの価格は現在でもすでに恐ろしく安く、 2Gbit 品が1ド ル程度、つまり、1GB が400円です。これに対して、 400平方ミリのロジックチッ プは、例えば 300mm ウェハが200万円として、1万5千から3万円相当程度でしょう。 なので、現在の価格と比べても 10倍以上、10nm が利用可能になる時期では 相対的にもっと高い可能性があります。
一方、並列計算機の1ノードは、何度か述べてきたように50万円程度です。こ の価格には様々な理由があるのですが、おそらく近い将来に大きく変わること はありません。そうすると、これを全部オンチップ SRAM に使うなら 32GB 近くが利用可能、 1/2 としても 16GB となり、かなり大きい、という感じになっ てきます。もちろん、これは5000平方ミリであり、単一チップでは現実的では なく少なくとも 10チップで、1ノード、しかもノード内でも分散メモリ、という構成で すが、ノードあたり 16GB メモリ、演算性能は、消費電力をノードあたり 500W 程度に抑えるなら 50TF というところでしょう。この1ノードだと、 50TF に対して 16GB メモリはちょっと小さ過ぎるのですが、1万チップ程度で 構成して 160TB、500PF となるとそれほど悪くありません。流体計算で 1万の3乗程度が収まる計算になり、1ステップ数千演算、100万ステップとする なら実行効率50%で計算に10時間かかるからです。
外付けチップでメモリバンド幅を増やすのに TSV や 2.5次元実装を、という 話はあり、私も7年前にそっちの方向を議論しています。しかし、TSVはともか く 2.5 次元実装は、製造コストがかなり高い可能性があり、バンド幅あたり ではオンチップメモリに比べて不利です。容量も考えた場合にどうか、がもち ろん問題ではあるのですが、上にみたようにそれほど大容量のメモリが必要で ないならオンチップメモリが有利です。
1チップで流体計算を、という場合には、 B/F で 0.1 程度の外部メモリをつ けるのが現実的でしょう。これは、 2.5D といった高価な技術を使わなくても 利用可能になる可能性が高いです。例えば HMC といった、汎用品側でTSVを使 うものが候補になります。
我々が筑波大学 FS で検討しているのはもうちょっと保守的というか、「加速 機構」的でオンチップのメモリがここまで巨大ではないものですが、その次を 考えると DRAM はおそらく解にならないわけで、オンチップメモリで十分、と なるように思います。