52. ベクトルとスカラ? (2007/7/28)
50 でベクトル機とスカラ機の優劣について論点を整理す る、と書いてみたわけですが、実は、とかいうまでもなくこの文章の前のほう でそんなことは何度も繰り返して議論しています。なので、繰り返しになって しまいますが、ちょっと書いてみましょう。
ベクトルアーキテクチャの基本的な問題点は、それが 30-40年前の半導体技術、 計算機製造技術を想定したもので現在の半導体技術にはむかないものであると いうことです。
いくつかの設計上の選択から、この点を検証してみましょう。まず、 Cray-1 の場合のベクトルレジスタです。Cray-1 は64語のベクトルレジスタを 8 本も ちます。これは 16ビットの容量を持つ IC で構成されたので、1語が4チッ プ、全部で 2048 チップです。これに対して、例えば乗算器は少なくとも2万 ゲート程度必要です。 Cray-1 で使った論理 IC は4ゲート相当程度なので、 少なくとも 5000チップが乗算器に使われています。なお、パッケージピン数 はどちらも 16ピンだったはずです。つまり、回路規模として乗算器だけでベ クトルレジスタの数倍あったわけです。
ところが、現在の集積回路でベクトルレジスタを構成するとサイズはこんなも
のではすみません。レジスタに安直にフリップフロップをつかうと、 1 ビッ
トは 10ゲートにもなるのでそれだけで 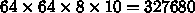 で、32万ゲートにもなり乗算器の 10倍の面積になります。
マルチポートメモリセルで実装すればある程度は小さくなりますが、
乗算器よりも小さくするのは困難です。つまり、 Cray-1 のアーキテクチャで
ベクトルプロセッサを作ると、現在の技術ではチップ上でベクトルレジスタの
ほうが演算器よりもかなり大きくなります。言い換えると、演算器の数を増や
してもチップ面積も消費電力も大して増加しません。
で、32万ゲートにもなり乗算器の 10倍の面積になります。
マルチポートメモリセルで実装すればある程度は小さくなりますが、
乗算器よりも小さくするのは困難です。つまり、 Cray-1 のアーキテクチャで
ベクトルプロセッサを作ると、現在の技術ではチップ上でベクトルレジスタの
ほうが演算器よりもかなり大きくなります。言い換えると、演算器の数を増や
してもチップ面積も消費電力も大して増加しません。
これはに対して、 Cray-1 の時代ではそうではなく、演算器がベクトルレジス タよりも大きかったわけです。このため、 64語 8 本というサイズはハードウェ ア設計として無理がないものといえます。
なお、日本のベクトル機のベクトルレジスタは Cray-1 のものよりはるかに巨 大です。これは、1980年代初めには適切だったのかもしれませんが現在は そうではありません。
次に主記憶です。 Cray-1 のメモリは最初は1kbit チップです。主記憶は 1M 語ですから、7万2千個ものメモリチップを使ったことになります。(メモリは ECC があったようです)メモリアクセスタイムは 50ns で、演算器のクロック の4倍です。 これを 16バンクにすることで十分なデータ転送速度をもたせて います。メモリチップの数からは回路規模を大して増やすことなくもっと バンク数を増やせるしメモリのピーク転送速度も上げることができますが、 必要ないのでしていない、というものです。
チップ数としては乗算器の10倍程度です。まあ、その、メモリが大きいのはしょ うがない、と思うとこんなところでしょう。
まとめると、 Cray-1 では大きなベクトルレジスタと、バンド幅の大きな主記 憶をもたせていますが、これらはコストを上げる要因にはなっていない、とい うことです。主記憶の容量自体はコストに影響していますが、バンド幅はそう ではありません。言い換えると、 Cray-1 の設計は、ベクトルレジスタの大き さや主記憶の転送速度が製造コストを圧迫しないように、という観点でなされ ているのです。
ところが、現在の半導体技術で演算器とベクトルレジスタの大きさ、演算速度 と主記憶の転送速度を Cray-1 と同じ比率にしようとすると、まずベクトルレ ジスタが演算器よりもはるかに大きくなります。主記憶の転送速度はさらに問 題が大きく、 NEC の SX-8R 後継で実現するといわれている 100Gflops 程度 の速度の場合、 Cray-1 並なら 50ギガ語/秒程度、つまり 3.6Tbits/s の転送 速度が必要です。 PCI-Express 並の 2.5Gbits/s の線を使ったとして1500本 となります。これはすでに大変です。が、CPU チップのほうはこれはできるか もしれないとして、DRAM は例えば DDR-2 800 を使うと1モジュール当り 6.4GB/s ですから、少なくとも64モジュールないと転送速度が足りません。 Cray-1 並の実効的バンク多重度にするとさらに4倍の 256 モジュール、DRAM チップの数で 2000個にもなります。
NEC のベクトルプロセッサの場合、元々プロセッサチップのトランジスタの殆 どを演算器以外の何かに使っています。殆どを演算器に使うなら、 45nm プロ セスで 2000個くらいの乗算器を入れるのはそれほど困難ではなく、仮に 2GHz のクロックで動作させれば加算器と合わせて 8Tflops の速度になります。 そうすると必要なメモリバンド幅は上の数字の 80倍になって、メモリチップ が16万個になってしまいます。このような設計は明らかにばかげているので、 違う方向が必要なわけです。
では、スカラプロセッサはどうか、というわけですが、プロセッサチップのト ランジスタの殆どを演算器以外に使っている、というのはベクトルプロセッサ と変わりません。が、キャッシュ等を使うことで演算速度当りのメモリバンド 幅を落としていることと、 Intel x86 のような量産されているプロセッサの 場合にはシステム全体として製造コストが低いこと、さらにはマルチバンクに することを諦めて連続アクセスしかしないことでメモリバンド幅当りのコスト を引き下げていることで、ベクトルプロセッサに比べれば演算性能当りの価格 は大きく下がっているわけです。メモリバンド幅当りの価格も上の2つの要因 のため下がります。1チップでの、パイプライン演算器をもったスカラープロ セッサが可能になったのは 20年ほど前ですから、その時点で上の状況になっ ています。
従って、現在は、あるいは 20年くらい前からそうなわけですが、スカラプロセッ サが伝統的なベクトルプロセッサよりも価格当り演算性能でも価格当りメモリ バンド幅でも有利、という状況になっています。が、別にこれはスカラプロセッ サの機械が最善である、というわけでは全くなく、例えば価格当りの演算性能 を最大にするならもっと違うアプローチがあるし、価格当りのメモリバンド幅 を最大にするのでも、 GPU でやっているようなアプローチもありえるわけで す。
つまり、「ベクトルかスカラか」という議論自体が既に 20年前の半導体技術に 対する議論であり、現在はそんなことを今更議論している場合ではない、という ことです。
もちろん、これは純粋にハードウェアからの議論で、ソフトウェアのことは考 えていません。